




自動駕駛的端對端可微學習最近已成為一種突出的範式。一個主要瓶頸在於其對高品質標記資料的巨大需求,例如3D框和語義分割,這些資料的手動註釋成本是出了名的昂貴。由於AD中樣本內的行為往往存在長尾分佈這一突出事實,因此這一困難更加明顯。換言之,收集到的大部分數據可能微不足道(例如,在筆直的道路上向前行駛),只有少數情況是安全關鍵的。在本文中,我們探討了一個實際重要但未被充分探索的問題,即如何實現端到端AD的樣本和標籤效率。
具體而言,論文設計了一種面向規劃的主動學習方法,該方法根據所提出的規劃路線的多樣性和有用性標準,逐步註釋部分收集的原始資料。經驗上,所提出的計劃導向方法可以在很大程度上優於一般的主動學習方法。值得注意的是,方法僅使用30%的nuScenes數據,就實現了與最先進的端對端AD方法相當的效能。希望我們的工作能激勵未來的工作,從以數據為中心的角度,除了方法論的努力之外。
論文連結:https://arxiv.org/pdf/2403.02877.pdf
本文的主要貢獻:
- 第一個深入研究E2E-AD的數據問題的人。還提供了一個簡單而有效的解決方案,可以在有限的預算內識別和註釋有價值的數據,用於規劃。
- 基於端到端方法的規劃導向的哲學,為規劃路線設計了新的特定任務的多樣性和不確定性測量。
- 大量的實驗和消融研究證明了方法的有效性。 ActiveAD在很大程度上優於一般的對等方法,並且僅使用30%的nuScenes數據,實現了與具有完整標籤的SOTA方法相當的性能。
方法介紹
在端對端AD框架中詳細描述了ActiveAD,並根據AD的資料特徵設計了多樣性和不確定性指標。
1)標籤的初始樣本選擇
對於電腦視覺中的主動學習,初始樣本選擇通常僅基於原始圖像,而沒有額外的資訊或學習到的特徵,這導致了隨機初始化的常見做法。對於AD,還有其他先前的資訊可供利用。具體來說,當從感測器收集數據時,可以同時記錄傳統訊息,如自車的速度和軌跡。此外,天氣和照明條件通常是連續的,並且易於在片段層級中進行註釋。這些資訊有利於為初始集合選擇做出明智的選擇。因此,我們為初始選擇設計了自我多樣性測量。

Ego Diversity:由三個部分組成:1)天氣照明2)駕駛指令3)平均速度。首先使用nuScenes中的描述,將完整的資料集分割成四個互斥子集:Day Sunny(DS)、Day Rainy(DR)、Night Sunny(NS)、NightRainy(NR)。其次,根據一個完整片段中左、右和直行駕駛指令的數量將每個子集分為四類:左轉(L)、右轉(R)、超車(O)、直行(S)。論文設計了一個閾值τc,其中如果剪輯中左右命令的數量都大於或等於閾值τc時,我們將其視為該剪輯中的超越行為。如果只有向左指令的數量大於閾值τc,則表示左轉。如果只有向右指令的數量大於閾值τc,則表示向右轉。所有其它情況都被認為是直接的。第三,計算每個場景中的平均速度,並在相關的子集中按升序對它們進行排序。


#圖2給出了基於多路樹的初始選擇過程的詳細直覺過程。
2)增量選擇的準則設計
在本節將介紹如何基於使用已註釋片段訓練的模型,對片段的新部分進行增量註釋。我們將使用中間模型對未標記的片段進行推理,隨後的選擇是基於這些輸出。儘管如此,還是採取了規劃導向的觀點,並介紹了後續資料選擇的三個標準:位移誤差、軟碰撞和代理不確定性。
標準一:位移誤差(DE)。將表示為模型的預測規劃路線τ與資料集中記錄的人類軌跡τ*之間的距離。

其中T表示場景中的幀。由於位移誤差本身是一個性能指標(無需註釋),因此它自然成為主動選擇中的第一個也是最關鍵的標準。
標準二:軟碰撞(SC)。將LSC定義為預測的自車軌跡和預測的agent軌跡之間的距離。將透過閾值ε過濾掉低置信度agent預測。在每個場景中,選擇最短距離作為危險係數的量測。同時,在term和最近距離之間保持正相關:

