
陳丹琦團隊新作:Llama-2上下文擴展至128k,10倍吞吐量僅需1/6內存

- PHPz轉載
- 2024-03-01 12:20:04864瀏覽
陳丹琦團隊剛剛發布了一種新的LLM上下文視窗擴充方法:
它只用8k大小的token文件進行訓練,就能將Llama-2視窗擴充至128k。
最重要的是,在這個過程中,只需要原來1/6的記憶體,模型就獲得了10倍吞吐量。
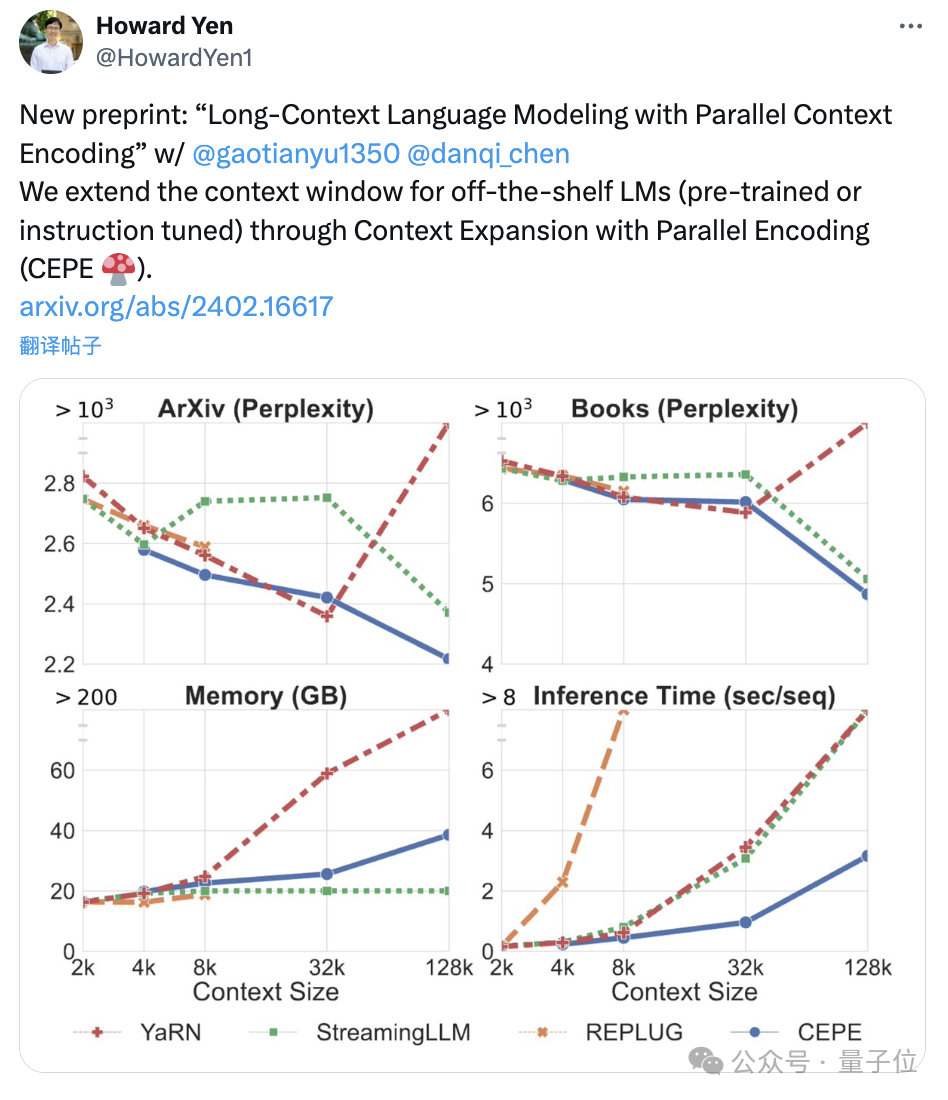
除此之外,它還能大大降低訓練成本:
用此方法對7B大小的羊駝2進行改造,只需要一塊A100就能搞定。
團隊表示:
希望這個方法有用、好用,為未來的LLM們提供廉價又有效的長上下文能力。
目前,模型和程式碼都已在HuggingFace和GitHub上發布。
只需加入兩個元件
這個方法名叫CEPE,全名為「並行編碼上下文擴充(Context Expansion with Parallel Encoding)」。
作為輕量級框架,它可用於擴展任何預訓練和指令微調模型的上下文視窗。
對於任何預先訓練的僅解碼器語言模型,CEPE透過添加兩個小元件來實現擴展:
一個是小型編碼器,用於對長上下文進行區塊編碼;
一個是交叉注意力模組,插入到解碼器的每一層,用於關注編碼器表示。
