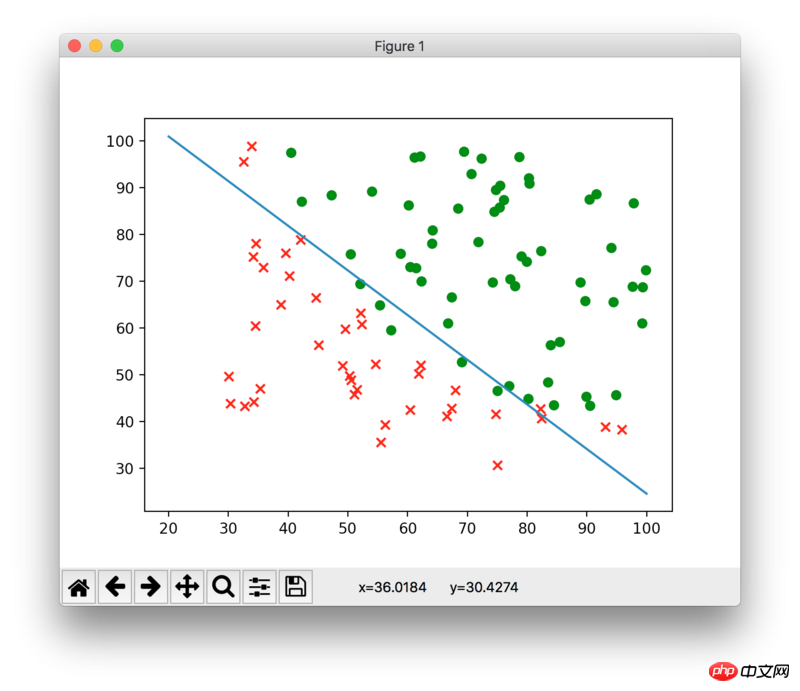
在TensorFlow中,我想建立一個邏輯迴歸模型,代價函數如下:
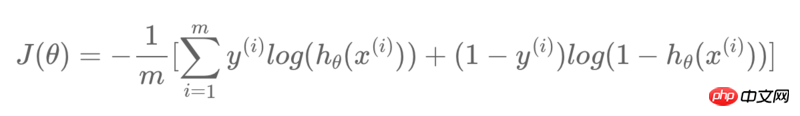
#使用的資料集截圖如下:
#我的程式碼如下:
train_X = train_data[:, :-1]
train_y = train_data[:, -1:]
feature_num = len(train_X[0])
sample_num = len(train_X)
print("Size of train_X: {}x{}".format(sample_num, feature_num))
print("Size of train_y: {}x{}".format(len(train_y), len(train_y[0])))
X = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
W = tf.Variable(tf.zeros([feature_num, 1]))
b = tf.Variable([-.3])
db = tf.matmul(X, tf.reshape(W, [-1, 1])) + b
hyp = tf.sigmoid(db)
cost0 = y * tf.log(hyp)
cost1 = (1 - y) * tf.log(1 - hyp)
cost = (cost0 + cost1) / -sample_num
loss = tf.reduce_sum(cost)
optimizer = tf.train.GradientDescentOptimizer(0.1)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
print(0, sess.run(W).flatten(), sess.run(b).flatten())
sess.run(train, {X: train_X, y: train_y})
print(1, sess.run(W).flatten(), sess.run(b).flatten())
sess.run(train, {X: train_X, y: train_y})
print(2, sess.run(W).flatten(), sess.run(b).flatten())運行結果截圖如下:
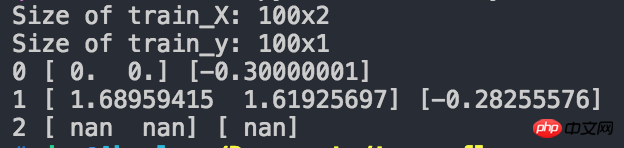
#可以看到,在迭代兩次之後,得到的W和b都變成了nan,請問是哪裡的問題?

大家讲道理2017-06-28 09:25:45
經過一番搜索,找到了問題所在。
在選取迭代方式的那一句:
optimizer = tf.train.GradientDescentOptimizer(0.1)這裡0.1的學習率過大,導致不知什麼原因在損失函數中出現了log(0)的情況,結果導致了損失函數的值為nan,解決方法是減小學習率,例如降到1e-5或1e-6就可以正常訓練了,我依照自己的狀況把學習率調整為了1e-3,程式完美運作。
附上最終擬合結果: