


圖的定義
圖(Graph)是由頂點的有窮非空集合和頂點之間邊的集合組成,通常表示為:G(V,E),其中,G表示一個圖,V是圖G中頂點的集合,E是圖G中邊的集合。
有向圖
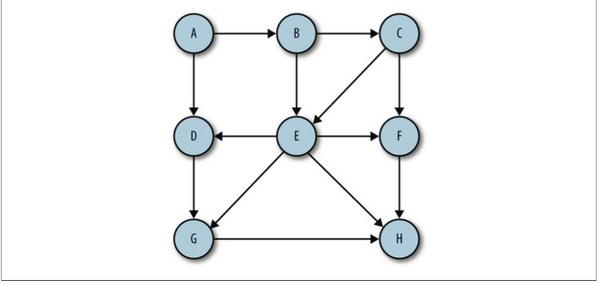
有向邊:若從頂點Vi到Vj的邊有方向,則稱這條邊為有向邊,也成為弧(Arc),用有序偶
無序圖
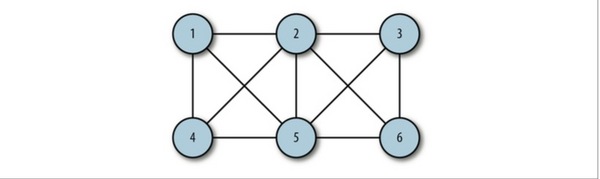
無向邊:若頂點Vi到Vj之間的邊沒有方向,則稱這條邊為無向邊(Edge),用無序偶(Vi,Vj)來表示。
簡單圖
簡單圖:在圖結構中,若不存在頂點到其自身的邊,且同一條邊不重複出現,則稱這樣的圖為簡單圖。
圖類
表示頂點
建立圖類的第一步就是要建立一個Vertex類別來保存頂點和邊。這個類別的作用和鍊錶、二元搜尋樹的Node類別一樣。 Vertex類別有兩個資料成員:一個用來識別頂點,另一個表示是否被存取過的布林值。分別被命名為label和wasVisited。
function Vertex(label){
this.label = label;
}
我們將所有頂點保存在數組中,在圖類裡,可以透過他們在數組中的位置引用他們
表示邊
圖的實際資訊都保存在「邊」上面,因為他們描述了圖的結構。二元樹的一個父節點只能有兩個子節點,而圖的結構卻要靈活得多,一個頂點既可以有一條邊,也可以有多條邊和它相連。
我們將表示圖的邊的方法成為鄰接表或鄰接表數組。它將儲存由頂點的相鄰頂點列表構成的數組
建構圖
定義如下一個Graph類:
function Graph(v){
this.vertices = v;//vertices至高點
this.edges = 0;
this.adj = [];
for(var i =0;I
this.adj[i].push('');
}
this.addEdge = addEdge;
this.toString = toString;
}
這個類別會記錄一個圖表示了多少邊,並使用一個長度與圖的頂點數來記錄頂點的數量。
function addEdge(){
this.adj[v].push(w);
this.adj[w].push(v);
this.edges ;
}
這裡我們使用for迴圈為陣列中的每個元素新增一個子陣列來儲存所有的相鄰頂點,並將所有元素初始化為空字串。
圖的遍歷
深度優先遍歷
深度優先遍歷(DepthFirstSearch),也有稱為深度優先搜索,簡稱DFS。
例如在一個房間內尋找一把鑰匙,無論從哪一間房間開始都可以,將房間內的牆角、床頭櫃、床上、床下、衣櫃、電視櫃等挨個尋找,做到不放過任何一個死角,當所有的抽屜、儲藏櫃中全部都找遍後,接著再尋找下一個房間。
深度優先搜尋:
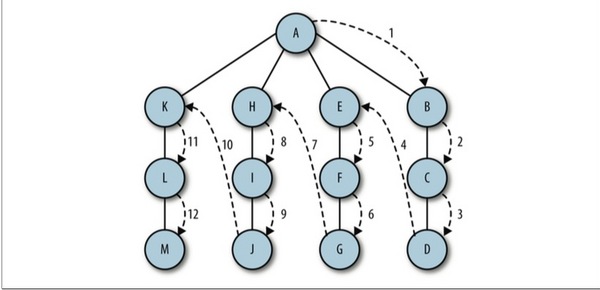
深度優先搜尋就是訪問一個沒有訪問過的頂點,將他標記為已訪問,再遞歸地去訪問在初始頂點的鄰接表中其他沒有訪問過的頂點
為Graph類別新增一個陣列:
this.marked = [];//儲存已造訪過的頂點
for(var i=0;i
}
深度優先搜尋函數:
function dfs(v){
this.marked[v] = true;
//if語句在這裡不是必須的
if(this.adj[v] != undefined){
print("Visited vertex: " v );
for each(var w in this.adj[v]){
if(!this.marked[w]){
this.dfs(w);
}
}
}
}
廣度優先搜尋
廣度優先搜尋(BFS)屬於一種盲目搜尋法,目的是系統地展開並檢查圖中的所有節點,以尋找結果。換句話說,它並不考慮結果的可能位置,徹底搜尋整張圖,直到找到結果為止。
廣度優先搜尋從第一個頂點開始,盡量存取盡可能靠近它的頂點,如下圖所示:
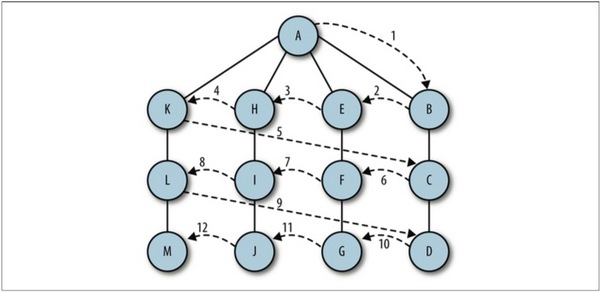
其工作原理為:
