



《Linux高效能網路程式設計十談》十篇技術部落格已經寫完幾個月了,想著還是寫點總結來回顧一下這幾年的工作,說來在鵝廠兩次經歷加起來也快8年,雖然很多時候在做螺絲釘的事情,不過細想自己的高性能架構演進的經歷,從參與,優化到最後設計架構,從中還是學到了很多東西。

#1、事先設計還是業務演進?
大家應該都經歷過專案從0到1的過程,我想提一個問題:很多時候的架構是隨著業務演進還是提前設計呢?
有人可能已經研究過相關的架構書籍,這些書籍大多認為架構是隨著業務發展而演變的。然而,也有許多架構師堅持認為架構應該提前設計。在此,我暫時不做結論,而是透過我自己的經驗來探討架構的演進。
2、從PHP到C
#2.1 簡單的PHP架構
PHP作為一門簡單便捷的語言,在大廠各部門應該都有身影,當時我工作用的兩種語言:C 和PHP,使用PHP開發功能很快,而且有很多成熟的庫,因此組成了經典的nginx
php-fpm memcache架構。
 php架構
php架構
在目前架構下單一8c8g機器支援1000qps問題不大,所以對於業務目前1wqps都不到,顯然多堆幾台機器就可以支援了。對於快取層的設計,在redis還不是發展很好的情況下,memcache是當時快取元件的主流,而且對於業務和對接PHP簡單。但隨著業務的發展,按照當時計算曲線可能一年以內會到5wqps,用nginx
php-fpm memcache架構是不是合理?經過討論後的目標是服務端高性能,於是開始了高性能的探索之旅。
2.2 多進程的框架
在當時,為了實現高效能服務端框架,人們嘗試了一些方案,其中之一是利用PHP外掛功能將Server的功能整合到腳本語言中。這種方法在一定程度上實現了高效能的目標。例如,現在PHP的swoole就是這種方法的一個發展結果。
 php-server
php-server
不過這裡會面臨一些需要解決的問題:
- 熟悉PHP擴充的使用場景,防止踩坑
- PHP本身使用上的記憶體洩漏問題
- 出現問題時的檢查成本,例如一旦出現問題,我們有時候需要去了解PHP源碼,但是面對幾十萬行程式碼,這個成本是相當高
- PHP使用上簡單,這個實際相對的,隨著Docker的崛起,單機時代必然會過去,PHP的生態是不是能支持
- …
基於上述思考與對業務發展的分析,其實我們自己實現一個或使用現有的C 框架實現一套業務層的Server應該更合理,於是經過考慮採用了公司內的SPP框架,其架構如下:
 SPP框架架構
SPP框架架構
可以看出SPP是多進程架構,其架構類似Nginx,分為Proxy進程和Worker進程,其中:
- proxy程序使用handle_init執行初始化,handle_route轉送到指定執行的worker處理程序,handle_input處理請求的入包
- worker程序使用handle_init執行初始化,handle_process處理套件和業務邏輯並傳回
使用C 的架構後,單機效能直接提升到6kqps,基本上已經滿足效能上的要求,可以在相同的機器下支援更多的業務,看似已經可以將架構穩定下來了。
2.3 引進協程
使用C 在效能上已經滿足需求,但是在開發效率上卻存在眾多問題,例如存取redis,為了保持服務的高效能,程式碼邏輯上都採用非同步回調,類似如下:
... int ret = redis->GetString(k, getValueCallback) ...
其中getValueCallback就是回呼函數,如果出現很多io操作,這裡回調就會非常麻煩,即使封裝為類似同步方式,在處理上也非常麻煩,當時還沒有引入std::future和std::async。
另一方面基於後續的qps可能到10~20w量級,協程在多io的服務處理的性能上也會更有優勢,於是開始了協程方式改造,將io的地方全部替換為協程調用,對於業務開發來說,程式碼上就變成了這樣:
... int ret = redis->GetString(k, value) ...
