



寫在前面&筆者的個人理解
神經輻射場(NeRF)已成為推進自動駕駛(AD)重新搜尋的前奏的工具,提供可擴展的閉環模擬和數據增強功能。然而,為了信任模擬中獲得的結果,需要確保AD系統以相同的方式感知真實資料和渲染資料。儘管渲染方法的效能正在提高,但許多場景在忠實重建方面仍然具有固有的挑戰性。為此,我們提出了一種新的視角來解決真實數據與模擬數據之間的差距。我們不僅專注於提高渲染保真度,而是探索簡單而有效的方法,在不影響真實資料效能的情況下,增強感知模型對NeRF偽影的穩健性。此外,我們使用最先進的神經渲染技術,首次對AD設定中的真實到模擬資料間隙進行了大規模調查。具體來說,我們的研究在真實和模擬資料上評估了物件偵測器和線上映射模型,並研究了不同預訓練策略的效果。我們的結果顯示,模型對模擬數據的精確度顯著提高,甚至在某些情況下提高了真實世界的表現。最後,我們深入研究了真實到模擬之間的相似性,將FID和LPIPS確定為強指標。
在本文中,我們提出了一種新的視角來縮小智駕系統和感知模組之間的差距。我們的目標不是提高渲染質量,而是在不降低真實資料效能的情況下,使感知模型對NeRF偽影更具穩健性。我們認為,這一方向是提升NeRF效能的補充,也是實現虛擬AV測試的關鍵。作為朝著這個方向邁出的第一步,我們表明,即使是簡單的資料增強技術也會對模型對NeRF偽影的穩健性產生很大影響。
我們對大規模AD資料集進行了首次廣泛的real2sim gap研究,並評估了多個目標偵測器以及線上建立圖模型對真實資料和最先進(SOTA)神經渲染方法資料的效能。我們的研究包括訓練過程中不同資料增強技術的影響,以及推理過程中NeRF渲染的保真度。我們發現,在模型微調過程中,這些資料顯示出增強技術的影響,以及NeRF渲染的保真度在某些情況下甚至提高了對真實資料的效能。最後,我們研究了real2sim之間的隱含和常見影像重建指標的相關性,並深入解將NeRFs用於CAD資料模擬器的重要性。我們發現LPIPS和FID是real2sim差距的強大指標,並一步驗證了我們提出的增強功能降低了對比差視覺合成性的敏感性。