1. 首先尋找與目前頂點相鄰的未存取的頂點,將其新增至已存取頂點清單及佇列;
2. 然後從圖中取出下一個頂點v,加入到已訪問的頂點列表
3. 最後將所有與v相鄰的未存取頂點加入佇列
以下是廣度優先搜尋函數的定義:
function bfs(s){
var queue = [];
this.marked = true;
queue.push(s);//加到隊尾
while(queue.length>0){
var v = queue.shift();//從隊首移除
if(v == undefined){
print("Visited vertex: " v);
}
for each(var w in this.adj[v]){
if(!this.marked[w]){
this.edgeTo[w] = v;
this.marked[w] = true;
queue.push(w);
}
}
}
}
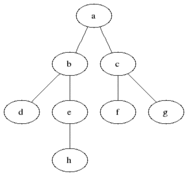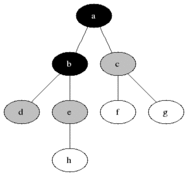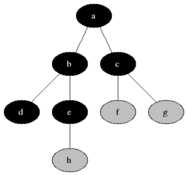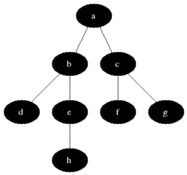
最短路徑
執行廣度優先搜尋時,會自動尋找從一個頂點到另一個相連頂點的最短路徑
確定路徑
要找出最短路徑,需要修改廣度優先搜尋演算法來記錄從一個頂點到另一個頂點的路徑,我們需要一個陣列來保存從一個頂點操下一個頂點的所有邊,我們將這個陣列命名為edgeTo
this.edgeTo = [];//將這行加入Graph類別
//bfs函數
function bfs(s){
var queue = [];
this.marked = true;
queue.push(s);//加到隊尾
while(queue.length>0){
var v = queue.shift();//從隊首移除
if(v == undefined){
print("Visited vertex: " v);
}
for each(var w in this.adj[v]){
if(!this.marked[w]){
this.edgeTo[w] = v;
this.marked[w] = true;
queue.push(w);
}
}
}
}
拓樸排序演算法
拓樸排序會對有向圖的所有頂點進行排序,使有向邊從前面的頂點指向後面的頂點。
拓樸排序演算法與BFS類似,不同的是,拓樸排序演算法不會立即輸出已存取的頂點,而是存取目前頂點鄰接表中的所有相鄰頂點,直到這個清單窮盡時,才會將目前頂點壓入棧中。
拓樸排序演算法被分割為兩個函數,第一個函數是topSort(),用來設定排序程序並呼叫一個輔助函數topSortHelper(),然後顯示排序好的頂點列表
拓撲排序演算法主要工作是在遞歸函數topSortHelper()中完成的,這個函數會將當前頂點標記為已訪問,然後遞歸訪問當前頂點鄰接表中的每個頂點,標記這些頂點為已訪問。最後,將目前頂點壓入堆疊中。
//topSort()函數
function topSort(){
var stack = [];
var visited = [];
for(var i =0;i
}
for(var i = 0;i
this.topSortHelper(i,visited,stack);
}
}
for(var i = 0;i
print(this.vertexList[stack[i]]);
}
}
}
//topSortHelper()函數
function topSortHelper(v,visited,stack){
visited[v] = true;
for each(var w in this.adj[v]){
if(!visited[w]){
this.topSortHelper(visited[w],visited,stack);
}
}
stack.push(v);
}

