
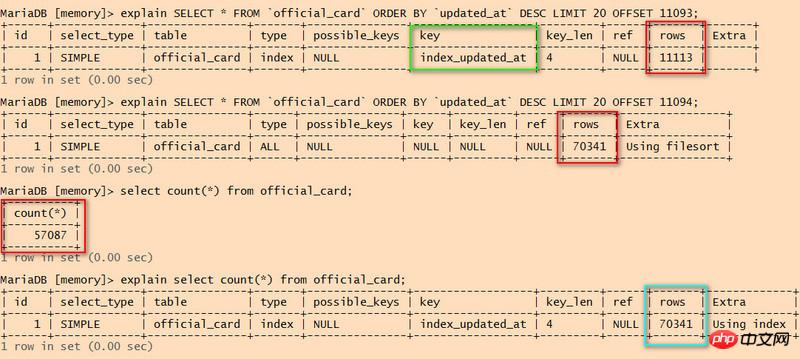
比較前兩條語句,第二條沒有使用索引,我記得是掃描行數達到一定行數時會放棄使用索引,這個臨界值是多少呢?
全表掃描是顯示掃描行數是 70341 行,而資料總行數卻只有 57087 行?
select count(*) 使用了索引,但是也掃描了 70341 行,這個語句會產生效能問題嗎?
滿天的星座2017-06-30 09:54:51
CBO優化機制的資料庫中,沒有明確的使用或不適用索引的臨界值,以執行計劃中的COST最小為標準,經驗值是取表總行數小於5%的時候用索引比較合適。
我理解第二個語句使用的是表的統計數據,如果表最近發生過比較大的變更,統計數據有沒有及時更新,會出現兩者偏差較大的情況。
count(*)使用了索引,說明update_at欄位有NOT NULL的定義,相比較全表掃描,掃描索引的成本會更低一些。