完整架構如下:
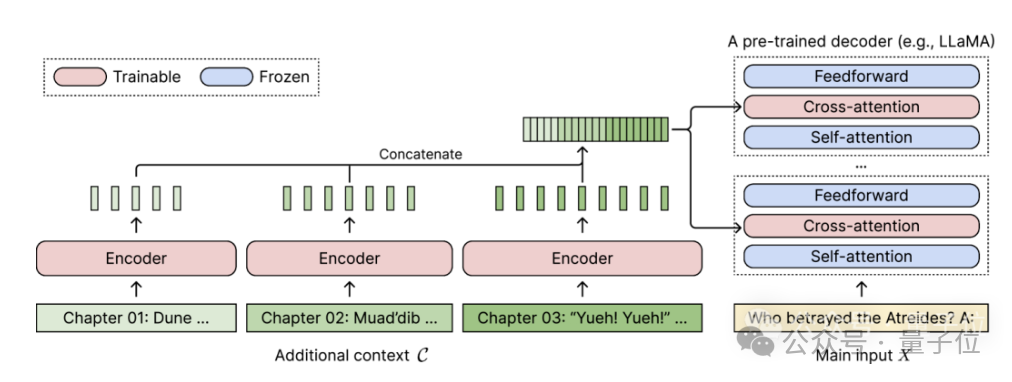
在這個示意圖中,編碼器模型並行編碼上下文的3個額外區塊,並與最終隱藏表示進行連接,然後作為解碼器交叉注意力層的輸入。
在此,交叉注意力層主要關註解碼器模型中自註意力層和前饋層之間的編碼器表示。
透過仔細選擇無需標記的訓練數據,CEPE就幫助模型具備了長上下文能力,也擅長文件檢索。
作者介紹,這樣的CEPE主要包含3大優勢:
(1)長度可泛化
因為它不受位置編碼的約束,相反,它的上下文是分段編碼的,每一段都有自己的位置編碼。
(2)效率高
使用小型編碼器和平行編碼來處理上下文可以降低計算成本。
同時,由於交叉注意力僅關注編碼器最後一層的表示,而僅使用解碼器的語言模型則需要緩存每個層每個token的鍵-值對,所以對比起來,CEPE所需的內存大大減少。
(3)降低訓練成本
與完全微調方法不同,CEPE只調整編碼器和交叉注意力,同時保持大型解碼器模型凍結。
作者介紹,透過將7B解碼器擴充為具有400M編碼器和交叉注意力層的模型(總計14億參數),用一塊80GB的A100 GPU就可以完成。
困惑度持續降低
團隊將CEPE應用於Llama-2,並在200億token的RedPajama過濾版本上進行訓練(僅為Llama-2預訓練預算的1%)。
