
誰說大像不能起舞! 重編程大語言模型實現跨模態交互作用的時序預測 | ICLR 2024

- 王林轉載
- 2024-04-15 15:20:02697瀏覽
近期,來自澳洲蒙納士大學、螞蟻集團、IBM研究院等機構的研究人員探索了模型重編程(model reprogramming)在大語言模型(LLMs)上應用,並提出了一個全新的視角:高效重編程大語言模型進行通用時間序列預測系統,即Time-LLM框架。此框架無需修改語言模型即可實現高精度、高效率的預測,能夠在多個資料集和預測任務中超越傳統的時間序列模型,讓LLMs在處理跨模態的時間序列資料時展現出色表現,如同大象起舞一般。

最近,大語言模型在通用智慧領域的發展,「大模型 時間序列 / 時間資料」這個新方向展現了許多相關進展。目前的LLMs 有潛力徹底改變時間序列 / 時間數據挖掘方式,從而促進城市、能源、交通、健康等經典複雜系統的決策高效制定,並朝著更普適的時間 / 空間分析智能形式邁進。
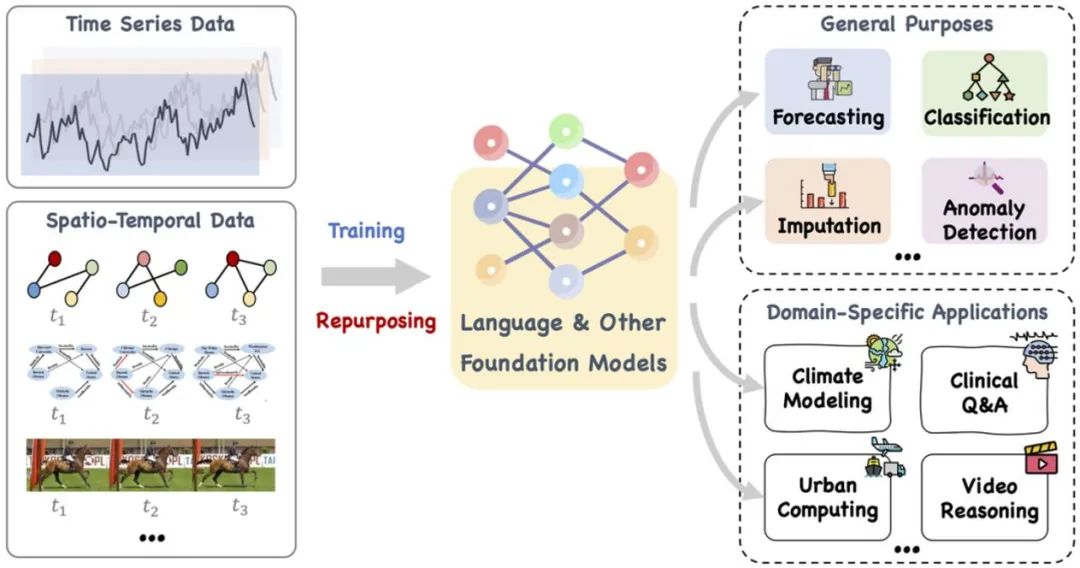
這篇論文提出了一個大型的基礎模型,例如語言和其他相關的模型,可以訓練,也可以巧妙地重新調整其用途,以處理一系列通用任務和專用領域應用的時間序列和時間空間資料。參考文獻:https://arxiv.org/pdf/2310.10196.pdf。
最近的研究將大型語言模型從處理自然語言拓展到時間序列和時空任務領域。這種新的研究方向,即“大模型 時序 / 時空資料”,產生了許多相關進展,例如 LLMTime 直接利用 LLMs 進行零樣本時序預測推理。儘管LLMs 具備強大的學習和表達能力,能夠有效地捕捉文本序列數據中的複雜模式和長期依賴關係,但作為專注於處理自然語言的“黑盒子”,LLMs 在時間序列與時空任務中的應用仍面臨挑戰。相較於傳統的時間序列模型如 TimesNet、TimeMixer 等,LLMs 以其龐大的參數和規模可與「大象」相提並論。
