



眾所周知,大型語言模型(LLM)的推理通常需要使用自迴歸取樣,這個推理過程相當緩慢。為了解決這個問題,推測解碼(Speculative Decoding)已經成為 LLM 推理的一種新型取樣方法。這種方法在每個採樣步驟中,會先預測幾個可能的 token,然後並行地驗證是否準確。與自迴歸解碼不同,推測解碼能夠單步解碼多個 token,從而加速推理。
儘管推測解碼在許多方面都表現出巨大潛力,但也帶來了一些需要深入研究的關鍵問題。首先,我們需要思考如何選擇或設計適當的近似模型,以在推測的準確性和生成的效率之間取得平衡。其次,重要的是確保評估標準能夠同時維持生成結果的多樣性和品質。最後,必須認真考慮近似模型和目標大模型之間的推理過程的對齊,以提高推理的準確性。
來自香港理工大學、北京大學、MSRA以及阿里的研究者對推測解碼進行了全面的研研,機器之心對此進行了綜合總結。

- #論文標題:Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
- 論文網址:https://arxiv.org/pdf/2401.07851.pdf
#推測解碼的演化之路
文章首先詳細介紹了推測解碼技術的早期研究情況,並透過時間表展示了其發展歷程(見圖2) 。
分塊取樣(Blockwise Decoding)是一種在 Transformer 解碼器上整合額外前饋神經(FFN)頭的方法,能夠單步產生多個 token。
為了進一步充分發揮分塊取樣演算法的潛力,提出了推測解碼的解決方案。這種演算法涵蓋了一個獨立的近似模型,通常採用專門的非自回歸 Transformer,能夠有效率且精確地執行生成任務。
繼推測解碼出現之後,有學者接著提出了「投機採樣演算法」(Speculative Sampling),在推測解碼中加入了無損加速核採樣。
總的來說,這些關於推測解碼的創新嘗試已經開始加強 Draftthen-Verify 範式,並且展示了在 LLM 加速方面的巨大潛能。

公式和定義
本節首先簡要概述了標準自回歸解碼的內容,然後深入闡述了推測解碼演算法,包括對形式定義、方法論的全面描述以及演算法的詳細闡述。
本文提出了一個組織架構來對相關研究進行分類,如下圖 3 所示。

本文在前人的基礎上,對「推測解碼演算法」再次進行了正式的定義:
#推測解碼演算法是一種先生成後驗證的解碼模式,在每個解碼步驟,它首先需要能產生多個可能的token,然後使用目標大語言模型並行地評估所有這些token,以加快推理速度。演算法表 2 是一個詳細的推測解碼過程。

隨後,本文深入研究了這個典範不可或缺的兩個基本子步驟— 產生與評估。
產生
#在每個解碼步驟中,推測解碼演算法首先會生成多個可能的token,作為對目標大語言模型的輸出內容的推測。
本文將產生的內容分為兩類:獨立生成(independent drafting )和自生成(self-drafting),並在下表 1 中總結了其公式。

驗證
在每個解碼步驟中,並行驗證近似模型產生的token,以確保輸出品質與目標大語言模型高度一致。這個過程也確定了每一步可允許的 token 數量,這是一個能夠影響加速情況的一個重要因素。
對各種驗證標準的總結如下表 2 所示,包括那些在大語言模型推理中支持貪心解碼和核採樣的標準。

產生和驗證的子步驟會持續迭代,直到滿足終止條件為止,即[EOS] token 被解碼或句子達到最大長度。
此外,本文引入了 token 的樹驗證演算法,這是一種逐步提高 token 接受度的有效策略。
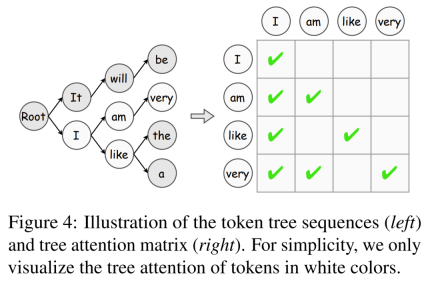
模型對齊
#提高推測準確度是加速推測解碼的關鍵:近似模型的預測行為越接近目標大語言模型,對其產生token 的接受率就越高。為此,現有的工作探索了各種知識提取(KD)策略,以使近似模型的輸出內容與目標大語言模型的輸出內容保持一致。
分塊解碼首先採用序級知識擷取(Seq-KD)來進行模型對齊,以目標大語言模型產生的句子訓練近似模型。
此外,Seq-KD 也是提高平行解碼產生品質的有效策略,提高了平行解碼的生成效能。
下表 3 中總結了現有推測解碼方法的主要特徵,包括近似模型的類型或生成策略、模型對齊方法、支援的評估策略和加速程度等情況。