方法詳解
為了測試和驗證NeRF驅動的模擬引擎的AD功能,他們可以使用已經收集的資料來探索新的虛擬場景。然而,為了使用此類模型結果可信,AD系統在處理資料和實際資料時必須以相同的方式運作。在這項工作中,我們提出了一種替代和補充方法,即調整AD系統,使其對真實數據和模擬數據之間的差異不那麼敏感。透過這種方式,我們可以調整AD系統,以便使真實數據和模擬數據之間的差異不那麼敏感,從而更好地處理真實數據和模擬數據之間的差異。
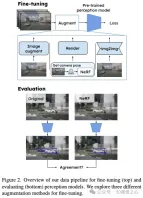
在探索微調策略如何讓知覺模型對渲染資料中的偽影更具穩健性的第一步時,我們使用了不同的微調策略。具體來說,在給定已經訓練好的模型的情況下,我們利用圖像來微調感知模型,這些圖像著重於提高渲染圖像的性能,同時保持真實數據的性能,見圖2。除了減少real2sim差距外,這還可能降低感測器真實性的要求,為神經渲染方法的更廣泛應用鋪平道路,並減少對描述方法的訓練和評估的計算需求。請注意,當我們專注於感知模型時,我們的方法也可以輕鬆擴展到端到端模型。
最後,我們可以想像多種方法來實現使模型更健壯的目標,例如從領域自適應和多任務學習文獻中汲取靈感。然而,微調需要最小的模型特定調整,使我們能夠輕鬆研究一系列模型。
Image augmentations
影像增強是一種常用的方法,用於對偽影增強穩健性的經典策略是使用影像增強。在這裡,我們選擇增強來表現渲染影像中存在的各種失真。更具體地說,我們添加隨機高斯噪聲,將影像與高斯模糊核卷積,應用類似於SimCLR中發現的光度失真。最後,對影像進行下採樣和上採樣。增廣是依序應用的,每個增廣都有一定的機率。
Точная настройка с использованием смешанных визуализированных изображений
NeRF — это модель глубокого обучения для рендеринга 3D-сцен. В ходе тонкой настройки модель может адаптироваться к другой естественной форме, т. е. включить эти данные при тонкой настройке. Это облегчает возможность обучения моделей NeRF, так что методы NeRF можно обучать на том же наборе данных, что и модель с учетом наблюдения. Однако обучение NeRF на больших наборах данных может быть дорогостоящим, некоторые из которых могут потребовать меток для таких задач, как обнаружение трехмерных объектов, семантическая сегментация или метки нескольких категорий. Кроме того, NeRF от AD часто увеличивает требования к порядку данных. Чтобы адаптироваться к этим требованиям, меткам может потребоваться более специальная обработка, такая как обнаружение трехмерных объектов, семантическая сегментация или метки нескольких категорий и т. д.
Далее мы делим изображения выбранной последовательности на обучающий набор NeRF и контрольный набор. Точная настройка моделей восприятия выполняется на всем наборе обучающих данных D, а для изображений с соответствиями рендеринга в D мы используем визуализированное изображение с вероятностью p. Это означает, что изображения, используемые для точной настройки, не видны модели NeRF.
Перевод изображения в изображение
Как упоминалось ранее, рендеринг данных NeRF — это дорогостоящий метод увеличения данных. Более того, помимо данных, необходимых для задачи восприятия, также требуются последовательные данные и, возможно, дополнительные маркеры. То есть для масштабируемого подхода нам в идеале нужна эффективная стратегия получения данных NeRF для одного изображения. С этой целью мы предлагаем использовать подход «изображение к изображению», чтобы научиться генерировать изображения, подобные NeRF. Учитывая реальное изображение, модель преобразует его в домен NeRF, эффективно вводя артефакты, типичные для NeRF. Это позволяет нам значительно увеличить количество NeRF-подобных изображений во время тонкой настройки при ограниченных вычислительных затратах. Мы обучаем модель «изображение-изображение», используя визуализированные изображения Dnerf и соответствующие им реальные изображения. Наглядные примеры различных стратегий улучшения показаны на рисунке 3.

