
後Sora時代,CV從業人員如何選擇模型?卷積還是ViT,監督學習還是CLIP範式

- PHPz轉載
- 2024-02-19 09:57:021043瀏覽
ImageNet准确率曾是评估模型性能的主要指标,但在当今计算视觉领域,这一指标逐渐显得不够完善。
随着计算机视觉模型变得更加复杂,可用模型种类已显著增加,从ConvNets到Vision Transformers。训练方法也发展到自监督学习和像CLIP这样的图像-文本对训练,不再局限于ImageNet上的监督训练。
ImageNet的准确率虽然是一个重要指标,但并不足以全面评估模型的性能。不同的架构、训练方式和数据集可能会导致模型在不同任务上表现出差异,因此仅仅依靠ImageNet来评判模型可能存在局限性。当模型过度拟合ImageNet数据集并准确率达到饱和时,就可能忽略了模型在其他任务上的泛化能力。因此,需要综合考虑多方面因素来评估模型的性能和适用性。
虽然 CLIP 的 ImageNet 准确率与 ResNet 相似,但其视觉编码器的稳健性和可迁移性较优。这促使研究人员探索 CLIP 的独特优势,而这些优势在仅考虑 ImageNet 指标时并不明显。这突显了分析其他属性有助于发现有用模型的重要性。
除此之外,传统的基准测试无法全面评估模型处理真实世界视觉挑战的能力,如各种相机角度、光线条件或遮挡情况。以ImageNet等数据集训练的模型,通常难以在实际应用中发挥其性能,因为现实世界的条件和场景更为多样化。
这些问题,为领域内的从业者带来了新的困惑:如何衡量一个视觉模型?又如何选择适合自己需求的视觉模型?
在最近的一篇论文中,MBZUAI 和 Meta 的研究者对这一问题开展了深入讨论。

- 论文标题:ConvNet vs Transformer, Supervised vs CLIP:Beyond ImageNet Accuracy
- 论文链接:https://arxiv.org/pdf/2311.09215.pdf