其中value就是可以直接用的回傳值,一旦程式碼中有io的地方,底層就會將io替換為協程的API,這樣阻塞的io操作就全部變成同步化原語,程式碼結構和開發效率都提升不少(具體的協程實作可以參考系列文章的《Linux高效能網頁程式設計十談|協程》)。
 協程
協程
從架構上還是沒有太多變化,多進程 協程的方式,支援著業務發展幾年時間,雖然性能上沒有指數增長,但是對於高性能探索和沈澱上已經有了更多經驗。
3、雲端原生
#業務繼續發展,而工程師總是在追求最前沿的理念,雲原生作為最近這幾年熱門的技術點自然不會放過,但是在進入雲原生之前,如果你的團隊沒有DevOps開發理念,這將是一個痛苦的過程,需要對架構設計和框架選擇償還技術債務。
3.1 實作DevOps理念
以前做架構考慮高效能,隨著對於架構的理解,發現高效能只是架構設計的一個小領域,要做好一個架構,需要更多的敏捷流程和服務治理概念,具體考慮的點總結如下:
- 持續整合:開發人員一天多次將程式碼整合到共享儲存庫中,並且對程式碼的每個孤立變更都將立即進行測試,以檢測並防止整合問題
- 連續交付:連續交付(CD)確保可以隨時發佈在CI儲存庫中測試的每個版本的程式碼
- 連續部署:這裡包括灰階部署,藍綠發布等,目的是快速迭代,經過相對完整的整合測試,就可以灰階驗證
- 服務發現:將服務視為微服務化,簡化服務之間的呼叫
- RPC的框架:追求高效能的Server框架,也需要考慮限流,熔斷等基礎元件的支援
- 監控系統:整合Promethues,OpenTracing等功能,能在敏捷開發流程中快速發現線上的問題
- 容器化:為了環境統一,同時事先考慮雲端原生場景,容器化是開發過程中不可或缺的
- …
 DevOps
DevOps
到這裡會發現,簡單的高效能Server已經作為架構追求的目標了,於是需要重新研究並設計架構,以順利實施DevOps的理念。
3.2 多執行緒
基於DevOps,結合上面的C 的Server框架,發現多進程已經無法滿足架構的需求,原因如下:
- 多進程與Docker容器的單一進程理念不符
- 工作進程負載不均,如何更利用多核心
- 與監控系統有效的對接
- 業務配置重複加載,需要重新適配配置中心
- 用多進程做有狀態的服務不是很合理
- …
業務也發展到百萬QPS,為了更好的服務治理和服務呼叫成本,不得不考慮另外的架構:
(1)調查gRPC
 gRPC
gRPC
gRPC是多執行緒RPC
Server,有成熟的生態,各種中間件,支援多語言等,對於從0到1開發的業務是一個不錯的選擇,但是對於業務遷移卻面臨挑戰,例如開發自己的中間件適配服務發現,配置中心等,改造協議按照自定義編解碼,如何結合協程等,因此對於部分業務滿足,但是還需要更好的結合公司內組件的RPC
Server。
(2)使用tRPC
剛好公司內正在開發tRPC,經過研究發現基本滿足需求,於是在tRPC的C 版本剛發展初期就嘗試適配我們的系統,經過一系列的改造,高性能的RPC框架在業務系統中遷移和使用了,其中tRPC的架構:
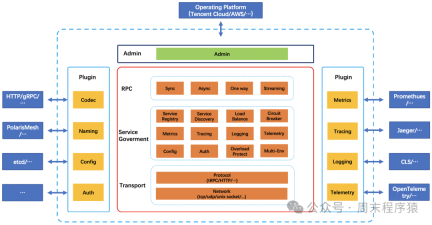
#https://trpc.group/zh/docs/what-is-trpc/archtecture_design/
基於上述的考量與業務的發展,於是開始嘗試以高效能為基礎,將RPC Server框架統一,以適配後續RPC多樣化場景,於是實現一套適配我們的業務系統的RPC
Server的基本框架:
 新架構
新架構
3.3、走向k8s
經歷了上述選型和改造後,我們的服務在遷移k8s過程中,按部就班對接就可以了,服務不需要經過太多的改造可以在其平台上運行,對接的各個平台也是可以完整的支持。
看似去追求更新的技術等著下一個風口就可以了?實際這個時候反而挑戰更多了,由於在雲上的便捷和遷移服務架構的無序擴張,導致業務服務和邏輯層次越來越多,同時一個服務依賴的下游鏈路越來越長,雖然我們的框架支援鏈路跟踪,但是鏈路越長,對服務的可控性和穩定性就越來越差,反而浪費更多的人力支持日常ops。
怎麼辦?…
是不是要合併業務邏輯,將架構簡化?這裡面臨的問題是業務邏輯複雜情況下往往週期很長,而且從成本角度考慮比較高,收益並不會很大
是不是重新開發的新的架構,將腐朽的保持原樣或拋棄,使用新的架構來適配下一步的發展。
以上是Linux高效能網路程式設計十談的詳細內容。更多資訊請關注PHP中文網其他相關文章!