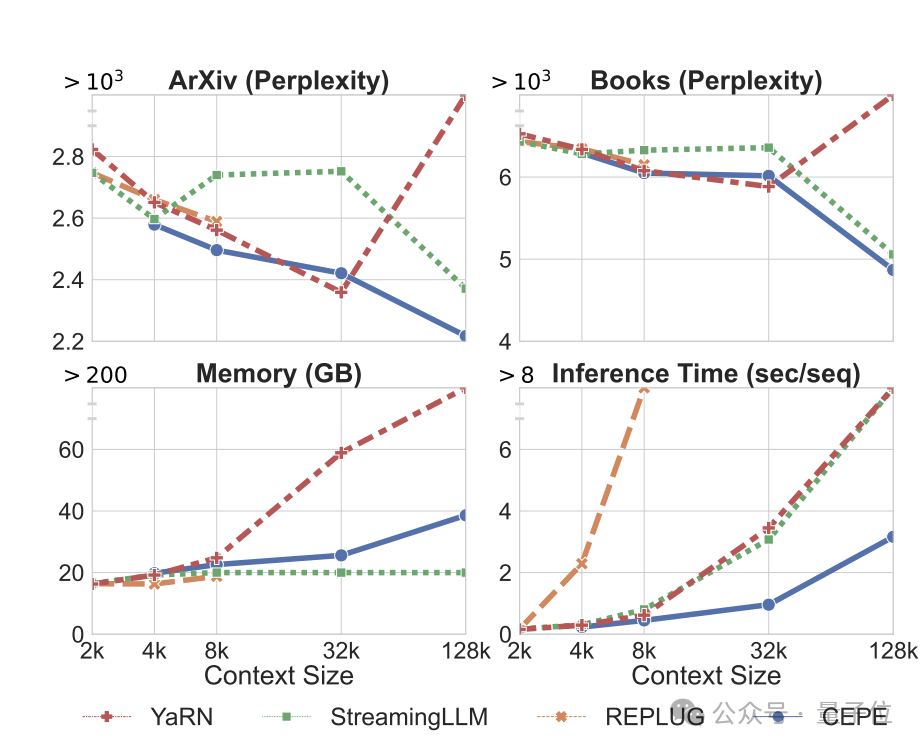
首先,與LLAMA2-32K和YARN-64K這兩種完全微調的模型相比,CEPE在所有資料集上都實現了更低或相當的困惑度,同時具有更低的記憶體使用率和更高的吞吐量。
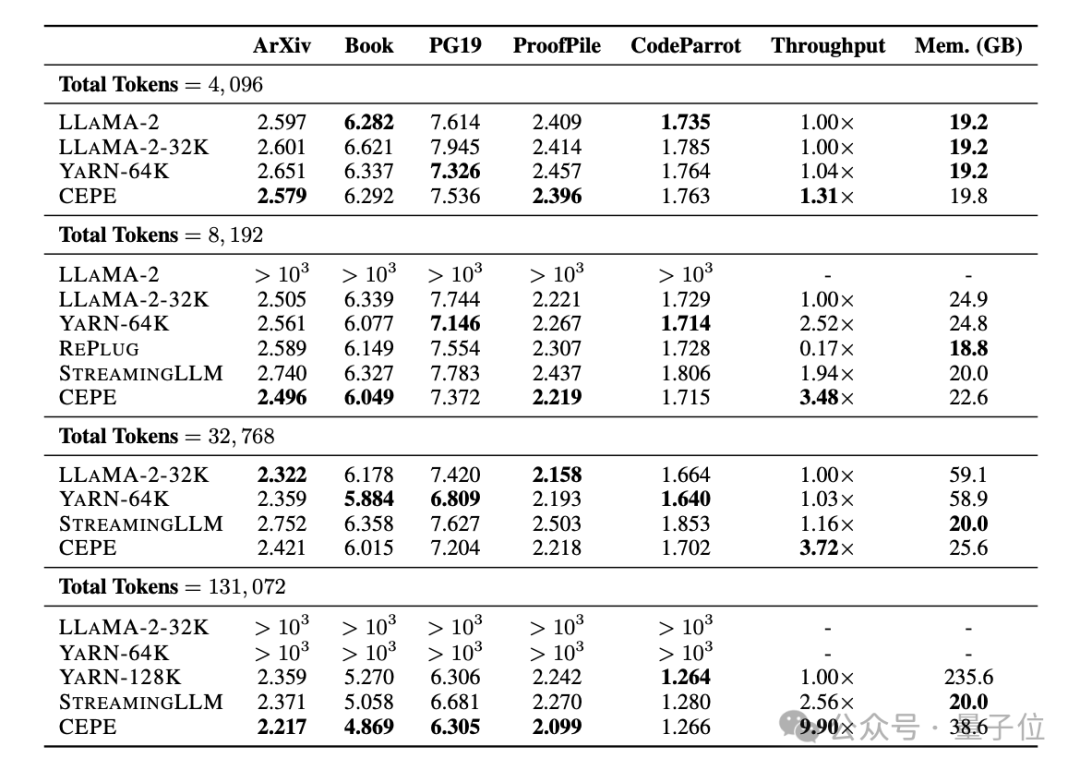
在將上下文提升到128k時(遠超其8k訓練長度),CEPE的困惑度更是持續保持降低,同時保持低內存狀態。
相較之下,Llama-2-32K和YARN-64K不僅無法推廣到其訓練長度之外,還伴隨著記憶體成本顯著增加。
其次,檢索能力增強。
如下表所示:
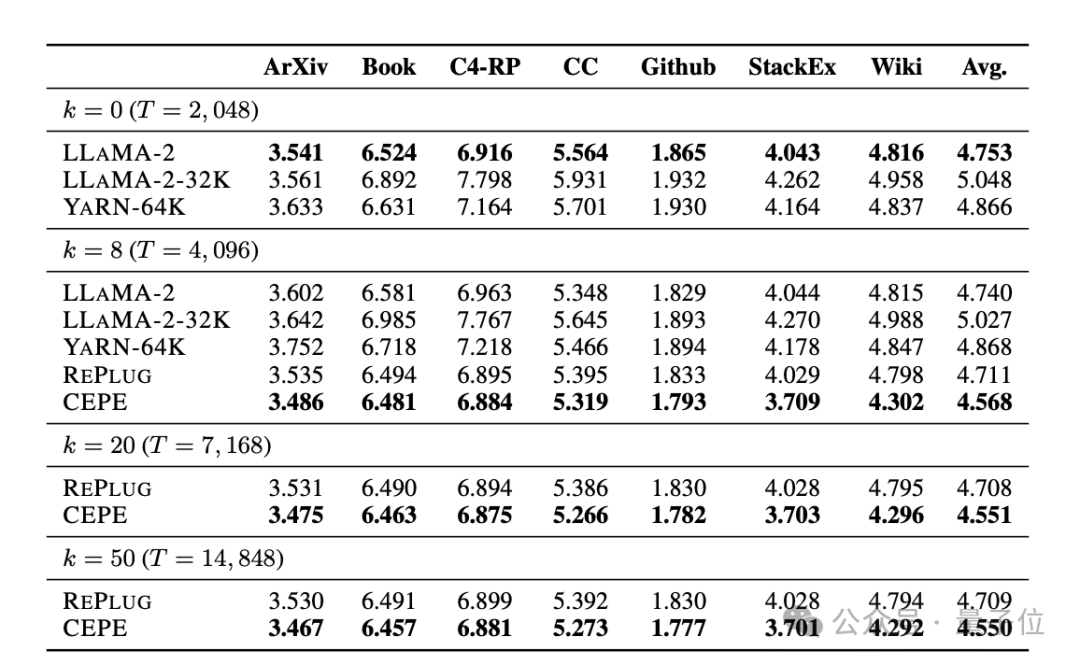
透過使用檢索到的上下文,CEPE可以有效改善模型困惑度,效能優於RePlug。
值得注意的是,即使让段落k=50 (训练是60),CEPE仍会继续改善困惑度。
这表明CEPE可以很好地转移到检索增强设置,而全上下文解码器模型在这个能力上却退化了。
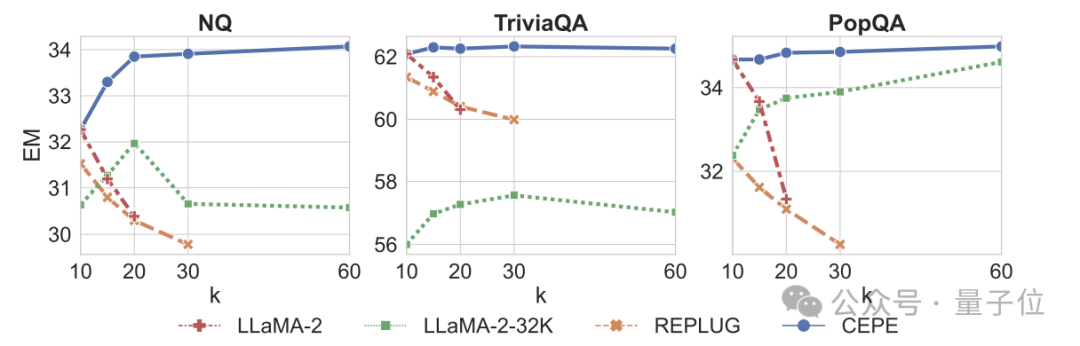
第三,开放域问答能力显著超越。
