AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
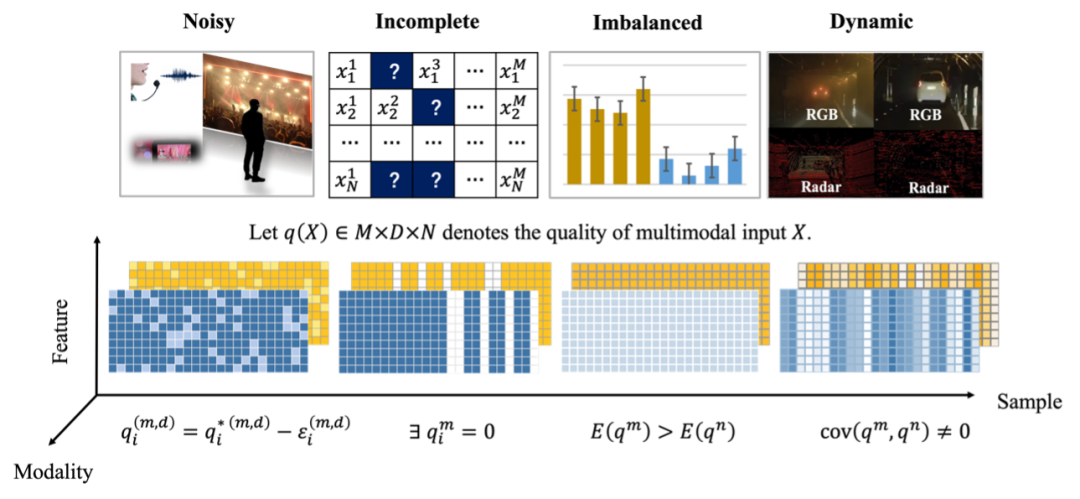
多模態融合的動機在於共同利用來自不同模態的有效資訊提升下游任務的準確性和穩定性。傳統的多模態融合方法往往依賴高品質數據,難以適應現實應用中的複雜低質的多模態數據。 由天津大學、中國人民大學、新加坡科技研究局、四川大學、西安電子科技大學、哈爾濱工業大學(深圳)共同發表的低質多模態資料融合綜述《Multimodal Fusion on Low-quality Data:A Comprehensive Survey》從統一視角介紹了多模態資料的融合挑戰,並針對低質多模態資料的現有融合方式及該領域潛在的發展方向進行了梳理。 http://arxiv.org/abs/2404.18947https://github.com/QingyangZhang/awesome-low-quality-multimodal-learning即使某些模態的訊號不可靠時,人類也具備處理這些低品質多模態資料訊號並感知環境的能力。 儘管多模態學習已取得了長足的發展,多模態機器學習模型仍缺乏有效融合真實世界中低品質多模態資料的能力。在實務經驗中,傳統多模態融合模型的效能在以下場景下會顯著下降:(1)雜訊多模態資料 :部分模態的某些特徵受噪音擾動而失去了原有的訊息。在真實世界中,未知的環境因素、感測器故障、訊號在傳輸過程中的遺失都可能引入雜訊的干擾,進而損害多模態融合模型的可靠性。 (2)缺失多模態資料:由於各種現實因素,實際收集到的多模態資料樣本的某些模態可能存在缺失。例如在醫學領域,病人的各項生理檢查結果所構成的多模態資料可能有嚴重的缺失現象,某些病人可能從未做過某項檢查。 (3)不平衡多模態資料:由於模態之間的異質編碼屬性和資訊品質差異存在不一致的現象,進而導致模態間學習不平衡問題的出現。在多模態融合過程中,模型可能過度依賴某些模態,而忽略其他模態所包含的潛在有效資訊。 (4)動態低質的多模態資料:由於應用環境的複雜多變,不同樣本、不同時空,模態質量具有動態變化特性。低質模態資料的出現往往難以事先預知,這為多模態融合帶來了挑戰。 為了充分刻畫低品質多模態資料的性質及處理方法,該文章對目前的低品質多模態融合領域的機器學習方法進行了總結,系統性回顧了該領域的發展過程,並進一步展望了需進一步研究的問題。 圖 1.中低品質多模態資料分類圖,黃色和藍色表示中呈現兩個模態,顏色說明。這類噪音可能是由於感測器誤差(如醫療診斷中的儀器誤差)、環境因素(如自動駕駛中的雨霧天氣)等因素導致,噪音局限於某個特定的模態內部的某些特徵層面上。