你問的是如何「馴服」這種在自然語言領域訓練的大型語言模型(LLMs),使其能夠處理跨越文本模式的數值型序列數據,在時間序列和時空任務中發揮出強大的推理預測能力,已成為目前研究的關鍵焦點。為此,需要進行更深入的理論分析,以探索語言和時間資料之間潛在的模式相似性,並有效地將其用於特定的時間序列和時空任務。
LLM 重編程模型 (LLM Reprogramming) 是一種通用時序預測技術。它提出了兩項關鍵技術,即(1) 時序輸入重編程和(2) 提示做前編程,將時序預測任務轉換成一個可由LLMs 有效解決的“語言”任務,成功激活了大語言模型做高精度時序推理的能力。

論文網址:https://openreview.net/pdf?id=Unb5CVPtae
論文程式碼:https://github.com/KimMeen/ Time-LLM
1. 問題背景
時序資料在現實中廣泛存儲,在其中時序預測在許多現實世界裡的動態系統中具有非常重要意義,同時也已被廣泛研究。與自然語言處理(NLP)和電腦視覺(CV)不同,其中單一大型模型可以處理多個任務,時序預測模型往往需要專門設計,以滿足不同任務和應用場景的需求。最近的研究表明,大型語言模型(LLMs)在處理複雜的時序序列時也是可靠的,利用大語言模型本身的推理能力處理時序分析任務,仍然是一個挑戰。
2. 論文概述
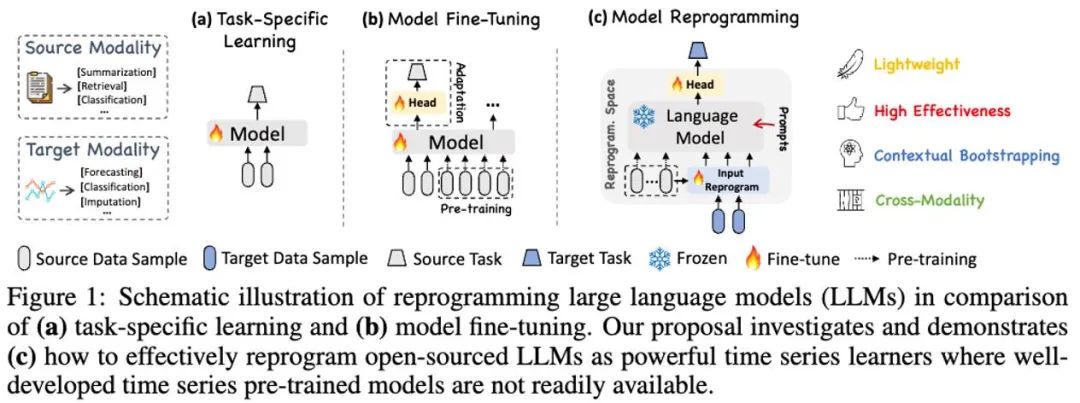
#在這項工作中,作者提出了Time-LLM,它是一個通用的大語言模型重編程(LLM Reprogramming)框架,將LLM 輕鬆用於一般時間序列預測,而無需對大語言模型本身做任何訓練。 Time-LLM 首先使用文字原型(Text Prototypes)對輸入的時序資料進行重編程,透過使用自然語言表徵來表示時序資料的語義訊息,進而對齊兩種不同的資料模態,使大語言模型無需任何修改即可理解另一個數據模態背後的訊息。