應用程式
#除了作為一種通用範式外,最近的工作還表明,推測解碼的一些變體在特定任務中表現出非凡的有效性。此外,其他研究已經將這種範式應用於解決某些應用情境特有的延遲問題,從而實現推理加速。
例如,有些學者認為,推測解碼特別適合模型輸入和輸出高度相似的任務,如語法糾錯和檢索增強生成。
除了這些工作之外,RaLMSpec(Zhang et al., 2023b)用推測解碼來加速檢索增強語言模型(RaLMs)。
機會與挑戰
問題 1:如何權衡預測內容的準確度與產生效率?儘管目前對這個問題取得了一些進展,但在使近似模型與目標大語言模型生成內容保持一致方面仍有相當大的改進空間。除了模型對齊之外,其他因素(如產生品質和預測長度的確定)也會影響推測的準確性,值得進一步探索。
問題 2:如何將推測解碼與其他領先技術結合?作為一種通用的解碼模式,推測解碼已經與其他先進技術相結合,展示了其潛力。除了加速純文字的大語言模型之外,推測解碼在多模式推理中的應用,如圖像合成、文字轉語音合成和視訊生成,也是未來研究的一個有趣而有價值的方向。
更多細節內容請參閱原文。
以上是GPT-4可能也在用的推測解碼是什麼?一文綜述前世今生與應用情況的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Llama 4與GPT-4O:哪個更好?Apr 26, 2025 am 09:37 AM
Llama 4與GPT-4O:哪個更好?Apr 26, 2025 am 09:37 AM本文比較了Meta的Llama 4 Scout和OpenAI的GPT-4O在檢索效果(RAG)系統中的性能。 該評估利用Ragas框架,為忠誠,回答相關性和背景預先提供指標
 生成的人工智能和人類聯繫改變關係 - 分析vidhyaApr 26, 2025 am 09:36 AM
生成的人工智能和人類聯繫改變關係 - 分析vidhyaApr 26, 2025 am 09:36 AM2025年:生成的AI從生產力工具發展到個人同伴 Generative AI的角色在2025年大大擴展,超越了簡單的生產力任務,成為個人生活中的重要領域。而其提高效率
 如何在Google表中使用雙子座?Apr 26, 2025 am 09:34 AM
如何在Google表中使用雙子座?Apr 26, 2025 am 09:34 AMGoogle表可以通過引入Gemini's = AI功能,自動化以前需要手動努力的數據任務進行了重大升級。這種AI驅動的公式簡化了通過簡單的分類,匯總和公式開發
 Python One Liners數據清潔:快速指南 - 分析VidhyaApr 26, 2025 am 09:33 AM
Python One Liners數據清潔:快速指南 - 分析VidhyaApr 26, 2025 am 09:33 AM使用Python單線使數據清潔變得容易 用強大的Python單線簡化數據清潔過程!本指南展示了用於處理缺失價值,重複,格式化問題等基本熊貓技術
 為您的任務選擇最佳AI聊天機器人的指南Apr 26, 2025 am 09:31 AM
為您的任務選擇最佳AI聊天機器人的指南Apr 26, 2025 am 09:31 AM您如何跟踪最新的LLM?如果您一直在跟踪新聞,那麼我確定您對那裡的模型不知所措,尤其是在過去的幾個月中。今天,我們的AI聊天機器人比FI更多
 14個強大的技術定義嵌入的演變-Analytics VidhyaApr 26, 2025 am 09:29 AM
14個強大的技術定義嵌入的演變-Analytics VidhyaApr 26, 2025 am 09:29 AM本文探討了文本嵌入的演變,從簡單的基於計數的方法到復雜的上下文感知模型。 它突出了MTEB等排行榜在評估嵌入性能和尖端的可及性中的作用
 O3 vs O4 -Mini vs Gemini 2.5 Pro:終極推理戰 - 分析VidhyaApr 26, 2025 am 09:28 AM
O3 vs O4 -Mini vs Gemini 2.5 Pro:終極推理戰 - 分析VidhyaApr 26, 2025 am 09:28 AM該博客將三個領先的AI模型(O3,O4-Mini和Gemini 2.5 Pro)置於嚴格的推理挑戰中。 我們在物理,數學,編碼,網頁設計和圖像分析中測試它們的能力,揭示了它們的優勢
 在Yolo -Analytics Vidhya中進行有效的重新ID跟踪Apr 26, 2025 am 09:26 AM
在Yolo -Analytics Vidhya中進行有效的重新ID跟踪Apr 26, 2025 am 09:26 AMYOLO,SSD和DETR等實時對象檢測工具對於監視對象運動和動作至關重要。 交通管理和安全等行業利用這些工具來跟踪和分析。但是,一個主要挑戰是維護


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

WebStorm Mac版
好用的JavaScript開發工具

Atom編輯器mac版下載
最受歡迎的的開源編輯器

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