результат




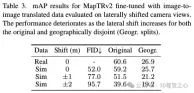

#Нейронное радиационное поле (NeRF ) стал многообещающим подходом к моделированию данных автономного вождения (AD). Однако на практике необходимо понимать, как действия, выполняемые системой AD над смоделированными данными, преобразуются в реальные данные. Наше крупномасштабное исследование выявило разницу в производительности между моделями восприятия, подвергающимися смоделированным и реальным изображениям. В отличие от более ранних подходов, направленных на улучшение качества рендеринга, в этой статье исследуется, как изменить модель восприятия, чтобы сделать ее более устойчивой к данным моделирования NeRF. Мы показываем, что точная настройка с использованием данных NeRF или NeRF-подобных данных значительно сокращает разрыв в Real2sim для методов обнаружения объектов и онлайн-картографии, не жертвуя при этом производительностью на реальных данных. Кроме того, мы показываем, что создание новых сценариев за пределами существующего распределения поездов, таких как моделирование выезда из полосы движения, может повысить производительность на реальных данных. Исследование часто используемых показателей изображений в сообществе NeRF показывает, что показатели LPIPS и FID демонстрируют наиболее сильную корреляцию с характеристиками восприятия. Это говорит о том, что сходство восприятия имеет большее значение для моделей восприятия, чем простое качество реконструкции. В заключение мы считаем, что данные моделирования NeRF ценны для AD, особенно при использовании предложенного нами метода для повышения надежности модели восприятия. Более того, данные NeRF не только помогают тестировать системы AD на смоделированных данных, но также помогают повысить производительность моделей восприятия на реальных данных.
以上是'真假難辨”!巧用NeRF產生的自動駕駛模擬數據的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Gemma範圍:Google'用於凝視AI的顯微鏡Apr 17, 2025 am 11:55 AM
Gemma範圍:Google'用於凝視AI的顯微鏡Apr 17, 2025 am 11:55 AM使用Gemma範圍探索語言模型的內部工作 了解AI語言模型的複雜性是一個重大挑戰。 Google發布的Gemma Scope是一種綜合工具包,為研究人員提供了一種強大的探索方式
 誰是商業智能分析師以及如何成為一位?Apr 17, 2025 am 11:44 AM
誰是商業智能分析師以及如何成為一位?Apr 17, 2025 am 11:44 AM解鎖業務成功:成為商業智能分析師的指南 想像一下,將原始數據轉換為驅動組織增長的可行見解。 這是商業智能(BI)分析師的力量 - 在GU中的關鍵作用
 如何在SQL中添加列? - 分析VidhyaApr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析VidhyaApr 17, 2025 am 11:43 AMSQL的Alter表語句:動態地將列添加到數據庫 在數據管理中,SQL的適應性至關重要。 需要即時調整數據庫結構嗎? Alter表語句是您的解決方案。本指南的詳細信息添加了Colu
 業務分析師與數據分析師Apr 17, 2025 am 11:38 AM
業務分析師與數據分析師Apr 17, 2025 am 11:38 AM介紹 想像一個繁華的辦公室,兩名專業人員在一個關鍵項目中合作。 業務分析師專注於公司的目標,確定改進領域,並確保與市場趨勢保持戰略一致。 simu
 什麼是Excel中的Count和Counta? - 分析VidhyaApr 17, 2025 am 11:34 AM
什麼是Excel中的Count和Counta? - 分析VidhyaApr 17, 2025 am 11:34 AMExcel 數據計數與分析:COUNT 和 COUNTA 函數詳解 精確的數據計數和分析在 Excel 中至關重要,尤其是在處理大型數據集時。 Excel 提供了多種函數來實現此目的,其中 COUNT 和 COUNTA 函數是用於在不同條件下統計單元格數量的關鍵工具。雖然這兩個函數都用於計數單元格,但它們的設計目標卻針對不同的數據類型。讓我們深入了解 COUNT 和 COUNTA 函數的具體細節,突出它們獨特的特性和區別,並學習如何在數據分析中應用它們。 要點概述 理解 COUNT 和 COU
 Chrome在這裡與AI:每天都有新事物!Apr 17, 2025 am 11:29 AM
Chrome在這裡與AI:每天都有新事物!Apr 17, 2025 am 11:29 AMGoogle Chrome的AI Revolution:個性化和高效的瀏覽體驗 人工智能(AI)正在迅速改變我們的日常生活,而Google Chrome正在領導網絡瀏覽領域的負責人。 本文探討了興奮
 AI的人類方面:福祉和四人底線Apr 17, 2025 am 11:28 AM
AI的人類方面:福祉和四人底線Apr 17, 2025 am 11:28 AM重新構想影響:四倍的底線 長期以來,對話一直以狹義的AI影響來控制,主要集中在利潤的最低點上。但是,更全面的方法認識到BU的相互聯繫
 您應該知道的5個改變遊戲規則的量子計算用例Apr 17, 2025 am 11:24 AM
您應該知道的5個改變遊戲規則的量子計算用例Apr 17, 2025 am 11:24 AM事情正穩步發展。投資投入量子服務提供商和初創企業表明,行業了解其意義。而且,越來越多的現實用例正在出現以證明其價值超出


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

SublimeText3漢化版
中文版,非常好用

SublimeText3 Linux新版
SublimeText3 Linux最新版

禪工作室 13.0.1
強大的PHP整合開發環境