為了進一步增強LLM 對輸入時序資料和對應任務的理解,作者提出了提示做前綴(Prompt-as-Prefix,PaP)的範式,透過在時序資料表徵前添加額外的上下文提示與任務指令,充分啟動LLM 在時序任務上的處理能力。在這項工作中,作者在主流的時序基準資料集上進行了充分的實驗,結果表明Time-LLM 能夠在絕大多數情況下超越傳統的時序模型,並在少樣本(Few-shot)與零樣本(Zero-shot)學習任務上獲得了大幅提升。
這項工作中的主要貢獻可以總結如下:
1. 這項工作提出了透過重編程大型語言模型用於時序分析的全新概念,無需對主幹語言模型做任何修改。作者表明時序預測可以被視為另一個可以由現成的 LLM 有效解決的「語言」任務。
2. 這項工作提出了一個通用語言模型重編程框架,即Time-LLM,它包括將輸入時序資料重新編程為更自然的文本原型表示,並透過聲明性提示(例如領域專家知識和任務說明)來增強輸入上下文,以指導LLM 進行有效的跨域推理。此技術為多模態時序基礎模型的發展提供了堅實的基礎。
3. Time-LLM 在主流預測任務中的表現始終超過現有最好的模型效能,尤其在少樣本和零樣本場景中。此外,Time-LLM 在維持出色的模型重編程效率的同時,能夠實現更高的效能。大幅釋放 LLM 在時間序列和其他順序資料方面尚未開發的潛力。
3. 模型框架
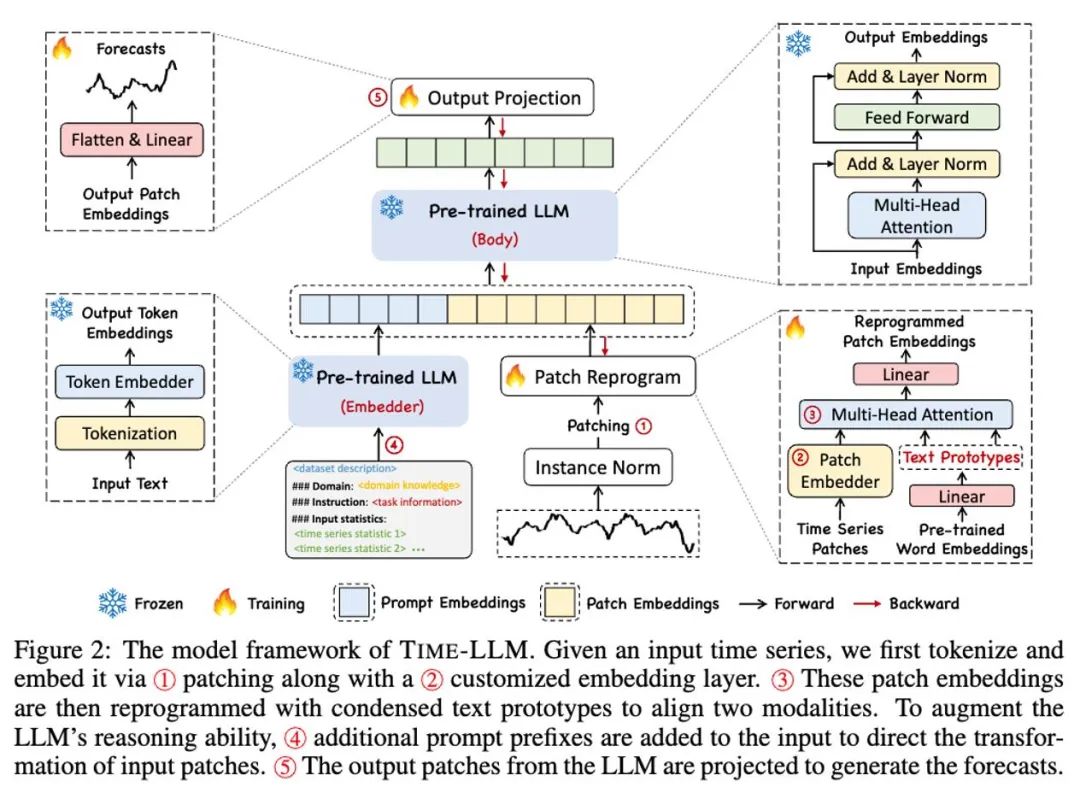
#如上模型框架圖中① 和② 所示,輸入時序資料先透過RevIN 歸一化操作,然後被切分成不同patch 並映射到隱空間。
時序資料和文字資料在表達方式上有顯著差異,兩者屬於不同的模態。時間序列既不能直接編輯,也不能無損地用自然語言描述,這給直接引導(prompting)LLM 理解時間序列帶來了重大挑戰。因此,我們需要將時序輸入特徵對齊到自然語言文字域上。
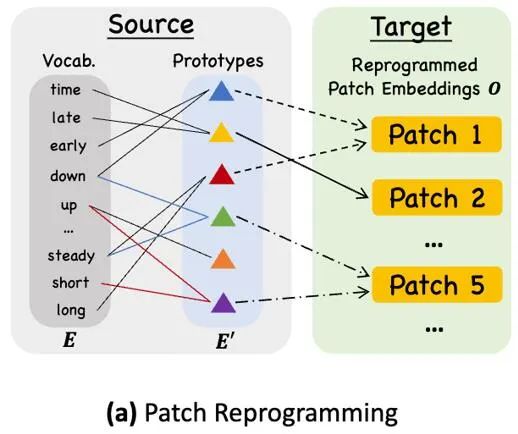
對齊不同模態的一個常見方法就是cross-attention,如模型框架圖中③ 所示,只需要把所有字的embedding 和時序輸入特徵做一個cross-attention(其中時序輸入特徵為Query,所有字的embedding 為Key 和Value)。但是,LLM 固有的詞彙表很大,因此無法有效直接將時序特徵對齊到所有單字上,而且並不是所有單字都和時間序列有對齊的語義關係。為了解決這個問題,這項工作對詞彙表進行了線形組合來獲取文本原型,其中文本原型的數量遠小於原始詞彙量,組合起來可以用於表示時序數據的變化特徵,例如“短暫上升或緩慢下降」,如上圖所示。
