
昨天用 pyspider 采集 汽车之家网 的 汽车详情页数据,因为他一条记录是table 中的某一列,所以需要用到遍历td,索引取当前列。找了半天 没实现jq的 .index() 方法。只找到map 方法。
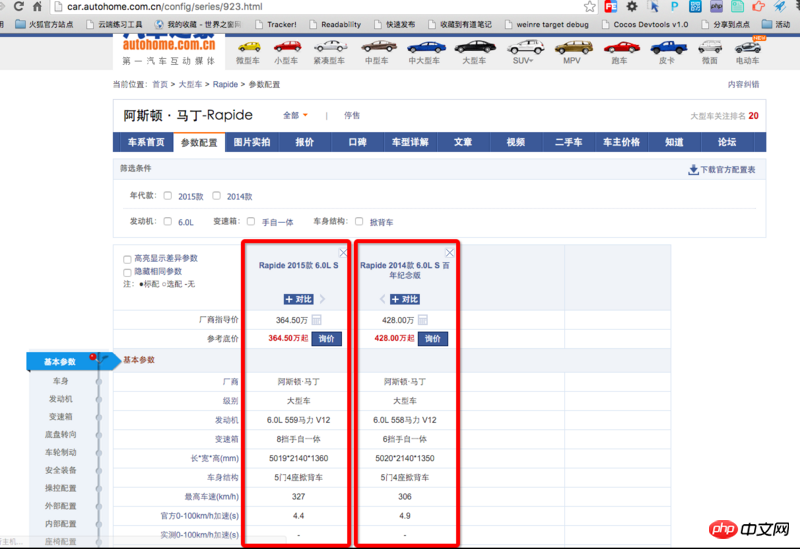
就用map 写了属性的拼装。
代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2015-12-27 14:58:45
# Project: goods2
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.autohome.com.cn/car/?pvareaid=101452', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('.find-letter-list li a').items():
self.crawl('http://www.autohome.com.cn/grade/carhtml/'+each.text()+'.html', callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
for each in response.doc('.rank-list-ul li[id] h4 a').items():
self.crawl(each.attr.href, callback=self.jump_page, fetch_type='js')
@config(priority=2)
def jump_page(self, response):
self.crawl(response.doc('#navTop a:contains("'+u'参数配置'+'")').attr.href, callback=self.deep_page, fetch_type='js')
def deep_page(self, response):
return response.doc('.tbset tr:eq(0) td').filter(lambda i: response.doc(this).find('.btn_delbar').length).map(lambda i, e: {
'goods_name': response.doc(e).find('.carbox p a').text(),
'brand_name': response.doc('#tr_0 td').eq(i).text(),
'c_name': response.doc('.subnav-title-name a').text().split('-')[0],
's_name': response.doc('.subnav-title-name a').text().split('-')[1],
'goods_sn': '',
'goods_name_style':'+',
'click_count': 0,
'provider_name': '',
'goods_number': 100,
'goods_weight': 0,
'market_price': response.doc('#tr_2000 td').eq(i).text(), #待处理成float 元为单位
'shop_price': response.doc('#tr_2001 td').eq(i).find('.pircecont').text(), #待处理成float 元为单位
'warn_number': 1,
'goods_desc': u'0.0升 '+ response.doc('#tr_30 td').eq(i).text()+' '+ response.doc('#tr_38 td').eq(i).text()+u'马力 '+ "\n" + response.doc('#tr_53 td').eq(i).text() + ' '+ response.doc('#tr_3 td').eq(i).text(),
'is_real':1,
'is_alone_sale':1, #1-普通 0-赠品
'sort_order':100,
'goods_type':1,
'attributes':
[
{
'attr_name': each('th').text(),
'attr_value': each('td').eq(i).find('a').attr.title if (each.attr.id == 'tr_2003' or each.attr.id == 'tr_2004')
else each('td').eq(i).text()
,
} for each in response.doc('tr[id^="tr_"]').items()
]
})开始不知道什么原因,后来群里 自由人帮我调试出问题, 返回值不对,小弟python自学的,求作者指点。我去看看群里教程视频了。先把返回 改为table 字符串没解决就用php去解析了。

高洛峰2017-04-17 16:49:55
後來找到原因:
一個頁面的多條數據,用 send_message處理,
pyspider pip裝的不是最新版,去github下載
pyquery response.doc的 回傳物件的 map 慎用,用 for i, e in enumerate
最後修改的腳本:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.autohome.com.cn/car/?pvareaid=101452', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('.find-letter-list li a').items():
self.crawl('http://www.autohome.com.cn/grade/carhtml/'+each.text()+'.html', callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
for each in response.doc('.rank-list-ul li[id] h4 a').filter(lambda i: response.doc(this).not_('.greylink').length).items():
self.crawl(each.attr.href, callback=self.jump_page, fetch_type='js')
@config(priority=2)
def jump_page(self, response):
self.crawl(response.doc('#navTop a:contains("'+u'参数配置'+'")').attr.href, callback=self.deep_page, fetch_type='js')
def deep_page(self, response):
tds = response.doc('.tbset tr:eq(0) td').filter(lambda i: response.doc(this).find('.btn_delbar').length)
for i, e in enumerate(tds.items()):
self.send_message(self.project_name, {
'url': response.url,
'goods_name': response.doc(e).find('.carbox p a').text(),
'brand_name': response.doc('#tr_0 td').eq(i).text(),
'c_name': response.doc('.subnav-title-name a').text().split('-')[0],
's_name': response.doc('.subnav-title-name a').text().split('-')[1],
'goods_sn': '',
'goods_name_style':'+',
'click_count': 0,
'provider_name': '',
'goods_number': 100,
'goods_weight': 0,
'market_price': response.doc('#tr_2000 td').eq(i).text(), #待处理成float 元为单位
'shop_price': response.doc('#tr_2001 td').eq(i).find('.pircecont').text(), #待处理成float 元为单位
'warn_number': 1,
'goods_desc': u'0.0升 '+ response.doc('#tr_30 td').eq(i).text()+' '+ response.doc('#tr_38 td').eq(i).text()+u'马力 '+ "\n" + response.doc('#tr_53 td').eq(i).text() + ' '+ response.doc('#tr_3 td').eq(i).text(),
'is_real':1,
'is_alone_sale':1, #1-普通 0-赠品
'sort_order':100,
'goods_type':1,
'attributes':
[
{
'attr_name': each('th').text(),
'attr_value': each('td').eq(i).find('a').attr.title if (each.attr.id == 'tr_2003' or each.attr.id == 'tr_2004')
else each('td').eq(i).text()
,
} for each in response.doc('tr[id^="tr_"]').items()
]
}, url="%s#%s" % (response.url, i))
def on_message(self, project, msg):
return msg感謝 pyspider群友 自由人(397340469)
