
Linux 核心的 CPU 負載平衡機制:原理、流程與最佳化

- 王林轉載
- 2024-02-09 13:50:111219瀏覽
CPU 負載平衡是指在多核心或多處理器的系統中,將運行中的進程或任務分配到不同的CPU 上,使得每個CPU 的負載盡可能地平衡,從而提高系統的效能和效率。 CPU 負載平衡是 Linux 核心的重要功能,它可以讓 Linux 系統充分利用多核心或多處理器的優勢,適應不同的應用場景和需求。但是,你真的了解 Linux 核心的 CPU 負載平衡機制嗎?你知道它的工作原理、流程和最佳化方法嗎?本文將為你詳細介紹 Linux 核心的 CPU 負載平衡機制的相關知識,讓你在 Linux 下更能運用並理解這個強大的核心功能。
還是神奇的進程調度問題引發的,參考Linux進程組調度機制分析,組調度機制是看清楚了,發現在重啟過程中,很多內核呼叫棧阻塞在了double_rq_lock函數上,而double_rq_lock則是load_balance觸發的,懷疑當時的核間調度出現了問題,在某個負責場景下產生了多核心互鎖,後面看了一下CPU負載平衡下的程式碼實現,寫一下總結。
核心程式碼版本:kernel-3.0.13-0.27。
核心程式碼函數起自load_balance函數,從load_balance函數看引用它的函數可以一直找到schedule函數這裡,便從這裡開始往下看,在__schedule中有下面一句話。
if (unlikely(!rq->nr_running)) idle_balance(cpu, rq);
從上面可以看出什麼時候核心會嘗試進行CPU負載平衡:也就是目前CPU運行佇列為NULL的時候。
CPU負載平衡有兩種方式:pull和push,也就是空閒CPU從其他忙碌的CPU佇列中拉一個行程到目前CPU佇列;或者忙碌的CPU佇列將一個行程推送到空閒的CPU佇列中。 idle_balance幹的則是pull的事情,具體push下面會提到。
在idle_balance裡面,有一個proc閥門控制目前CPU是否pull:
if (this_rq->avg_idle return;
sysctl_sched_migration_cost對應proc控制檔是/proc/sys/kernel/sched_migration_cost,開關代表如果CPU佇列空閒了500us(sysctl_sched_migration_cost預設值)以上,則進行pull,否則則回傳。
for_each_domain(this_cpu, sd) 則是遍歷目前CPU所在的調度域,可以直覺的理解成一個CPU群組,類似task_group,核間平衡指組內的平衡。負載平衡有一個矛盾就是:負載平衡的頻度和CPU cache的命中率是矛盾的,CPU調度域就是將各個CPU分成層次不同的組,低層次搞定的平衡就絕不上升到高層次處理,避免影響cache的命中率。
圖例如下;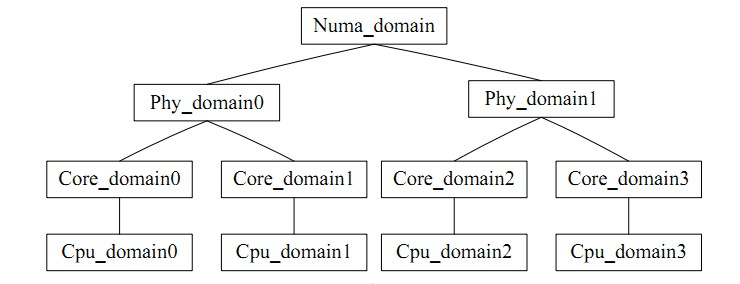
#最終透過load_balance進入正題。
首先透過find_busiest_group取得目前調度域中的最忙的調度組,首先update_sd_lb_stats更新sd的狀態,也就是遍歷對應的sd,將sds裡面的結構體資料填滿,如下:
struct sd_lb_stats {
struct sched_group *busiest; /* Busiest group in this sd */
struct sched_group *this; /* Local group in this sd */
unsigned long total_load; /* Total load of all groups in sd */
unsigned long total_pwr; /* Total power of all groups in sd */
unsigned long avg_load; /* Average load across all groups in sd */
/** Statistics of this group */
unsigned long this_load; //当前调度组的负载
unsigned long this_load_per_task; //当前调度组的平均负载
unsigned long this_nr_running; //当前调度组内运行队列中进程的总数
unsigned long this_has_capacity;
unsigned int this_idle_cpus;
/* Statistics of the busiest group */
unsigned int busiest_idle_cpus;
unsigned long max_load; //最忙的组的负载量
unsigned long busiest_load_per_task; //最忙的组中平均每个任务的负载量
unsigned long busiest_nr_running; //最忙的组中所有运行队列中进程的个数
unsigned long busiest_group_capacity;
unsigned long busiest_has_capacity;
unsigned int busiest_group_weight;
do
{
local_group = cpumask_test_cpu(this_cpu, sched_group_cpus(sg));
if (local_group) {
//如果是当前CPU上的group,则进行赋值
sds->this_load = sgs.avg_load;
sds->this = sg;
sds->this_nr_running = sgs.sum_nr_running;
sds->this_load_per_task = sgs.sum_weighted_load;
sds->this_has_capacity = sgs.group_has_capacity;
sds->this_idle_cpus = sgs.idle_cpus;
} else if (update_sd_pick_busiest(sd, sds, sg, &sgs, this_cpu)) {
//在update_sd_pick_busiest判断当前sgs的是否超过了之前的最大值,如果是
//则将sgs值赋给sds
sds->max_load = sgs.avg_load;
sds->busiest = sg;
sds->busiest_nr_running = sgs.sum_nr_running;
sds->busiest_idle_cpus = sgs.idle_cpus;
sds->busiest_group_capacity = sgs.group_capacity;
sds->busiest_load_per_task = sgs.sum_weighted_load;
sds->busiest_has_capacity = sgs.group_has_capacity;
sds->busiest_group_weight = sgs.group_weight;
sds->group_imb = sgs.group_imb;
}
sg = sg->next;
} while (sg != sd->groups);