為了充分啟動 LLM 在指定時序任務上的能力,這項工作提出了提示做前綴的範式,這是一種簡單且有效的方法,如模型框架圖中 ④ 所示。最近的進展表明,其他資料模式,如影像可以無縫地整合到提示的前綴中,從而基於這些輸入進行有效的推理。受這些發現的啟發,作者為了使他們的方法直接適用於現實世界的時間序列,提出了一個替代問題:提示能否作為前綴信息,以豐富輸入上下文並指導重新編程時間序列補丁的轉換?這個概念被稱為 Prompt-as-Prefix (PaP) ,此外,作者還觀察到它顯著提高了 LLM 對下游任務的適應能力,同時補充了補丁的重新編程。通俗點說,就是把時間序列資料集的一些先驗訊息,以自然語言的方式,作為前綴 prompt,和對齊後的時序特徵拼接餵給 LLM,是不是能夠提升預測效果?
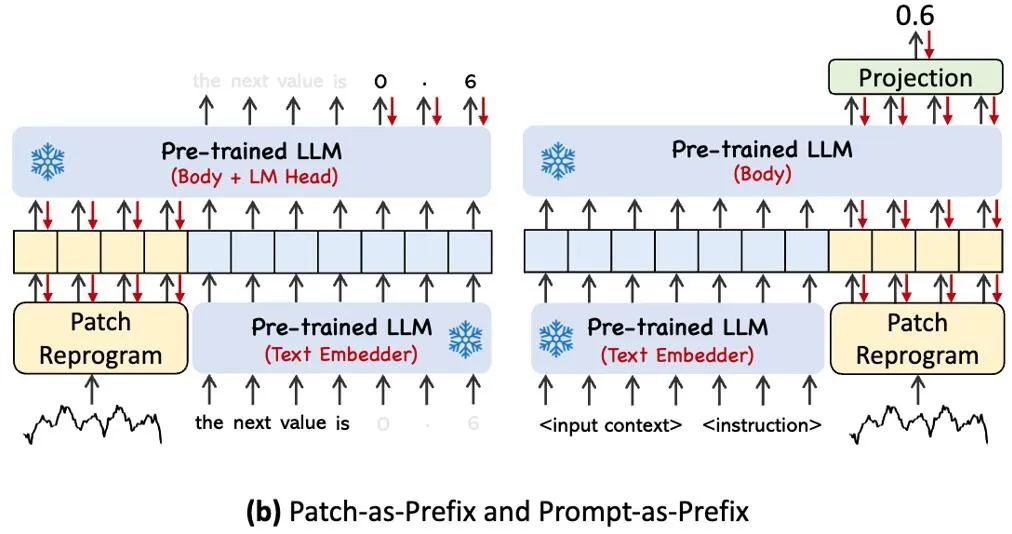
上圖展示了兩種提示方法。在 Patch-as-Prefix 中,語言模型被提示預測時間序列中的後續值,以自然語言表達。這種方法遇到了一些限制:(1)語言模型在無外部工具輔助下處理高精度數字時通常表現出較低的敏感性,這給長期預測任務的精確處理帶來了重大挑戰;(2)對於不同的語言模型,需要複雜的客製化後處理,因為它們在不同的語料庫上進行預訓練,並且可能在生成高精度數字時採用不同的分詞類型。這導致預測以不同的自然語言格式表示,例如 [‘0’, ‘.’, ‘6’, ‘1’] 和 [‘0’, ‘.’, ‘61’],表示 0.61。
在實踐中,作者確定了建立有效提示的三個關鍵組件:(1)資料集上下文;(2)任務指令,讓LLM 適配不同的下游任務;(3)統計描述,例如趨勢、時延等,讓LLM 更能理解時序資料的特性。下圖給出了一個提示範例。

4. 實驗效果