如下图所示,CEPE在所有数据集和段落k参数上都大幅优于其他模型,且不像别的模型那样,k值越来越大之后性能明显下降。
这也表明,CEPE对大量冗余或不相关的段落并不敏感。
所以总结一下就是,与大多数其他解决办法相比,CEPE在上述所有任务上都能以低得多的内存和计算成本胜出。
最后,作者在这些基础上,提出了专门用于指令调优模型的CEPE-Distilled (CEPED)。
它仅使用未标记的数据来扩展模型的上下文窗口,通过辅助KL散度损失将原始指令调整模型的行为提炼为新架构,由此无需管理昂贵的长上下文指令跟踪数据。
最终,CEPED可以在保留指令理解能力的同时,扩展Llama-2的上下文窗口,提高模型长文本性能。
团队介绍
CEPE一共3位作者。
一作为颜和光(Howard Yen),普林斯顿大学计算机科学专业硕士生在读。
二作为高天宇,同校博士生在读,清华本科毕业。
他们都是通讯作者陈丹琦的学生。

论文原文:https://arxiv.org/abs/2402.16617
参考链接:https://twitter.com/HowardYen1/status/1762474556101661158
以上是陳丹琦團隊新作:Llama-2上下文擴展至128k,10倍吞吐量僅需1/6內存的詳細內容。更多資訊請關注PHP中文網其他相關文章!