研究集中于ImageNet准确性之外的模型行为,分析了计算机视觉领域中主要模型的表现,包括ConvNeXt和Vision Transformer (ViT),这两个模型在监督和CLIP训练范式下的表现。
所选模型的参数数量相似,且在每种训练范式下对 ImageNet-1K 的准确率几乎相同,确保了比较的公平性。研究者深入探讨了一系列模型特性,如预测误差类型、泛化能力、习得表征的不变性、校准等,重点关注了模型在没有额外训练或微调的情况下表现出的特性,为希望直接使用预训练模型的从业人员提供了参考。
在分析中,研究者发现不同架构和训练范式的模型行为存在很大差异。例如,模型在 CLIP 范式下训练的分类错误少于在 ImageNet 上训练。不过,监督模型的校准效果更好,在 ImageNet 稳健性基准测试中普遍更胜一筹。ConvNeXt 在合成数据上有优势,但比 ViT 更偏重纹理。同时,有监督的 ConvNeXt 在许多基准测试中表现出色,其可迁移性表现与 CLIP 模型相当。
可以看出,各种模型以独特的方式展现了自己的优势,而这些优势是单一指标无法捕捉到的。研究者强调,需要更详细的评估指标来准确选择特定情境下的模型,并创建与 ImageNet 无关的新基准。
基于这些观察,Meta AI 首席科学家 Yann LeCun 转发了这项研究并点赞:

模型選擇
對於監督模型,研究者使用了ViT 的預訓練DeiT3- Base/16,它與ViT-Base/16 架構相同,但訓練方法有所改進;此外還使用了ConvNeXt-Base。對於 CLIP 模型,研究者使用了 OpenCLIP 中 ViT-Base/16 和 ConvNeXt-Base 的視覺編碼器。
請注意,這些模型的效能與原始的 OpenAI 模型略有不同。所有模型檢查點都可以在 GitHub 專案主頁中找到。詳細的模型比較見表1:

對於模型的選擇過程,研究者做出了詳細解釋:
#1、由於研究者使用的是預訓練模型,因此無法控制訓練期間所見資料樣本的數量和品質。
