
最近想提取出特定的URL,遇到问题为预期提取出URL中带有webshell或者phpinfo字段的URL,但是全部URL都匹配出来了:
for url in urls:
if "webshell" or "phpinfo" in url:
print url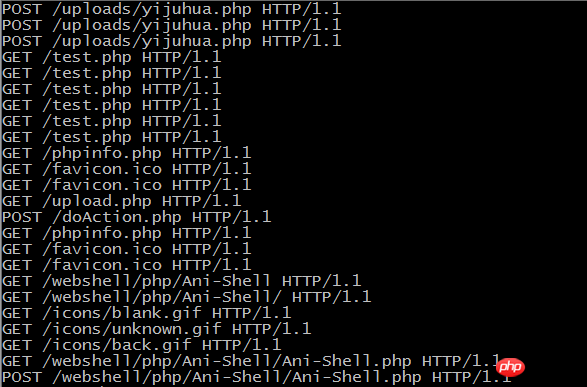
改成and语句也不符合预期,只提取出了含有phpinfo的url:
for url in urls:
if "webshell" and "phpinfo" in url:
print url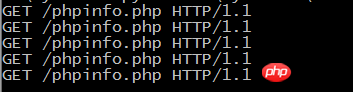

ringa_lee2017-04-18 09:07:15
for url in urls:
if "webshell" in url or "phpinfo" in url:
print url
這樣才可以, 你原來的是先判斷"webshell",如果不為零再判斷"phpinfo" in url. "webshell" 和 "phpinfo" in url並列...

天蓬老师2017-04-18 09:07:15
if "webshell" or "phpinfo" in url:這樣做的意思是 if "webshell" or if "phpinfo" in url 而前者恆成立。
if "webshell" and "phpinfo" in url:這樣做的意思是 if "phpinfo" in url 因為 if "webshell" 恆成立。
解法基本上如 @洛克 所說:
for url in urls:
if "webshell" in url or "phpinfo" in url:
print url 如果今天用來匹配的 word 很多的話:
urls = [
'https://www.example.com/aaa',
'https://www.example.com/bbb',
'https://www.example.com/ccc',
]
def urlcontain(url, lst):
return any(seg for seg in url.split('/') if seg and seg in lst)
for url in urls:
if urlcontain(url, ['aaa', 'bbb']):
print(url)結果:
https://www.example.com/aaa
https://www.example.com/bbburlcontain(url, lst) 可以問 url 裡面是不是有 lst 裡面的任何一個 string
這樣子要比對十個關鍵字也不會寫出太長的 if 述句。
當然要用 re 也可以,只是我個人不太喜歡 re 就是了...
我回答過的問題: Python-QA