(2)語意層級的跨模態雜訊。這類雜訊是由模態之間高層語意的不對齊現象導致,相較於特徵層的多模態雜訊較難處理。幸運的是,由於多模態資料模態之間的互補性和資訊的冗餘性,在多模態融合過程中,聯合多個模態的資訊進行去噪已被證明是行之有效的策略。
特徵等級的多模態去雜訊方法高度依賴於實際任務中所涉及到的具體模態。 本文主要以多模態影像融合任務為例進行說明。在多模態影像融合中,主流的去雜訊方法包括加權融合及聯合變分兩大類。
考慮到特徵雜訊具有隨機性而真實資料服從特定分佈,進而透過加權求和的方式消除雜訊的影響;
則是對傳統單模態影像變分去噪的拓展,能夠將去噪過程轉換為最佳化問題的求解過程,並利用來自多個模態的互補性資訊來提升去噪效果。語意層級的跨模態雜訊由弱對齊或不對齊的多模態樣本對導致。
例如,在聯合RGB和熱感影像的多模態目標偵測任務中,由於感測器的差異,儘管同一個目標在兩個模態中都有出現,但是其精準的位置和姿態在不同的模態中可能略有不同(弱對齊),為精準估計位置資訊帶來了挑戰。
在社群媒體的內容理解任務中,一個樣本(例如一條微博)的圖像和文字模態所包含的語意訊息可能相差甚遠,甚至毫不相干(完全不對齊),這進一步為多模態融合帶來更大的挑戰。處理跨模態語意雜訊的方式包括規則過濾、模型過濾、雜訊穩健的模型正規化等方法。
#儘管對資料雜訊的處理早已在經典機器學習任務中得到了廣泛的研究,但在多模態場景下,如何聯合利用模態之間的互補性和一致性以弱化噪聲的影響依然是一個亟待解決的研究問題。
此外,與傳統的特徵層級的去噪不同,如何在多模態大模型的預訓練和推斷過程中解決語義層級的噪音是有趣且極富挑戰性的問題。
#問題定義:
##在真實場景下所收集的多模態資料往往是不完整的,由於儲存設備損壞、資料傳輸過程的不可靠等各種因素,多模態資料時常不可避免的遺失掉部分模態的資訊。
例如:在推薦系統中,使用者的瀏覽記錄和信用等級等構成了多模態的數據,然而,由於權限和隱私問題,往往無法完全收集到使用者所有模態的資訊來建構多模態學習系統。
在醫療診斷中,由於某些醫院的設備有限、特定的檢查成本較高,不同的病人的多模態診斷數據往往也是高度不完整的。 #依照「是否需要明確的對缺失多模態資料進行補全」的分類原則,缺失多模態資料融合方法可分為:
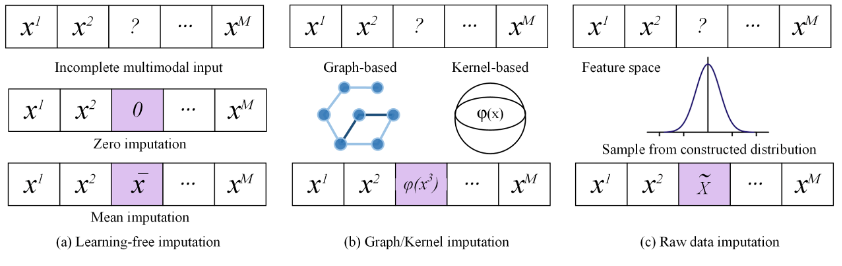
(1)基於補全的多模態融合方法
基於補全的多模態融合方法包括模型無關的補全方法:例如直接透過缺失模態填入0值或殘餘模態的平均值的補全方法;
基於圖或核的補全方法:這類方法不直接學習如何補全原始多模態數據,而是為每個模態構造圖或核,進而學習樣本對之間的相似度或關聯度信息,進而對缺失資料進行補全;
直接在原始特徵層級進行補全:部分方法利用生成模型,如生成對抗網路GAN及其變體直接補全缺失的特徵。