2、為了分析 ConvNets 和 Transformers,先前的許多研究都對 ResNet 和 ViT 進行了比較。這種比較通常對 ConvNet 不利,因為 ViT 通常採用更先進的配方進行訓練,能達到更高的 ImageNet 準確率。 ViT 還有一些架構設計元素,例如 LayerNorm,這些元素在多年前 ResNet 被發明時並沒有納入其中。因此,為了進行更平衡的評估,研究者將 ViT 與 ConvNeXt 進行了比較,後者是 ConvNet 的現代代表,其性能與 Transformers 相當,並共享了許多設計。
3、在訓練模式方面,研究者比較了監督模式和 CLIP 模式。監督模型在電腦視覺領域一直保持最先進的性能。另一方面,CLIP 模型在泛化和可遷移性方面表現出色,並提供了連接視覺和語言表徵的特性。
4、由於自監督模型在初步測試中表現出與監督模型類似的行為,因此未被納入結果中。這可能是由於它們最終在 ImageNet-1K 上進行了有監督的微調,而這會影響許多特性的研究。
接下來,我們看下研究者如何對不同的屬性進行了分析。
分析
#模型錯誤
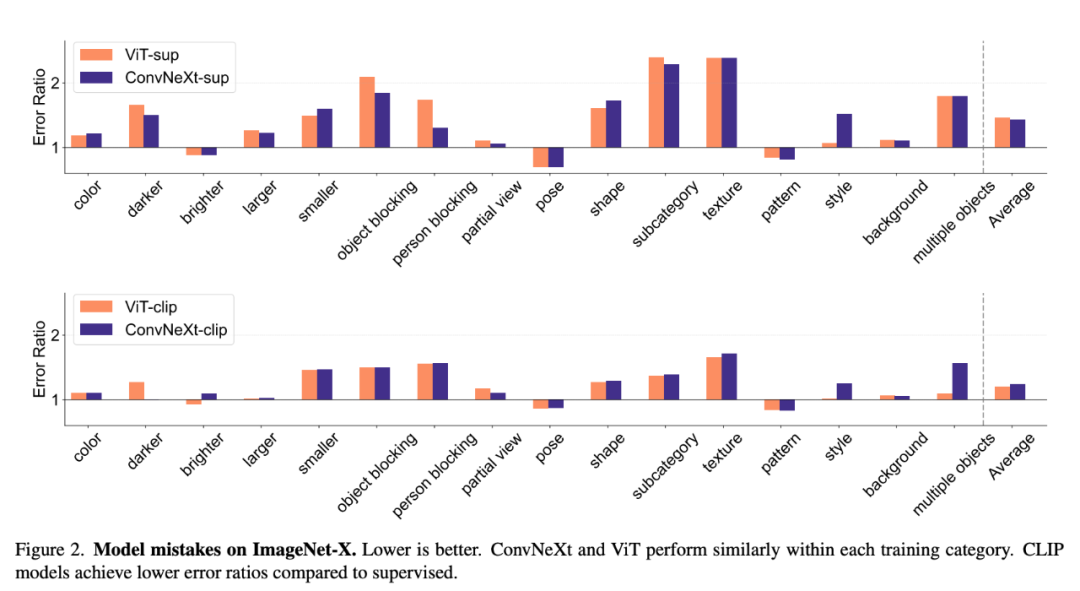
ImageNet-X 是一個對ImageNet-1K 進行擴展的資料集,其中包含對16 個變化因素的詳細人工註釋,可對影像分類中的模型錯誤進行深入分析。它採用錯誤比例度量(越低越好)來量化模型在特定因素上相對於整體準確性的表現,從而對模型錯誤進行細緻入微的分析。 ImageNet-X 的結果顯示:
1. 相對於監督模型,CLIP 模型在 ImageNet 準確性方面犯的錯誤較少。
2. 所有模型都主要受到遮蔽等複雜因素的影響。
3. 紋理是所有模型中最具挑戰性的因素。
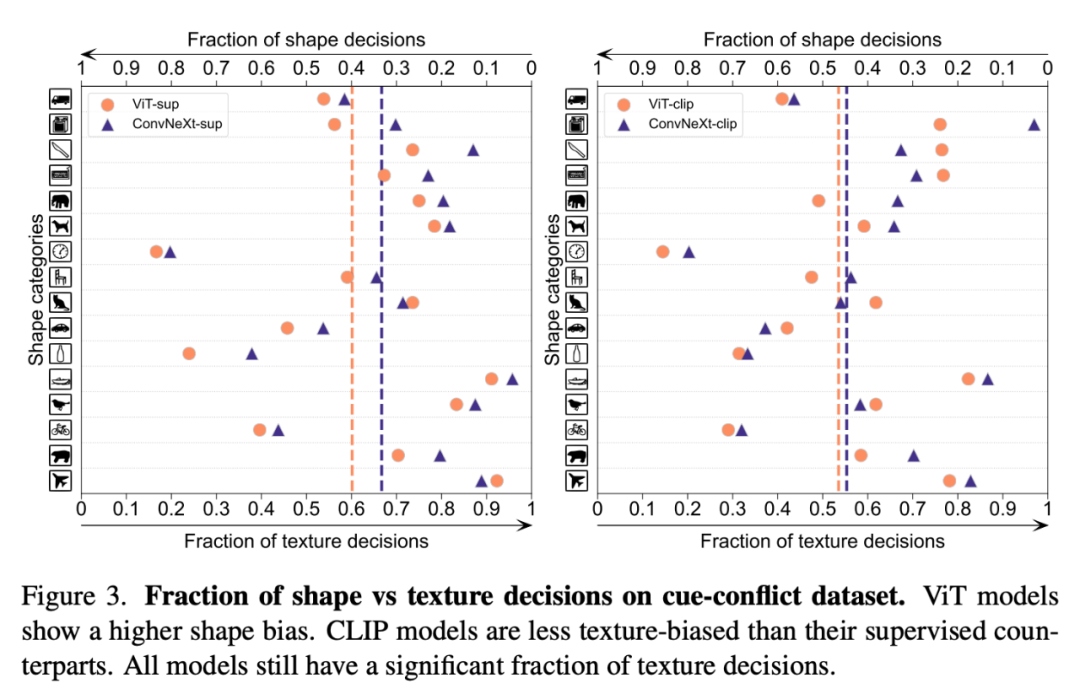
」形狀/ 紋理偏差
」偵測模型是否依賴脆弱的紋理捷徑,而不是高級形狀線索。這種偏差可以透過結合不同類別的形狀和紋理的線索衝突圖像來研究。這種方法有助於了解,與紋理相比,模型的決策在多大程度上是基於形狀的。研究者對線索衝突資料集上的形狀 - 紋理偏差進行了評估,發現 CLIP 模型的紋理偏差小於監督模型,而 ViT 模型的形狀偏差高於 ConvNets。
