
Meta新增兩大萬卡集群,投入近50000塊英偉達H100 GPU

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-03-15 09:34:13715瀏覽

Meta日前推出兩個強大的GPU集群,用於支援下一代生成式AI模型的訓練,包括即將推出的Llama 3。
據報導,這兩個資料中心都配備了高達24,576塊GPU,旨在支援比之前發布的更大、更複雜的生成式AI模型。
作為一種流行的開源演算法模型,Meta的Llama能與OpenAI的GPT和Google的Gemini相媲美。
Meta刷新AI叢集規模
根據極客網了解,這兩個GPU叢集都搭載了英偉達目前功能最強大的H100 GPU,規模比Meta之前推出的大型叢集要龐大得多。先前,Meta的叢集擁有約16,000塊Nvidia A100 GPU。
據報道,Meta已經購買了成千上萬塊英偉達最新推出的GPU。市場研究公司Omdia在最新報告中指出,Meta已成為英偉達最重要的客戶之一。
Meta工程師宣布,他們計劃利用全新的GPU叢集對現有的AI系統進行微調,以訓練出更新更強大的AI系統,其中包括Llama 3。
該工程師指出,Llama 3的開發工作目前正在“進行中”,但並沒有透露何時對外發布。
Meta的長期目標是發展通用人工智慧(AGI)系統,因為AGI在創造性方面更接近人類,與現有的生成式AI模型有著明顯的差異。
新的GPU叢集將有助於Meta實現這些目標。此外,該公司正在改進PyTorch AI框架,使其能夠支援更多的GPU。
兩個GPU叢集採用不同架構
值得一提的是,雖然這兩個叢集的GPU數量完全相同,都能以每秒400GB的端點相互連接,但它們採用了不同的架構。
其中,一個GPU叢集可以透過融合乙太網路結構遠端存取直接記憶體或RDMA,該網路結構採用Arista Networks的Arista 7800與Wedge400和Minipack2 OCP機架交換機構建造。另一個GPU叢集使用英偉達的Quantum2 InfiniBand網路結構技術建構。
這兩個叢集都使用了Meta的開放式GPU硬體平台Grand Teton,該平台旨在支援大規模的AI工作負載。 Grand Teton的主機到GPU頻寬是其前身Zion-EX平台的四倍,運算能力、頻寬以及功率是Zion-EX的兩倍。
Meta表示,這兩個集群採用了最新的開放式機架電源和機架基礎設施,旨在為資料中心設計提供更大的靈活性。 Open Rack v3允許將電源架安裝在機架內部的任何地方,而不是將其固定在母線上,從而實現更靈活的配置。
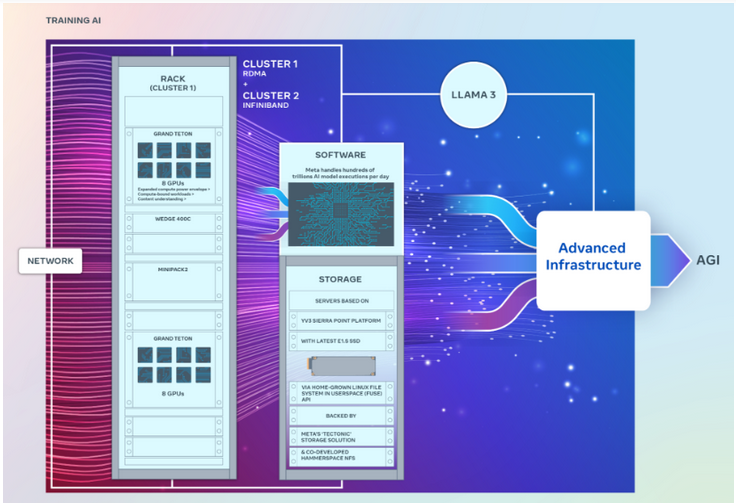
此外,每個機架的伺服器數量也是可自訂的,從而在每個伺服器的吞吐量容量方面實現更有效的平衡。
在儲存方面, 這兩個GPU叢集是基於YV3 Sierra Point伺服器平台,採用了最先進的E1.S固態硬碟。
更多GPU正在路上
Meta工程師在文中強調,該公司致力於AI硬體堆疊的開放式創新。 「當我們展望未來時,我們認識到,以前或目前有效的方法可能不足以滿足未來的需求。這就是我們不斷評估和改進基礎設施的原因。」
Meta是最近成立的AI聯盟的成員之一。該聯盟旨在創建一個開放的生態系統,以提高AI開發的透明度和信任,並確保每個人都能從其創新中受益。
Meta方面也透露,將繼續購買更多的Nvidia H100 GPU,計劃在今年年底前擁有35萬塊以上的GPU。這些GPU將用於持續建構AI基礎設施,意味著未來將有更多、更強大的GPU叢集問世。
以上是Meta新增兩大萬卡集群,投入近50000塊英偉達H100 GPU的詳細內容。更多資訊請關注PHP中文網其他相關文章!