(2)無須補全的多模態融合方法。  與基於補全的方法不同,無需補全的方法重點關注如何利用未缺失的模態所包含的有用信息融合出盡可能好的表徵,這類方法往往對期望學習到的統一表徵添加約束,使得此表徵能夠體現可觀察到的模態數據的完整信息,以繞過補全過程進行多模態融合。
與基於補全的方法不同,無需補全的方法重點關注如何利用未缺失的模態所包含的有用信息融合出盡可能好的表徵,這類方法往往對期望學習到的統一表徵添加約束,使得此表徵能夠體現可觀察到的模態數據的完整信息,以繞過補全過程進行多模態融合。 圖2. 基於補全的缺失多模態數據融合方法分類
儘管目前國內外已提出了許多方法來解決聚類、分類等經典機器學習任務中的不完整多模態資料融合問題,但仍存在一些更深層的挑戰。
例如:關於缺失模態補全方案中的補全資料的品質評估通常被忽略。
###此外,利用先驗缺失資料位置資訊屏蔽缺失模態的策略本身難以彌補模態缺失所帶來的資訊落差和資訊不平衡問題。 ################在多在模態學習中,通常會以聯合訓練的方式整合不同模態資料以提高模型的整體表現和泛化表現。然而,這類廣泛採用的、使用統一學習目標的聯合訓練範式忽略了不同模態資料的異質性。 一方面,不同模態在資料來源及形式方面的異質性,使得它們在收斂速度等方面具有不同的特點,從而使所有模態難以同時得到很好的處理和學習,為多模態聯合學習帶來了困難;另一方面,這種差異也反映在單模態資料的品質上。儘管所有模態都描述了相同的概念,但它們與目標事件或目標對象相關的資訊量卻各不相同。基於最大似然學習目標的深度神經網路具有貪婪學習的特點,導致多模態模型往往依賴具有高判別資訊的、較易學習的高品質模態,而對其他模態資訊建模不足。 為了回應這些挑戰並提高多模態模型的學習質量,平衡多模態學習的相關研究最近得到了廣泛關注。 #依照平衡角度的不同,可將相關方法分為基於特性差異的方法和基於品質差異的方法。 (1)廣泛使用的多模態聯合訓練框架往往忽略了單模態資料固有的學習屬性差異,這可能會對模型的性能產生負面影響。基於特性差異的方法是從每種模態在學習特性上的差異入手,在學習目標、最佳化、架構上嘗試解決這個問題。 (2)最近的研究進一步發現,多模態模型往往嚴重依賴某些高品質資訊模態,而忽略了其他模態,導致對所有模態學習不足。基於品質差異的方法從這個角度入手,從學習目標、最佳化方法、模型架構和資料增強的角度嘗試解決這個問題並促進多模態模型對不同模態的均衡利用。
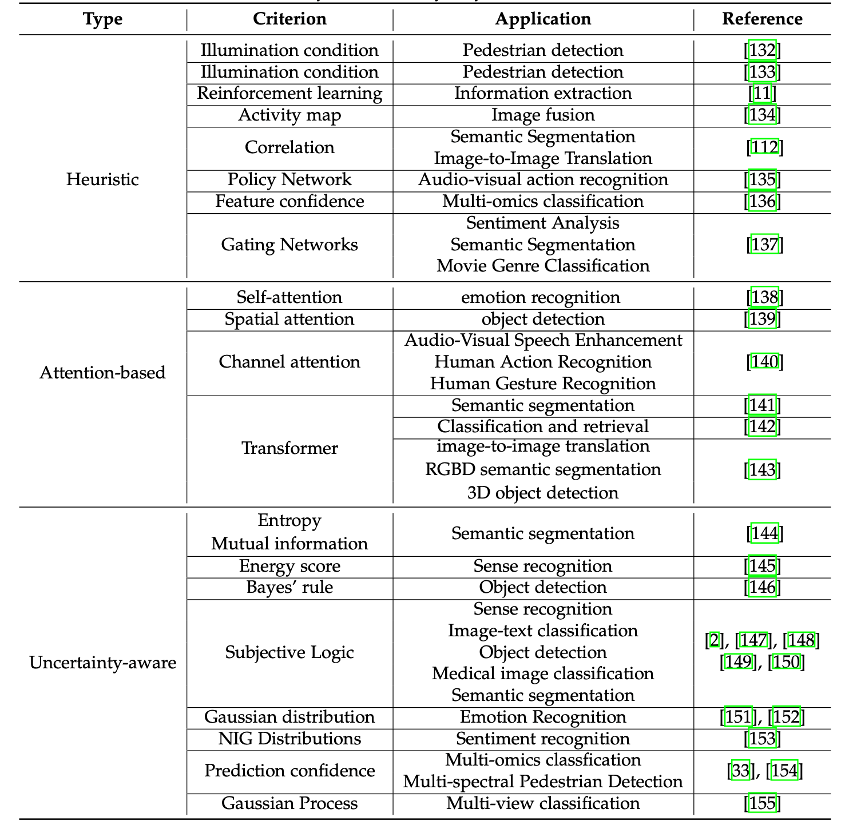
