



寫在前面&筆者的個人理解
目前,在整個自動駕駛系統當中,感知模組扮演了其中至關重要的角色,行駛在道路上的自動駕駛車輛只有透過感知模組獲得到準確的感知結果後,才能讓自動駕駛系統中的下游規控模組做出及時、正確的判斷和行為決策。目前,具備自動駕駛功能的汽車中通常會配備包括環視相機感測器、光達感測器以及毫米波雷達感測器在內的多種數據資訊感測器來收集不同模態的信息,用於實現準確的感知任務。
基於純視覺的BEV感知演算法因其較低的硬體成本和易於部署的特點,以及其輸出結果能便捷地應用於各種下游任務,因此受到工業界和學術界的廣泛關注。近年來,許多基於BEV空間的視覺感知演算法相繼湧現,且在公開資料集上展現出色的感知性能。
目前,基於BEV空間的感知演算法根據建構BEV特徵的方式可以大致分成兩類演算法模型:
- 一類是以LSS演算法為代表的前向BEV特徵建構方式,這類感知演算法模型首先是利用感知模型中的深度估計網路來預測特徵圖的每個像素點的語意特徵資訊以及離散深度機率分佈,然後將得到的語意特徵資訊與離散深度機率採用外積運算的方式建構語意視錐特徵,採用BEV池化等方式最終完成BEV空間特徵的建構過程。
- 另一類是以BEVFormer演算法為代表的反向BEV特徵建構方式,這類感知演算法模型首先是在感知的BEV空間下明確的產生3D體素座標點,然後利用相機的內外參將3D體素座標點投影回影像座標系下,並對對應特徵位置的像素特徵進行擷取與聚合,以建構出BEV空間下的BEV特徵。
儘管兩種演算法都能夠準確產生BEV空間下的特徵並實現3D感知結果,但在目前基於BEV空間的3D目標感知演算法中,例如BEVFormer演算法,存在以下兩個問題:
- 問題一:由於BEVFormer感知演算法模型整體框架採用的是Encoder-Decoder的網路結構,其主要想法是利用Encoder模組取得BEV空間下的特徵,然後利用Decoder模組預測最終的感知結果,並透過將輸出的感知結果與真值目標計算損失來實現模型預測的BEV空間特徵的過程。但透過這種網路模型的參數更新方式會過度依賴Decoder模組的感知性能,導致可能存在模型輸出的BEV特徵與真值BEV特徵並不對齊的問題,從而進一步限制感知模型最終的表現性能。
- 問題二:由於BEVFormer感知演算法模型的Decoder模組依舊沿用Transformer中的自註意力模組->交叉注意力模組->前饋神經網路的步驟完成Query特徵的建構輸出最終的檢測結果,其整個過程依舊是一個黑盒模型,缺乏良好的可解釋性。同時,Object Query與真值目標之間的一對一配對過程在模型訓練的過程中也存在著很大的不確定性。
為了解決BEVFormer感知演算法模型存在的問題,我們對其進行了改進,提出了基於環視圖像的3D檢測演算法模型CLIP-BEVFormer。我們透過引入對比學習的方法,增強了模型對BEV特徵的建構能力,並在nuScenes資料集上實現了領先水準的感知效能。
文章連結:https://arxiv.org/pdf/2403.08919.pdf
網路模型的整體架構&細節梳理
在詳細在介紹本文提出的CLIP-BEVFormer感知演算法模型細節之前,下圖展示了CLIP-BEVFormer演算法的整體網路結構。
 本文提出的CLIP-BEVFormer感知演算法模型整體流程圖
本文提出的CLIP-BEVFormer感知演算法模型整體流程圖
透過演算法的整體流程圖可以看出,本文提出的CLIP-BEVFormer演算法模型是在BEVFormer演算法模型的基礎上進行改進的,這裡先簡單回顧一下BEVFormer感知演算法模型的實作過程。首先,BEVFormer演算法模型輸入的是相機感測器擷取到的環視圖像數據,利用2D的影像特徵來擷取網路提取輸入環視圖像的多尺度語意特徵資訊。其次,利用包含時序自註意力和空間交叉注意力的Encoder模組完成2D影像特徵向BEV空間特徵的轉換過程。然後,在3D感知空間中以常態分佈的形式產生一組Object Query,並送入Decoder模組中完成與Encoder模組輸出的BEV空間特徵的空間特徵交互利用。最後利用前饋神經網路預測Object Query查詢到的語意特徵,輸出網路模型最終的分類與迴歸結果。同時,在BEVFormer演算法模型訓練的過程中,採用一對一的匈牙利配對策略完成正負樣本的分配過程,並利用分類和迴歸損失完成整體網路模型參數的更新過程。 BEVFormer演算法模型整體的偵測過程可以用如下的數學公式來表示:
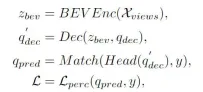
其中,公式中的代表BEVFormer演算法中的Encoder特徵擷取模組,代表BEVFormer演算法中的Decoder解碼模組,代表資料集中的真值目標標籤,代表目前BEVFormer演算法模型輸出的3D感知結果。
真值BEV的生成
在上文已經有提到,現有的絕大多數基於BEV空間的3D目標偵測演算法沒有顯式的對產生的BEV空間特徵進行監督,導致模型產生的BEV特徵可能存在與真實的BEV特徵不一致的問題,這種BEV空間特徵的分佈差異會限制模型最終的感知性能。基於這個考慮出發,我們提出了Ground Truth BEV模組,我們設計該模組的核心思路是想讓模型生成的BEV特徵可以和當前真值BEV特徵進行對齊,從而提高模型的表現性能。
具體而言,如整體網路框架圖所示,我們使用了一個真值編碼器()用來對BEV特徵圖上的任意一個真值實例的類別標籤和空間邊界框位置資訊進行編碼,該過程可以用公式表述成如下的形式:
其中公式中的具有和生成的BEV特徵圖同等大小的特徵維度,代表某個真值目標被編碼後的特徵資訊。在編碼的過程中,我們採用了兩種形式,一種是大語言模型(LLM),另一種是多層感知機(MLP),透過實驗結果發現,兩種方式基本上達到了同樣的表現。
除此之外,我們為了進一步增強真值目標在BEV特徵圖上的邊界信息,我們在BEV特徵圖上根據真值目標所在的空間位置將其裁剪下來,並對裁剪後的特徵採用池化操作建構對應的特徵資訊表示,該過程可以表述成如下的形式:
最後,我們為了實現模型產生的BEV特徵與真值BEV特徵的進一步對齊,我們採用了對比學習的方法來優化兩類BEV特徵之間的元素關係和距離,其優化過程可以表述成如下的形式:
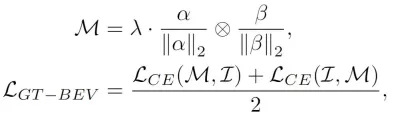
真值目標查詢交互
這部分在前文中也有提到,BEVFormer感知演算法模型中的Object Query透過Decoder模組與產生的BEV特徵進行交互,獲得對應的目標查詢特徵,但該過程整體還是一個黑盒子過程,缺少一個完整的流程理解。針對這個問題,我們引入了真值查詢交互模組,透過將真值目標來執行Decoder模組的BEV特徵交互作用來激發模型參數的學習過程。具體而言,我們將真值編碼器()模組輸出的真值目標編碼訊息引入到Object Query當中參與Decoder模組的解碼過程,與正常的Object Query參與相同的自註意力模組,交叉注意力模組以及前饋神經網路輸出最終的感知結果。但要注意的是,在解碼的過程中,所有的Object Query均是採用了並行計算的方式,防止真值目標訊息的洩漏。整個真值目標查詢互動過程,可以抽象表述成如下的形式:
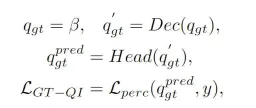
#其中,公式中的代表初始化的Object Query,和分別代表真值Object Query經過Decoder模組和感知偵測頭的輸出結果。透過在模型訓練的過程中引入真值目標的交互過程,我們提出的真值目標查詢交互模組可以實現真值目標查詢與真值BEV特徵進行交互,從而輔助模型Decoder模組的參數更新過程。
實驗結果&評估指標
定量分析部分
為了驗證我們提出的CLIP-BEVFormer演算法模型的有效性,我們分別在nuScenes資料集上從3D感知效果、資料集中目標類別的長尾分佈情況以及魯棒性等角度出發進行了相關實驗,下表是我們提出的演算法模型與其他3D感知演算法模型在nuScenes資料集上的精確度比較情況。
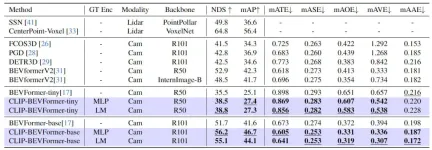
本文所提出的方法與其他感知演算法模型的比較結果
在這部分實驗中,我們分別評估了不同模型配置情況下的感知性能,具體而言,我們將CLIP-BEVFormer演算法模型應用於BEVFormer的tiny和base變體中。此外,我們也探討了將預先訓練的CLIP模型或MLP層作為真值目標編碼器對於模型感知效能的影響。透過實驗結果可以看出,無論是原先的tiny或base變體,在應用了我們提出的CLIP-BEVFormer演算法後,NDS和mAP指標均有穩定的效能提升。除此之外,透過實驗結果我們可以發現,對於真值目標編碼器選擇MLP層還是語言模型,我們提出的演算法模型對於此並不敏感,這種彈性可以讓我們提出的CLIP-BEVFormer演算法更具有適應能力並且方便上車部署。總之,我們提出的演算法模型的各類變體的性能指標一致表明提出的CLIP-BEVFormer演算法模型具有很好的感知穩健性,可以在不同模型複雜度和參數量的情況下實現出色的檢測性能。
