
一張圖即出AI影片!谷歌全新擴散模型,讓人物動起來

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-03-28 15:40:16750瀏覽
只需一張照片,和一段音頻,就能直接生成人物說話的視頻!
近日,來自Google的研究人員發布了多模態擴散模型VLOGGER,讓我們朝著虛擬數位人又邁進了一步。

論文網址:https://enriccorona.github.io/vlogger/paper.pdf
Vlogger可以收集單一輸入影像,使用文字或音訊驅動,產生人類語音的視頻,包括口型、表情、肢體動作等都非常自然。
我們先來看幾個範例:




如果感覺影片使用別人的聲音有點違和,小編幫你關掉聲音:

可以看出整個生成的效果是非常優雅自然的。
VLOGGER建立在最近生成擴散模型的成功之上,包括一個將人類轉換成3D運動的模型,以及一個基於擴散的新架構,用於透過時間和空間控制,增強文字生成圖像的效果。

VLOGGER可以產生可變長度的高品質視頻,並且這些視頻可以透過人臉和身體的高級表示輕鬆控制。

例如我們可以讓產生影片中的人閉上嘴:

#或閉上雙眼:

#與先前的同類模型相比,VLOGGER不需要針對個體進行訓練,不依賴臉部偵測和裁剪,而且包含了肢體動作、軀幹和背景,-構成了可以溝通的正常的人類表現。
AI的聲音、AI的表情、AI的動作、AI的場景,人類開始的價值是提供數據,再往後可能就沒什麼價值了?


在資料方面,研究人員收集了一個新的、多樣化的資料集MENTOR,比先前同類的資料集大了整整一個數量級,其中訓練集包括2200小時、800000個不同個體,測試集為120小時、4000個不同身份的人。