模型校準
#校準可量化模型的預測置信度與其實際準確度是否一致,可以透過預期校準誤差(ECE) 等指標以及可靠性圖和置信度直方圖等視覺化工具進行評估。研究者在 ImageNet-1K 和 ImageNet-R 上對校準進行了評估,將預測分為 15 個等級。在實驗中,研究者觀察到以下幾點:######
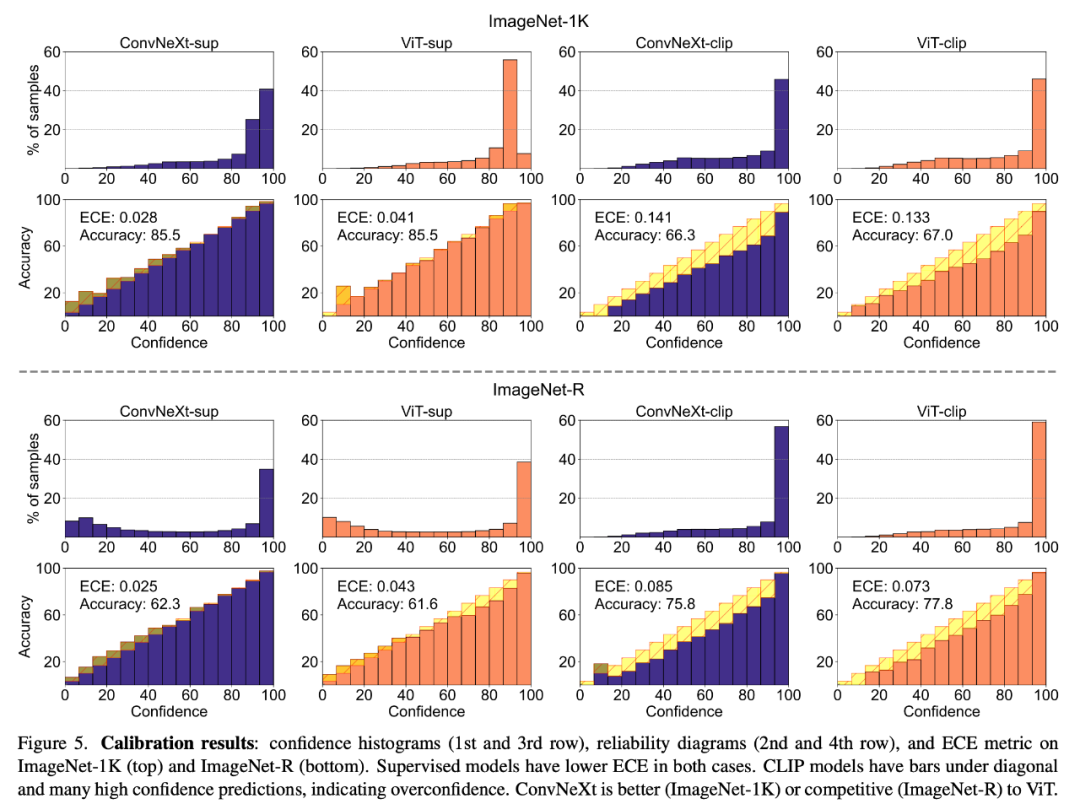
1. CLIP 模型過於自信,而監督模型則略顯不足。
2. 有監督的 ConvNeXt 比有監督的 ViT 校準效果更好。
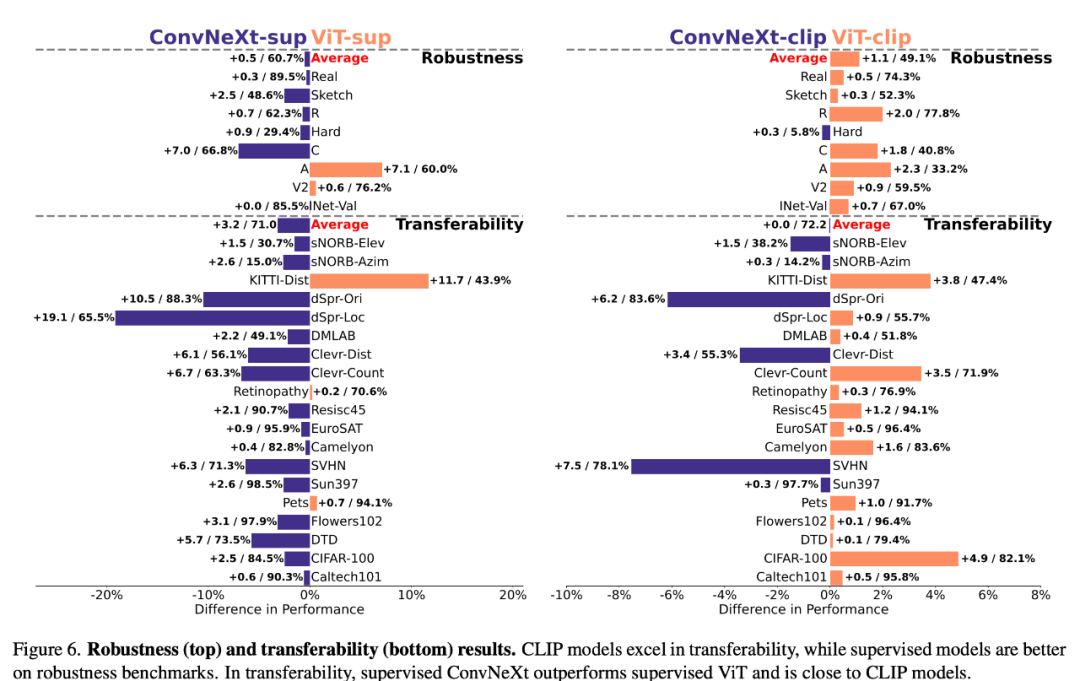
穩健性和可遷移性
#模型的穩健性和可遷移性對於適應資料分佈變化和新任務至關重要。研究者使用各種ImageNet 變體對穩健性進行了評估,結果發現,雖然ViT 和ConvNeXt 模型的平均性能相當,但除ImageNet-R 和ImageNet-Sketch 外,有監督模型在穩健性方面普遍優於CLIP 。在可遷移性方面,透過使用 19 個資料集的 VTAB 基準進行評估,有監督的 ConvNeXt 優於 ViT,幾乎與 CLIP 模型的效能相當。
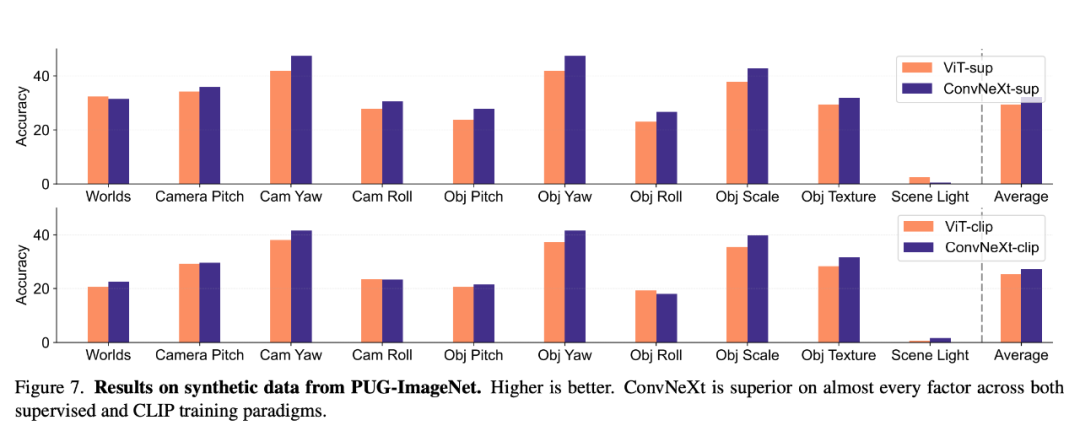
合成資料
#PUG-ImageNet 等合成資料集可以精確控制攝影機角度和紋理等因素,是一種很有前景的研究路徑,因此研究者分析了模型在合成資料上的表現。 PUG-ImageNet 包含逼真的 ImageNet 影像,姿態和光照等因素存在系統性變化,效能以絕對 top-1 準確率為衡量標準。研究者提供了 PUG-ImageNet 中不同因素的結果,發現 ConvNeXt 在幾乎所有因素上都優於 ViT。這表明 ConvNeXt 在合成資料上優於 ViT,而 CLIP 模型的差距較小,因為 CLIP 模型的準確率低於監督模型,這可能與原始 ImageNet 的準確率較低有關。