![原子心臟遊戲還沒有準備好加載此保存[已解決] -Minitool](https://img.php.cn/upload/article/001/242/473/174594541048769.jpg?x-oss-process=image/resize,p_40) 原子心臟遊戲還沒有準備好加載此保存[已解決] -MinitoolApr 30, 2025 am 12:50 AM
原子心臟遊戲還沒有準備好加載此保存[已解決] -MinitoolApr 30, 2025 am 12:50 AM由於某些原因,您可能會遇到“遊戲還沒有準備好加載此保存”錯誤。在這篇文章中,PHP.CN收集了問題的可能原因,並為您提供了5種故障排除方法。
 專家Windows X-Lite最佳11 24H2安裝指南Apr 30, 2025 am 12:49 AM
專家Windows X-Lite最佳11 24H2安裝指南Apr 30, 2025 am 12:49 AM如果您需要在較低的配置計算機上享受Windows 11 24H2,則可以下載Windows X-Lite最佳11 24H2 HOME或PRO。在這裡,PHP.CN軟件上的這篇文章旨在向您展示Windows X-Lite最佳11 24H2下載並安裝。
 無支撐的PC意外接收Windows 11 22H2 -MinitoolApr 30, 2025 am 12:48 AM
無支撐的PC意外接收Windows 11 22H2 -MinitoolApr 30, 2025 am 12:48 AMMicrosoft意外將Windows 11 22H2釋放到Release Preview Channel中的Windows Insiders。一些用戶認為Microsoft改變了Windows 11的硬件和系統要求。但是,這只是Windows 11中的一個錯誤。您可以follo
 如何在Windows 11/10/8/7上使用屏幕上的鍵盤? - MinitoolApr 30, 2025 am 12:47 AM
如何在Windows 11/10/8/7上使用屏幕上的鍵盤? - MinitoolApr 30, 2025 am 12:47 AM屏幕鍵盤是一個虛擬鍵盤,可在Windows 11/10/8/7上使用。如果您不知道如何在Windows計算機上打開並使用它,則可以從php.cn軟件中閱讀此帖子以獲取一些相關信息。
 privadovpn免費下載Windows,Mac,Android,iOS -MinitoolApr 30, 2025 am 12:46 AM
privadovpn免費下載Windows,Mac,Android,iOS -MinitoolApr 30, 2025 am 12:46 AMPrivadOVPN是用於Windows,MacOS,Android,iOS,Android TV等的免費VPN服務。使用此免費VPN,您可以在線訪問任何內容而無需位置限制,並在瀏覽Internet時匿名保持匿名。檢查如何下載和安裝
 如何在iPhone/android/筆記本電腦上刪除藍牙設備? - MinitoolApr 30, 2025 am 12:44 AM
如何在iPhone/android/筆記本電腦上刪除藍牙設備? - MinitoolApr 30, 2025 am 12:44 AM無線藍牙為人們帶來了現代生活的許多便利。當您不想連接藍牙設備時,您可以選擇忘記它。但是,當您要重新建立連接時,如何重新連接並刪除藍牙呢?
 Netflix觀看電影和電視節目的10個最佳VPN -MinitoolApr 30, 2025 am 12:43 AM
Netflix觀看電影和電視節目的10個最佳VPN -MinitoolApr 30, 2025 am 12:43 AM要觀看各種Netflix電影和電視節目,您可以使用VPN服務。這篇文章介紹了一些最佳的免費Netflix VPN供您參考。有關更多有用的計算機教程和工具,您可以訪問php.cn軟件官方網站。
 Discovery Plus錯誤400 - 它是什麼以及如何修復? - MinitoolApr 30, 2025 am 12:42 AM
Discovery Plus錯誤400 - 它是什麼以及如何修復? - MinitoolApr 30, 2025 am 12:42 AM當您在Discovery Plus上觀看自己喜歡的電視節目和電影時,Discover Plus Plus錯誤400是一個通常的問題。 PHP.CN網站上的本文將介紹Discovery Plus 400和一些解決方案。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

禪工作室 13.0.1
強大的PHP整合開發環境