研究人員在三個不同的基準上評估了VLOGGER,顯示模型在影像品質、身分保存和時間一致性方面達到了目前的最優。

VLOGGER
VLOGGER的目標是產生一個可變長度的逼真視頻,來描繪目標人說話的整個過程,包括頭部動作和手勢。

如上圖所示,給定第1列所示的單一輸入影像和一個範例音訊輸入,右列中展示了一系列合成影像。
包括生成頭部運動、凝視、眨眼、嘴唇運動,還有以前模型做不到的一點,生成上半身和手勢,這是音訊驅動合成的一大進步。
VLOGGER採用了基於隨機擴散模型的兩階段管道,用於模擬從語音到視訊的一對多映射。
第一個網路將音訊波形作為輸入,以產生身體運動控制,負責目標視訊長度上的凝視、臉部表情和姿勢。
第二個網路是一個包含時間的圖像到圖像的平移模型,它擴展了大型圖像擴散模型,採用預測的身體控制來產生相應的幀。為了使這個過程符合特定身份,網路獲取了目標人的參考圖像。
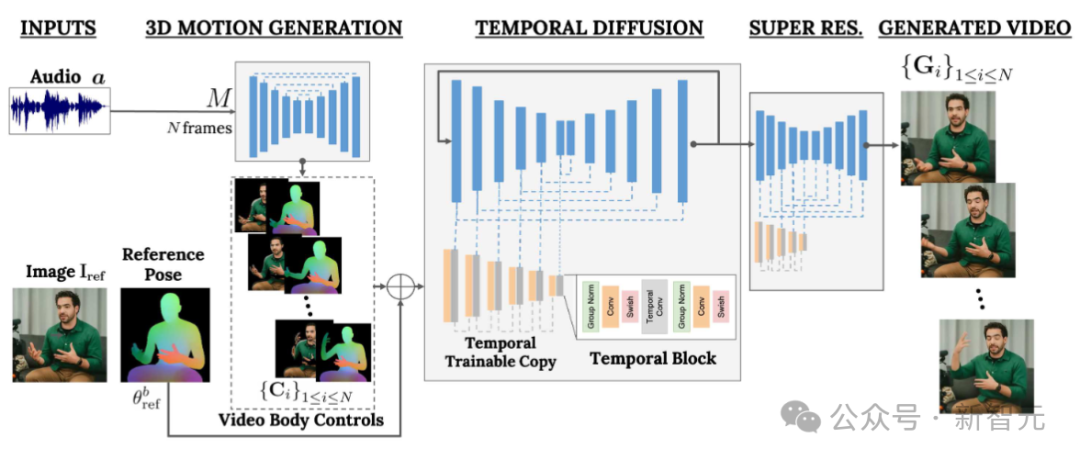
VLOGGER使用基於統計的3D身體模型,來調節影片產生過程。給定輸入影像,預測的形狀參數對目標標識的幾何屬性進行編碼。
首先,網路M獲取輸入語音,並產生一系列N幀的3D面部表情和身體姿勢。
然後渲染移動3D身體的密集表示,以在視訊生成階段充當2D控制項。這些影像與輸入影像一起作為時間擴散模型和超解析度模組的輸入。
音訊驅動的運動產生
#管道的第一個網路旨在根據輸入語音預測運動。此外也透過文字轉語音模型將輸入文字轉換為波形,並將產生的音訊表示為標準梅爾頻譜圖(Mel-Spectrograms)。
管道是基於Transformer架構,在時間維度上有四個多頭注意力層。包括幀數和擴散步長的位置編碼,以及用於輸入音頻和擴散步驟的嵌入MLP。
在每一幀中,使用因果遮罩使模型只專注於前一幀。模型使用可變長度的影片進行訓練(例如TalkingHead-1KH資料集),以產生非常長的序列。
研究人員採用基於統計的3D人體模型的估計參數,來為合成影片產生中間控製表示。
模型同時考慮了臉部表情和身體運動,以產生更好的表現力和動態的手勢。
此外,先前的臉部生成工作通常依賴扭曲(warped)的圖像,但在基於擴散的架構中,這個方法被忽視了。
作者建議使用扭曲的圖像來指導生成過程,這促進了網路的任務並有助於保持人物的主體身份。
產生會說話和移動的人類
#下一個目標是對一個人的輸入影像進行動作處理,使其遵循先前預測的身體和臉部運動。
受ControlNet的啟發,研究人員凍結了初始訓練的模型,並採用輸入時間控件,製作了編碼層的零初始化可訓練副本。
作者在時間域中交錯一維卷積層,網路透過取得連續的N幀和控制進行訓練,並根據輸入控制項產生參考人物的動作影片。
模型使用作者建立的MENTOR資料集進行訓練,因為在訓練過程中,網路會獲取一系列連續的幀和任意的參考圖像,因此理論上可以將任何視頻幀指定為參考。
不過在實務中,作者選擇取樣離目標片段更遠的參考,因為較近的範例提供的泛化潛力較小。
网络分两个阶段进行训练,首先在单帧上学习新的控制层,然后通过添加时间分量对视频进行训练。这样就可以在第一阶段使用大批量,并更快地学习头部重演任务。
作者采用的learning rate为5e-5,两个阶段都以400k的步长和128的批量大小训练图像模型。
多样性
下图展示了从一个输入图片生成目标视频的多样化分布。最右边一列显示了从80个生成的视频中获得的像素多样性。

在背景保持固定的情况下,人的头部和身体显著移动(红色意味着像素颜色的多样性更高),并且,尽管存在多样性,但所有视频看起来都很逼真。
视频编辑

模型的应用之一是编辑现有视频。在这种情况下,VLOGGER会拍摄视频,并通过闭上嘴巴或眼睛等方式改变拍摄对象的表情。
在实践中,作者利用扩散模型的灵活性,对应该更改的图像部分进行修复,使视频编辑与原始未更改的像素保持一致。
视频翻译
模型的主要应用之一是视频翻译。在这种情况下,VLOGGER会以特定语言拍摄现有视频,并编辑嘴唇和面部区域以与新音频(例如西班牙语)保持一致。
以上是一張圖即出AI影片!谷歌全新擴散模型,讓人物動起來的詳細內容。更多資訊請關注PHP中文網其他相關文章!