除了驗證我們提出的CLIP-BEVFormer在3D感知任務上的表現外,我們還進行了長尾分佈的實驗來評估我們的演算法在面對資料集中存在長尾分佈情況下的魯棒性和泛化能力,實驗結果匯總在下表
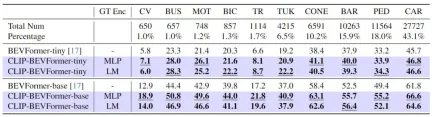
提出的CLIP-BEVFormer演算法模型在長尾問題上的表現性能
通過上表的實驗結果可以看出,nuScenes資料集中表現出了極大的類別數量不均衡的問題,其中一些類別如(建築車輛、公車、摩托車、自行車等)佔比很低,但是對於小型汽車的佔比非常高。我們透過進行長尾分佈的相關實驗來評估所提出的CLIP-BEVFormer演算法模型在特徵類別上的感知效能,從而驗證其解決較不常見類別的處理能力。透過上述的實驗數據可以看出,提出的CLIP-BEVFormer演算法模型在所有類別上均實現了性能的提升,並且在對於佔比極少的類別上,CLIP-BEVFormer演算法模型展示出了明顯的實質性改進。
考慮到在真實環境下的自動駕駛系統需要面臨硬體故障、惡劣天氣狀況或人造障礙物容易引發的感測器故障等問題,我們進一步實驗驗證了所提出的演算法模型的穩健性。具體而言,我們為了模擬感測器的故障問題,我們在模型實施推理的過程中隨機對一個相機的攝像頭進行遮擋,從而實現對於相機可能出現故障的場景進行模擬,相關的實驗結果如下表所示
 所提出的CLIP-BEVFormer演算法模型的穩健性實驗結果
所提出的CLIP-BEVFormer演算法模型的穩健性實驗結果
透過實驗結果可以看出,無論是在tiny或base的模型參數配置下,我們提出的CLIP-BEVFormer演算法模型始終要優於BEVFormer的相同配置的基準模型,驗證了我們的演算法模型在模擬感測器故障情況下的優越性能和優秀的魯棒性。
定性分析部分
下圖展示了我們提出的CLIP-BEVFormer演算法模型與BEVFormer演算法模型的感知結果視覺化對比情況。透過視覺化的結果可以看出,我們提出的CLIP-BEVFormer演算法模型的感知結果與真值目標更加的接近,顯示我們提出的真值BEV特徵產生模組與真值目標查詢互動模組的有效性。

提出的CLIP-BEVFormer演算法模型與BEVFormer演算法模型感知結果的視覺化對比情況
結論
#在本文中,針對原有的BEVFormer演算法當中存在的生成BEV特徵圖過程中缺少顯示監督以及Decoder模組中Object Query與BEV特徵交互查詢的不確定問題,我們提出了CLIP-BEVFormer演算法模型,並從演算法模型的3D感知性能、目標長尾分佈以及在感測器故障的穩健性等方面進行實驗,大量的實驗結果顯示我們提出的CLIP-BEVFormer演算法模型的有效性。
以上是CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM
了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM您一定记得,尤其是如果您是Teams用户,Microsoft在其以工作为重点的视频会议应用程序中添加了一批新的3DFluent表情符号。在微软去年宣布为Teams和Windows提供3D表情符号之后,该过程实际上已经为该平台更新了1800多个现有表情符号。这个宏伟的想法和为Teams推出的3DFluent表情符号更新首先是通过官方博客文章进行宣传的。最新的Teams更新为应用程序带来了FluentEmojis微软表示,更新后的1800表情符号将为我们每天
 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM
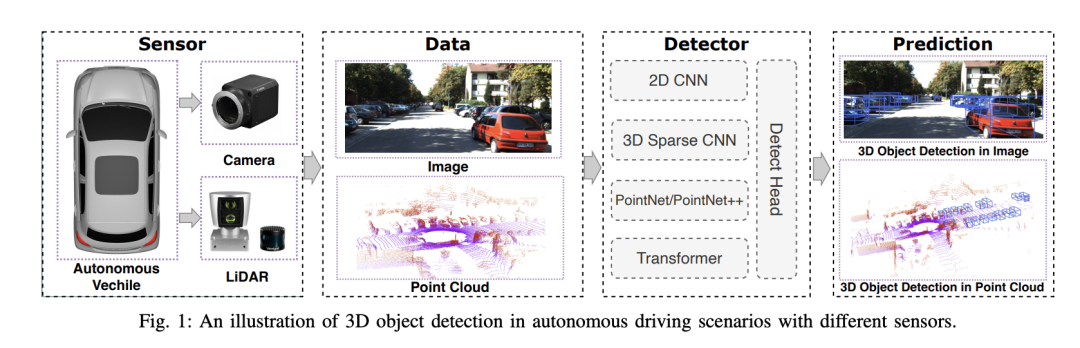
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM
Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM当八卦开始传播新的Windows11正在开发中时,每个微软用户都对新操作系统的外观以及它将带来什么感到好奇。经过猜测,Windows11就在这里。操作系统带有新的设计和功能更改。除了一些添加之外,它还带有功能弃用和删除。Windows11中不存在的功能之一是Paint3D。虽然它仍然提供经典的Paint,它对抽屉,涂鸦者和涂鸦者有好处,但它放弃了Paint3D,它提供了额外的功能,非常适合3D创作者。如果您正在寻找一些额外的功能,我们建议AutodeskMaya作为最好的3D设计软件。如
 单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PM
单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PMChatGPT给AI行业注入一剂鸡血,一切曾经的不敢想,都成为如今的基操。正持续进击的Text-to-3D,就被视为继Diffusion(图像)和GPT(文字)后,AIGC领域的下一个前沿热点,得到了前所未有的关注度。这不,一款名为ChatAvatar的产品低调公测,火速收揽超70万浏览与关注,并登上抱抱脸周热门(Spacesoftheweek)。△ChatAvatar也将支持从AI生成的单视角/多视角原画生成3D风格化角色的Imageto3D技术,受到了广泛关注现行beta版本生成的3D模型,
 自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM
自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM对于自动驾驶应用来说,最终还是需要对3D场景进行感知。道理很简单,车辆不能靠着一张图像上得到感知结果来行驶,就算是人类司机也不能对着一张图像来开车。因为物体的距离和场景的和深度信息在2D感知结果上是体现不出来的,而这些信息才是自动驾驶系统对周围环境作出正确判断的关键。一般来说,自动驾驶车辆的视觉传感器(比如摄像头)安装在车身上方或者车内后视镜上。无论哪个位置,摄像头所得到的都是真实世界在透视视图(PerspectiveView)下的投影(世界坐标系到图像坐标系)。这种视图与人类的视觉系统很类似,
 跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM
跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM原标题:Radocc:LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation论文链接:https://arxiv.org/pdf/2312.11829.pdf作者单位:FNii,CUHK-ShenzhenSSE,CUHK-Shenzhen华为诺亚方舟实验室会议:AAAI2024论文思路:3D占用预测是一项新兴任务,旨在使用多视图图像估计3D场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景
 《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM
《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM一些原神“奇怪”的关键词,在这两天很有关注度,明明搜索指数没啥变化,却不断有热议话题蹦窜。例如了龙王、钟离等“转变”立绘激增,虽在网络上疯传了一阵子,但是经过追溯发现这些是合理、常规的二创同人。如果单是这些,倒也翻不起多大的热度。按照一部分网友的说法,除了原神自身就有热度外,发现了一件格外醒目的事情:原神3d同人作者shirakami已经被捕。这引发了不小的热议。为什么被捕?关键词,原神3D动画。还是越过了线(就是你想的那种),再多就不能明说了。经过多方求证,以及新闻报道,确实有此事。自从去年发


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

Dreamweaver CS6
視覺化網頁開發工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

WebStorm Mac版
好用的JavaScript開發工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