 JavaScript在行動中:現實世界中的示例和項目Apr 19, 2025 am 12:13 AM
JavaScript在行動中:現實世界中的示例和項目Apr 19, 2025 am 12:13 AMJavaScript在現實世界中的應用包括前端和後端開發。 1)通過構建TODO列表應用展示前端應用,涉及DOM操作和事件處理。 2)通過Node.js和Express構建RESTfulAPI展示後端應用。
 JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AM
JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AMJavaScript在Web開發中的主要用途包括客戶端交互、表單驗證和異步通信。 1)通過DOM操作實現動態內容更新和用戶交互;2)在用戶提交數據前進行客戶端驗證,提高用戶體驗;3)通過AJAX技術實現與服務器的無刷新通信。
 了解JavaScript引擎:實施詳細信息Apr 17, 2025 am 12:05 AM
了解JavaScript引擎:實施詳細信息Apr 17, 2025 am 12:05 AM理解JavaScript引擎內部工作原理對開發者重要,因為它能幫助編寫更高效的代碼並理解性能瓶頸和優化策略。 1)引擎的工作流程包括解析、編譯和執行三個階段;2)執行過程中,引擎會進行動態優化,如內聯緩存和隱藏類;3)最佳實踐包括避免全局變量、優化循環、使用const和let,以及避免過度使用閉包。
 Python vs. JavaScript:學習曲線和易用性Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性Apr 16, 2025 am 12:12 AMPython更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 Python vs. JavaScript:社區,圖書館和資源Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源Apr 15, 2025 am 12:16 AMPython和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。
 從C/C到JavaScript:所有工作方式Apr 14, 2025 am 12:05 AM
從C/C到JavaScript:所有工作方式Apr 14, 2025 am 12:05 AM從C/C 轉向JavaScript需要適應動態類型、垃圾回收和異步編程等特點。 1)C/C 是靜態類型語言,需手動管理內存,而JavaScript是動態類型,垃圾回收自動處理。 2)C/C 需編譯成機器碼,JavaScript則為解釋型語言。 3)JavaScript引入閉包、原型鍊和Promise等概念,增強了靈活性和異步編程能力。
 JavaScript引擎:比較實施Apr 13, 2025 am 12:05 AM
JavaScript引擎:比較實施Apr 13, 2025 am 12:05 AM不同JavaScript引擎在解析和執行JavaScript代碼時,效果會有所不同,因為每個引擎的實現原理和優化策略各有差異。 1.詞法分析:將源碼轉換為詞法單元。 2.語法分析:生成抽象語法樹。 3.優化和編譯:通過JIT編譯器生成機器碼。 4.執行:運行機器碼。 V8引擎通過即時編譯和隱藏類優化,SpiderMonkey使用類型推斷系統,導致在相同代碼上的性能表現不同。
 超越瀏覽器:現實世界中的JavaScriptApr 12, 2025 am 12:06 AM
超越瀏覽器:現實世界中的JavaScriptApr 12, 2025 am 12:06 AMJavaScript在現實世界中的應用包括服務器端編程、移動應用開發和物聯網控制:1.通過Node.js實現服務器端編程,適用於高並發請求處理。 2.通過ReactNative進行移動應用開發,支持跨平台部署。 3.通過Johnny-Five庫用於物聯網設備控制,適用於硬件交互。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

SublimeText3 Linux新版
SublimeText3 Linux最新版

SublimeText3漢化版
中文版,非常好用

Atom編輯器mac版下載
最受歡迎的的開源編輯器

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