#平衡多模態學習方法主要針對多模態資料的異質性所導致的不同模態間學習特性或資料品質上的差異。這些方法從學習目標、最佳化方法、模型架構和資料增強等不同角度提出了解決方案。 平衡多模態學習目前是一個蓬勃發展的領域,有很多理論和應用方向還沒有充分探索。例如,目前的方法主要局限於典型的多模態任務,其大多是判別性任務和少數生成性任務。 除此以外,多模態大模型也需要聯合具有不同質量的模態數據,也存在這種客觀上的不平衡問題,據此期望在多模態大模型場景中擴展現有研究或設計新的解決方案。 動態多模態資料指的是模態的品質隨輸入樣本、場景的不同而動態改變。例如自動駕駛場景中,系統透過RGB和紅外線感測器獲取路面和目標訊息,在光照較好的情況下,RGB攝影機由於能夠捕捉目標的豐富紋理和色彩訊息,可以更好地支援智慧系統的決策;然而在光照不足的夜間,紅外線感測器提供的感知資訊則更為可靠。如何使得模型能夠自動感知到不同模態質量的變化,從而進行精準和穩定的融合,是動態多模態融合方法的核心任務。 啟發式動態融合方法依賴演算法設計者對多模態模型應用場景的理解,一般透過針對性地引入動態融合機制來實現。 例如,在RGB/熱感訊號協同的多模態目標偵測任務中,研究者啟發式地設計了光照感知模組以動態評估輸入影像的光照情況,並基於光照強度動態調節RGB和熱感模態的融合權重進行環境適應。當亮度較高時,主要依賴RGB模態進行決策,反之則主要依賴熱感模態進行決策。 #基於注意力機制的動態融合方法主要聚焦於表示層融合。注意力機製本身就具有動態特性,因此,可以自然地用於多模態動態融合任務。 Self-attention、Spatial attention、Channel attention以及Transformer等多種機制被廣泛用於多模態融合模型的建構。這類方法在任務目標的驅動下自動地學習如何進行動態融合。基於注意力機制的融合,在缺乏顯式或啟發式引導情況下也能夠一定程度上適應動態低品質的多模態資料。 #不確定性感知的動態融合方法往往具有更清晰、可解釋的融合機制。與基於注意力機制的複雜融合模式不同,不確定性感知的動態融合方法依靠對模態的不確定性估計(如證據、能量、熵等)來適應低質量多模態數據。 具體地,不確定性感知能夠用於刻畫輸入資料各個模態的品質變化。當輸入樣本的某個模態品質變低時,模型基於此模態決策的不確定性隨之變高,為後續融合機制設計提供明確指導。此外,相較於啟發式和注意力機制,不確定性感知的動態融合方法可以提供良好的理論保證。#儘管在傳統的多模態融合任務中,不確定性感知的動態融合方法的優越性已經從實驗和理論上得到了證明,但是,在SOTA的多模態模型(不限於融合模型,如CLIP/BLIP等)中,動態性的思想還具有較大挖掘和應用潛力。 此外,具有理論保證的動態融合機制往往侷限於決策層面,如何使得其在表徵層發揮作用也值得思考與探索。 以上是低質多模態資料融合,多家機構聯合出了篇綜述論文的詳細內容。更多資訊請關注PHP中文網其他相關文章!