
代码
'{"code":"A00185","data":"\\u5bf9\\u4e0d\\u8d77\\uff0c\\u60a8\\u77ed\\u65f6\\u95f4\\u53d1\\u8868\\u535a\\u6587\\u8fc7\\u591a\\uff0c\\u8bf7\\u591a\\u4f11\\u606f\\uff0c\\u6ce8\\u610f\\u8eab\\u4f53\\uff01\\u611f\\u8c22\\u60a8\\u5bf9\\u65b0\\u6d6a\\u535a\\u5ba2\\u7684\\u652f\\u6301\\u548c\\u5173\\u6ce8\\uff01"}'用正则不行,用replace不行,应该是\是属于转义符,不过因为访问的源码中,想把这个替换一下,要怎么处理!?
问题补充:
我是想把\\替换成\ 请问要怎么处理?
错如如下!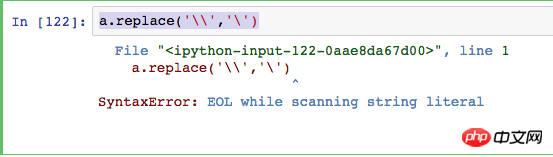
楼下一楼的大哥一直答不对题,我也是比较郁闷.我就想把一个字符串
\\的替换成\
然后想要如下结果:

其他的原理什么的其实我一点也不关心,最好是用一行代码就能回答问题的,万分感谢!

怪我咯2017-04-18 09:16:00
轉移字元的情況下,\=。
樓主說不行,我還專門測試了一下。
a = '{"code":"A00185","data":"\u5bf9\u4e0d\u8d77\uff0c\u60a8\u77ed\u65f6\u95f4\u53d1\u8868\u535a\u6587\u8fc7\u591a\uff0c\u8bf7\u591a\u4f11\u606f\uff0c\u6ce8\u610f\u8eab\u4f53\uff01\u611f\u8c22\u60a8\u5bf9\u65b0\u6d6a\u535a\u5ba2\u7684\u652f\u6301\u548c\u5173\u6ce8\uff01"}'
b = a.replace('\','hehehehe')
print(b);結果是
{"code":"A00185","data":"heheheheu5bf9heheheheu4e0dheheheheu8d77heheheheuff0cheheheheu60a8heheheheu77edheheheheu65f6heh
heheu95f4heheheheu53d1heheheheu8868heheheheu535aheheheheu6587heheheheu8fc7heheheheu591aheheheheuff0cheheheheu8bf7hehehe
eu591aheheheheu4f11heheheheu606fheheheheuff0cheheheheu6ce8heheheheu610fheheheheu8eabheheheheu4f53heheheheuff01heheheheu
11fheheheheu8c22heheheheu60a8heheheheu5bf9heheheheu65b0heheheheu6d6aheheheheu535aheheheheu5ba2heheheheu7684heheheheu652
heheheheu6301heheheheu548cheheheheu5173heheheheu6ce8heheheheuff01"}看到樓主新帖的程式碼片段,再更一下,樓主沒看到代碼提示都變紅了?
a.replace('\','\')這句本來就是錯誤的寫法,因為'转义将一个右引号转义了之后,第二个字符串就不完整了,当然会报错。
另外,按照题主的要求,本来就不需要替换,因为这个字符串本来就是一个,在定义字符串的时候,写两个\,才等于真正的一个。
可以用以下程式碼驗證:
a = '{"code":"A00185","data":"\u5bf9\u4e0d\u8d77\uff0c\u60a8\u77ed\u65f6\u95f4\u53d1\u8868\u535a\u6587\u8fc7\u591a\uff0c\u8bf7\u591a\u4f11\u606f\uff0c\u6ce8\u610f\u8eab\u4f53\uff01\u611f\u8c22\u60a8\u5bf9\u65b0\u6d6a\u535a\u5ba2\u7684\u652f\u6301\u548c\u5173\u6ce8\uff01"}'
print(a);輸出結果
{"code":"A00185","data":"\u5bf9\u4e0d\u8d77\uff0c\u60a8\u77ed\u65f6\u95f4\u53d1\u8868\u535a\u6587\u8fc7\u591a\uff0c\u8bf
7\u591a\u4f11\u606f\uff0c\u6ce8\u610f\u8eab\u4f53\uff01\u611f\u8c22\u60a8\u5bf9\u65b0\u6d6a\u535a\u5ba2\u7684\u652f\u630
1\u548c\u5173\u6ce8\uff01"}幾番交涉,終於知道了題主的目的,就是想解析出json中的中文而已。 。 。
很簡單
import json
a = '{"code":"A00185","data":"\u5bf9\u4e0d\u8d77\uff0c\u60a8\u77ed\u65f6\u95f4\u53d1\u8868\u535a\u6587\u8fc7\u591a\uff0c\u8bf7\u591a\u4f11\u606f\uff0c\u6ce8\u610f\u8eab\u4f53\uff01\u611f\u8c22\u60a8\u5bf9\u65b0\u6d6a\u535a\u5ba2\u7684\u652f\u6301\u548c\u5173\u6ce8\uff01"}'
js = json.loads(a)
print (js)輸出
{'data': '对不起,您短时间发表博文过多,请多休息,注意身体!感谢您对新浪博客的支持和关注!', 'code': 'A00185'}