機器狗在瑜珈球上穩穩噹噹的行走,平衡力那是相當的好:
#各種場景都能拿捏,不管是平坦的人行道、還是充滿挑戰的草坪都能hold 住:
-
論文網址:https://eureka-research.github.io/dr-eureka/assets/dreureka-paper.pdf
- 專案首頁:https://github.com/eureka-research/DrEureka
- 論文標題:DrEureka: Language Model Guided Sim-To-Real Transfer
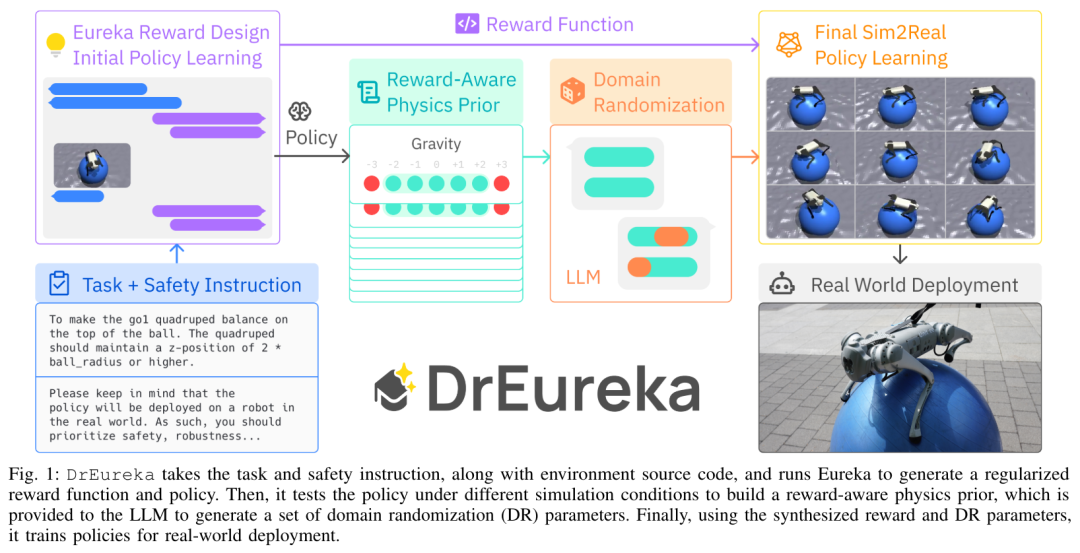
這項研究由賓州大學、 NVIDIA 、德州大學奧斯汀分校的研究者共同打造,並且完全開源。他們提出了 DrEureka(域隨機化 Eureka),這是一種利用 LLM 實現獎勵設計和域隨機化參數配置的新型演算法,可同時實現模擬到現實的遷移。該研究展示了 DrEureka 演算法能夠解決新穎的機器人任務,例如四足機器人平衡和在瑜伽球上行走,而無需迭代手動設計。 在論文摘要部分,研究者表示將在模擬中學習到的策略遷移到現實世界是一種大規模獲取機器人技能的有前途的策略。然而,模擬到現實的方法通常依賴任務獎勵函數以及模擬物理參數的手動設計和調整,這使得過程緩慢且耗費人力。本文研究了使用大型語言模型 (LLM) 來自動化和加速模擬到現實的設計。 論文作者之一、英偉達資深科學家 Jim Fan 也參與了這項研究。先前英偉達成立 AI 實驗室,領隊人就是 Jim Fan,專攻具身智能。 Jim Fan 表示:「我們訓練了一隻機器狗能在瑜珈球上保持平衡並行走,這完全是在模擬中進行的,然後零樣本遷移到現實世界,無需微調,直接運行。可以輕鬆搜尋大量模擬真實配置,並讓機器狗能夠在各種地形上操控球,甚至橫著走!是透過域隨機化實現的,這是一個繁瑣的過程,需要機器人專家盯著每個參數並手動調整。等等,借助GPT-4,DrEureka 可以熟練地調整這些參數並很好地解釋其推理。DrEureka 流程如下所示,其接受任務和安全指令以及環境原始碼,並執行Eureka 以產生正規化的獎勵函數和策略。然後,它在不同的模擬條件下測試該策略以建立獎勵感知物理先驗,並將其提供給 LLM 以產生一組域隨機化 (DR) 參數。最後,使用合成的獎勵和 DR 參數訓練策略以進行實際部署。 Eureka 獎勵設計。獎勵設計組件是基於 Eureka,因為它簡單且具有表現力,但本文引入了一些改進,以增強其在模擬到真實環境中的適用性。偽代碼如下:獎勵感知物理先驗(RAPP,reward aware physics prior)。安全獎勵函數可以規範策略行為以固定環境選擇,但本身不足以實現模擬到現實的遷移。因此本文引入了一個簡單的 RAPP 機制來限制 LLM 的基本範圍。 LLM 用於域隨機化。給定每個 DR 參數的 RAPP 範圍,DrEureka 的最後一步指示 LLM 在 RAPP 範圍的限制內產生域隨機化配置。具體過程請參考圖 3:該研究使用 Unitree Go1 來實驗,Go1 是一個小型四足機器人,四條腿有 12 個自由度。在四足運動任務中,本文也系統性地評估了 DrEureka 策略在幾個現實世界地形上的性能,發現它們仍然具有穩健性,並且優於使用人類設計的獎勵和 DR 配置訓練的策略。 以上是瑜珈球上遛「狗」!入選英偉達十大項目之一的Eureka有了新突破的詳細內容。更多資訊請關注PHP中文網其他相關文章!