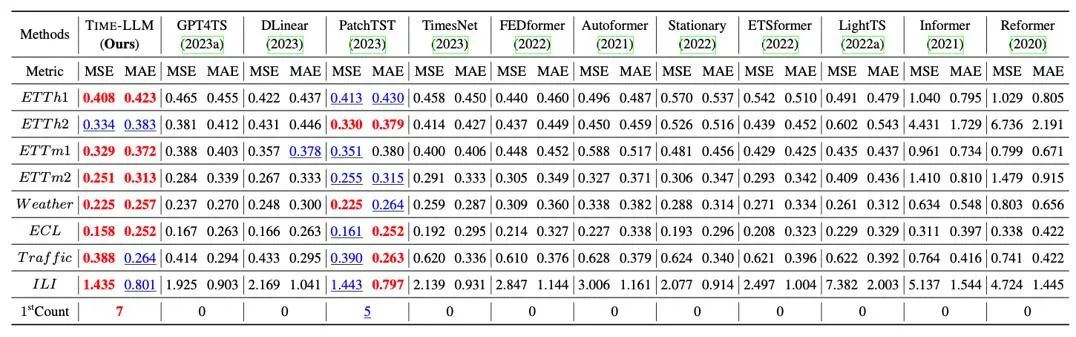
#我們在長程預測上經典的8 大公開資料集上進行了全面的測試,如下表所示,Time-LLM 在基準比較中顯著超過先前領域最優效果,此外對比直接使用GPT-2 的GPT4TS,採用reprogramming 重編程思想以及提示做前綴(Prompt-as-Prefix)的Time-LLM也有明顯提升,顯示了此方法的有效性。
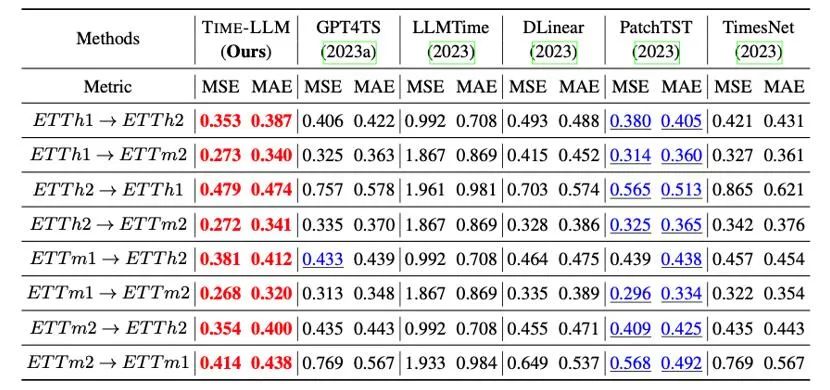
此外我們在跨領域適應的框架內評估重編程的LLM 的零樣本zero-shot 的學習能力,得益於重編程的能力,我們充分激活了LLM 在跨領域情境的預測能力,如下表所示,Time-LLM 在zero-shot 情境中也展現出非凡的預測效果。
5. 總結
大型語言模型(LLMs)的快速發展極大地推動了人工智慧在跨模態場景中的進步,並促進了它們在多個領域的廣泛應用。然而,LLMs 龐大的參數規模和主要針對自然語言處理(NLP)場景的設計,為其在跨模態和跨領域應用中帶來了許多挑戰。有鑑於此,我們提出了一種重編程大模型的新思路,旨在實現文字與序列資料之間的跨模態互動,並將此方法廣泛應用於處理大規模時間序列和時空資料。透過這種方式,我們期望讓 LLMs 如同靈活起舞的大象,能夠在更廣闊的應用場景中展現其強大的能力。
歡迎有興趣的朋友閱讀論文 (https://arxiv.org/abs/2310.01728) 或造訪專案頁 (https://github.com/KimMeen/Time-LLM) 以了解更多內容。
本計畫獲得了螞蟻集團智慧引擎事業部旗下 AI 創新研發部門 NextEvo 的全力支持,特別是得益於語言與機器智慧團隊以及優化智慧團隊的密切協作。在智慧引擎事業部副總裁周俊與優化智慧團隊負責人盧星宇的帶領與指導下,我們攜手圓滿完成了這項重要成果。
#以上是誰說大像不能起舞! 重編程大語言模型實現跨模態交互作用的時序預測 | ICLR 2024的詳細內容。更多資訊請關注PHP中文網其他相關文章!