#變換不變性
變換不變性是指模型能夠產生一致的表徵,不受輸入變換的影響從而保留語義,如縮放或移動。這一特性使模型能夠在不同但語義相似的輸入中很好地泛化。研究者使用的方法包括調整影像大小以實現比例不變性,移動 crops 以實現位置不變性,以及使用插值位置嵌入調整 ViT 模型的解析度。
他們在 ImageNet-1K 上透過改變 crop 比例 / 位置和影像解析度來評估比例、移動和解析度的不變性。在有監督的訓練中,ConvNeXt 的表現優於 ViT。整體而言,模型對規模 / 解析度變換的穩健性高於對移動的穩健性。對於需要對縮放、位移和解析度具有較高穩健性的應用,結果表明監督的 ConvNeXt 可能是最佳選擇。

總結
#整體來說,每種模型都有自己獨特的優點。這表明模型的選擇應取決於目標用例,因為標準效能指標可能會忽略特定任務的關鍵細微差別。此外,許多現有的基準都來自於 ImageNet,這也會讓評估產生偏差。開發具有不同數據分佈的新基準對於在更具現實世界代表性的環境中評估模型至關重要。
以下是本文結論的概括:
#ConvNet 與Transformer
##1. 在許多基準上,監督ConvNeXt 的性能都優於監督ViT:它的校準效果更好,對資料轉換的不變性更高,並表現出更好的可遷移性和穩健性。
2. ConvNeXt 在合成資料上的表現優於 ViT。
3. ViT 的形狀偏差較大。
監督與CLIP
1. 儘管CLIP 模型在可轉移性方面更勝一籌,但有監督的ConvNeXt 在這項任務中展現了競爭力。這展示了有監督模型的潛力。
2. 有監督模型在穩健性基準方面表現較好,這可能是因為這些模型都是 ImageNet 變體。
3. CLIP 模型的形狀偏差較大,與 ImageNet 的準確度相比,分類錯誤較少。
以上是後Sora時代,CV從業人員如何選擇模型?卷積還是ViT,監督學習還是CLIP範式的詳細內容。更多資訊請關注PHP中文網其他相關文章!