utf-8 - java utf8 转 gb2312 错误?
直接上代码,方便同学可以复制下来跑跑
try {
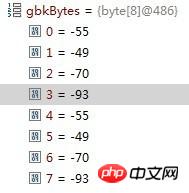
String str = "上海上海";
String gb2312 = new String(str.getBytes("utf-8"), "gb2312");
String utf8 = new String(gb2312.getBytes("gb2312"), "utf-8");
System.out.println(str.equals(utf8));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
结果打印false
jdk7和8下面都是这结果,ide编码是utf-8
跪请大神赐教啊!!!!