
source_ip = line.split('- -')[0].strip()
if re.match('[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}',source_ip):
if source_ip_dict.get(source_ip,'-')=='-':
source_ip_dict[source_ip]=1
else:
source_ip_dict[source_ip]=source_ip_dict[source_ip]+1透過以上的程式碼把apache的日誌ip提取出來,並且進行統計去重了,
提取的ip資料如下: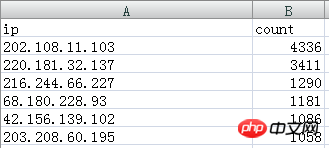
如
202.108.11.103跟220.181.32.137為百度蜘蛛ip
#想要實現的效果如下
這兩個ip命名為百度蜘蛛,然後把他們的統計數據相加即4336 3411
百度蜘蛛7747

黄舟2017-05-18 11:02:19
可以嘗試建構一個大型的以字典為鍵, 爬蟲名字為值的字典;
ip_map = {
'202.108.11.103': 'baidu-spider',
'220'.181.32.137: 'baidu-spider',
'192.168.1.1': 'other'
....
}
sum = {}
for ip in source_ip:
print ip
sum[ip_mapping.get(ip, 'other')] = sum.get(ip, 0) + source_ip[ip]
print sum

阿神2017-05-18 11:02:19
這樣多累!
為什麼不給這個ip分組單獨建立一張表, 名為IPGroup (id, ip, groupname)
| id | ip | groupName |
|---|---|---|
| 1 | 202.108.11.103 | 百度蜘蛛 |
| 2 | 220.181.32.137 | 百度蜘蛛 |
之後一個SQL就搞定了,多麼輕鬆(設樓主用的表明為IPStastics)
SELECT b.groupName, SUM(a.count)
FROM IPStastics a
INNER JOIN IPGroup b
ON a.ip = b.ip
GROUP BY b.groupName