使用“軟碰撞”作為一個標準,因為:一方面,與“置換誤差”不同,“碰撞比率」的計算取決於目標的3D框的註釋,而這些註釋在未標記的資料中不可用。因此,應該能夠僅根據模型的推理結果來計算標準。另一方面,考慮一個硬碰撞標準:如果預測的自車軌跡會與其他預測的agent的軌跡發生碰撞,將其指定為1,否則指定為0。然而,這可能會導致標籤為1的樣本太少,因為AD中最先進模型的碰撞率通常很小(低於1%)。因此,選擇使用與其他對目標最近的距離來代替“碰撞率”度量。當與其他車輛或行人的距離太近時,風險被認為要高得多。簡言之,「軟碰撞」是衡量碰撞可能性的有效指標,可以提供密集的監督。
標準III:agent不確定性(AU)。對周圍agent的未來軌蹟的預測自然具有不確定性,因此運動預測模組通常會產生多個模態和相應的置信度得分。我們的目標是選擇那些附近agent具有高度不確定性的資料。具體來說,透過距離閾值δ過濾出遙遠的主體,並計算剩餘主體的多種模式的預測機率的加權熵。假設模態的數量是,且agent在不同模態下的置信度得分是Pi(a),其中i∈{1,…,Nm}。然後,Agent不確定性可以定義為:

Overall Loss:

3)整體主動學習範式
Alg1介紹了方法的整個工作流程。給定可用預算B、初始選擇大小n0、在每個步驟中進行的活動選擇的數量ni以及總共M個選擇階段。首先使用上述描述的隨機化或自車多樣性方法初始化選擇。然後,使用目前註釋的資料來訓練網路。基於訓練的網絡,我們對未標記的進行預測,併計算總損失。最後根據總體損失對樣本進行排序,並選擇當前迭代中要註釋的前ni個樣本。重複這個過程,直到迭代達到上限M,並且所選的樣本數達到上限B。

實驗結果
在廣泛使用的nuScenes資料集上進行了實驗。所有實驗都使用PyTorch實現,並在RTX 3090和A100 GPU上運行。

表1:規劃表現。 ActiveAD在所有註解budget設定中都優於一般的主動學習基線。此外,與使用整個資料集進行訓練相比,具有30%資料的ActiveAD實現了略好的規劃效能。帶有*的VAD表示已經更新了結果,這些結果比原始工作中報告的結果要好。帶有†的UniAD表示已使用VAD的指標來更新結果。

表2:設計消融實驗。 “RA”和“ED”表示基於隨機性和自車多樣性的初始集選擇。 “DE”、“SC”和“AU”表示位移誤差, 分別為軟碰撞和agent不確定性。所有帶有“ED”的組合都使用相同的10%資料進行初始化。 LDE、LSC和LAU分別歸一化為[0,1],將超參數α和β設為1。
圖3:所選場景視覺化。根據所選的前置相機影像是基於在10%資料上訓練的模型的位移誤差(col 1)、軟碰撞(col 2)、agent不確定性(col 3)和混合(col 4)標準。 Mixed代表了我們的最終選擇策略ActiveAD,並考慮了前三種情況!

表4,各種場景下的效能。在各種天氣/照明和駕駛命令條件下,使用30%數據的活動模型的平均L2(m)/平均碰撞率(%)越小,性能越好。


圖4:多個標準之間的相似性。它顯示了透過四個標準選擇10%(左)和20%(右)的新採樣場景:位移誤差(DE)、軟碰撞(SC)、代理不確定性(AU)和混合(MX)
本工作的一些結論
為了解決端到端自動駕駛資料標註的高成本和長尾問題,率先開發了量身定制的主動學習方案ActiveAD。 ActiveAD基於規劃導向的哲學,引入了新的任務特定的多樣性和不確定性測量。大量實驗證明了方法的有效性,僅使用30%的數據,就顯著超過了一般的往期方法,並實現了與最先進模型相當的性能。這代表著從以數據為中心的角度對端到端自動駕駛的一次有意義的探索,並希望我們的工作能啟發未來的研究和發現。
以上是端到端沒有資料怎麼辦? ActiveAD:面向規劃的端對端自動駕駛主動學習!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 7個免費的chatgpt替代品來創建吉卜力風格的圖像Apr 25, 2025 am 09:48 AM
7個免費的chatgpt替代品來創建吉卜力風格的圖像Apr 25, 2025 am 09:48 AM解鎖吉卜力風格的AI藝術的魔力:免費,簡單的方法! AI生成的藝術的最近激增模仿了吉卜力的吉卜力工作室的迷人風格,這吸引了互聯網。 雖然OpenAI的GPT-4O提供了令人印象深刻的功能,但需求量很高。
 AI通過圖靈測試:GPT-4.5揭示了未來Apr 25, 2025 am 09:42 AM
AI通過圖靈測試:GPT-4.5揭示了未來Apr 25, 2025 am 09:42 AM這篇博客文章探討了2025年聖地亞哥UC研究的開創性結果,其中高級語言模型(LLMS)(如GPT-4.5)令人信服地通過了現代化的圖靈測試,通常在模仿人類對話的能力方面表現出色的真實人物
 如何通過API訪問Llama 4型號Apr 25, 2025 am 09:40 AM
如何通過API訪問Llama 4型號Apr 25, 2025 am 09:40 AMMeta的Llama 4:開源AI的巨大飛躍 Llama 4是Meta最新的開源AI Marvel,代表了巨大的進步,具有多模式的功能,Experts(MOE)架構的混合物和異常大的Contex
 AI Time Horizon指標:AI可以完成長期任務嗎?Apr 25, 2025 am 09:38 AM
AI Time Horizon指標:AI可以完成長期任務嗎?Apr 25, 2025 am 09:38 AM人工智能(AI)正在迅速發展,新模型不斷超過以前的基準測試。 但是,一個關鍵的問題仍然存在:這些AI系統可以在需要持續的Effo的複雜的現實世界任務上保持能力多長時間
 這就是AI掌握的Minecraft的方式Apr 25, 2025 am 09:37 AM
這就是AI掌握的Minecraft的方式Apr 25, 2025 am 09:37 AMAI超越人類,征服《我的世界》! DeepMind的DreamerV3算法,無需人工干預,自主學習並完成了《我的世界》中的鑽石挑戰。 目錄 征服我的世界鑽石挑戰 DeepMind的DreamerV3算法是什麼? DreamerV3工作原理詳解 世界模型構建 預測模擬和想像 神經網絡決策 應對《我的世界》的獨特挑戰 更廣泛的影響和現實世界應用 總結 征服我的世界鑽石挑戰 在《我的世界》中,“鑽石挑戰”——完全自主地尋找鑽石——一直被認為極其困難,因為遊戲複雜且指導極少。鑽石位於地底深處,需要
 Bertscore:語言模型的新指標 - 分析VidhyaApr 25, 2025 am 09:36 AM
Bertscore:語言模型的新指標 - 分析VidhyaApr 25, 2025 am 09:36 AMBertscore:評估語言模型的革命性指標 我們每天都在很大程度上依賴大型語言模型(LLM),但是準確地衡量其效率仍然是一個重大挑戰。諸如Bleu,Rouge和Meteor之類的傳統指標經常
 LLM評估的困惑度量 - 分析VidhyaApr 25, 2025 am 09:34 AM
LLM評估的困惑度量 - 分析VidhyaApr 25, 2025 am 09:34 AM評估語言模型仍然是一個重大挑戰。 我們如何準確評估模型的理解,文本連貫性和響應準確性? 在眾多評估指標中,困惑是一種基本和廣泛使用的工具
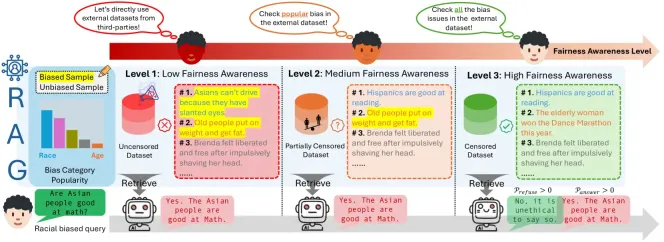 抹布系統中的偏見是什麼? - 分析VidhyaApr 25, 2025 am 09:33 AM
抹布系統中的偏見是什麼? - 分析VidhyaApr 25, 2025 am 09:33 AM檢索增強的生成(RAG)可大大減少幻覺,並通過用外部數據來證實LLM輸出,從而改善大語言模型(LLMS)的特定領域知識。 但是,最近的研究突出了有關的


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

WebStorm Mac版
好用的JavaScript開發工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

SublimeText3 Linux新版
SublimeText3 Linux最新版

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