決定選擇調度域中最忙的群組的參照標準是該組內所有CPU上負載(load) 的和, 找到組中找到忙的運行隊列的參照標準是該CPU運行隊列的長度, 即負載,且load 值越大就表示越忙。在平衡的過程中,透過比較目前隊列與先前記錄的busiest 的負載情況,及時更新這些變量,讓 busiest 始終指向域內最忙的一組,以便於查找。
調度域的平均負載計算
sds.avg_load = (SCHED_POWER_SCALE * sds.total_load) / sds.total_pwr; if (sds.this_load >= sds.avg_load) goto out_balanced;
在比較負載大小的過程中, 當發現目前執行的CPU所在的群組中busiest為空時,或目前正在執行的CPU佇列就是最忙的時, 或目前CPU佇列的負載不小於本組內的平均負載時,或不平衡的額度不大時,都會傳回NULL 值,即組組之間不需要進行平衡;當最忙的組的負載小於該調度域的平均負載時,只需要進行小範圍的負載平衡;當要轉移的任務量小於每個行程的平均負載時,如此便拿到了最忙的調度組。
然後find_busiest_queue中找到最忙碌的調度隊列,遍歷該組中的所有 CPU 隊列,依序比較各個隊列的負載,找到最忙碌的那個隊列。
or_each_cpu(i, sched_group_cpus(group)) {
/*rq->cpu_power表示所在处理器的计算能力,在函式sched_init初始化时,会把这值设定为SCHED_LOAD_SCALE (=Nice 0的Load Weight=1024).并可透过函式update_cpu_power (in kernel/sched_fair.c)更新这个值.*/
unsigned long power = power_of(i);
unsigned long capacity = DIV_ROUND_CLOSEST(power,SCHED_POWER_SCALE);
unsigned long wl;
if (!cpumask_test_cpu(i, cpus))
continue;
rq = cpu_rq(i);
/*获取队列负载cpu_rq(cpu)->load.weight;*/
wl = weighted_cpuload(i);
/*
* When comparing with imbalance, use weighted_cpuload()
* which is not scaled with the cpu power.
*/
if (capacity && rq->nr_running == 1 && wl > imbalance)
continue;
/*
* For the load comparisons with the other cpu's, consider
* the weighted_cpuload() scaled with the cpu power, so that
* the load can be moved away from the cpu that is potentially
* running at a lower capacity.
*/
wl = (wl * SCHED_POWER_SCALE) / power;
if (wl > max_load) {
max_load = wl;
busiest = rq;
}
透過上面的計算,便拿到了最忙隊列。
當busiest->nr_running運行數大於1的時候,進行pull操作,pull前對move_tasks,先進行double_rq_lock加鎖處理。
double_rq_lock(this_rq, busiest); ld_moved = move_tasks(this_rq, this_cpu, busiest, imbalance, sd, idle, &all_pinned); double_rq_unlock(this_rq, busiest);
move_tasks進程pull task是允許失敗的,即move_tasks->balance_tasks,在此處,有sysctl_sched_nr_migrate開關控制進程遷移個數,對應proc的是/proc/sys/kernel/sched_nr_migrate。
下面有can_migrate_task函數檢查選定的進程是否可以進行遷移,遷移失敗的原因有3個,1.遷移的進程處於運行狀態;2.進程被綁核了,不能遷移到目標CPU上;3.進程的cache仍然是hot,此處也是為了保證cache命中率。
/*关于cache cold的情况下,如果迁移失败的个数太多,仍然进行迁移
* Aggressive migration if:
* 1) task is cache cold, or
* 2) too many balance attempts have failed.
*/
tsk_cache_hot = task_hot(p, rq->clock_task, sd);
if (!tsk_cache_hot ||
sd->nr_balance_failed > sd->cache_nice_tries) {
#ifdef CONFIG_SCHEDSTATS
if (tsk_cache_hot) {
schedstat_inc(sd, lb_hot_gained[idle]);
schedstat_inc(p, se.statistics.nr_forced_migrations);
}
#endif
return 1;
}
判斷行程cache是否有效,判斷條件,行程的運作的時間大於proc控制開關sysctl_sched_migration_cost,對應目錄/proc/sys/kernel/sched_migration_cost_ns
static int
task_hot(struct task_struct *p, u64 now, struct sched_domain *sd)
{
s64 delta;
delta = now - p->se.exec_start;
return delta
在load_balance中,move_tasks返回失败也就是ld_moved==0,其中sd->nr_balance_failed++对应can_migrate_task中的”too many balance attempts have failed”,然后busiest->active_balance = 1设置,active_balance = 1。
if (active_balance) //如果pull失败了,开始触发push操作 stop_one_cpu_nowait(cpu_of(busiest), active_load_balance_cpu_stop, busiest, &busiest->active_balance_work);
push整个触发操作代码机制比较绕,stop_one_cpu_nowait把active_load_balance_cpu_stop添加到cpu_stopper每CPU变量的任务队列里面,如下:
void stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
cpu_stop_queue_work(&per_cpu(cpu_stopper, cpu), work_buf);
}
而cpu_stopper则是cpu_stop_init函数通过cpu_stop_cpu_callback创建的migration内核线程,触发任务队列调度。因为migration内核线程是绑定每个核心上的,进程迁移失败的1和3问题就可以通过push解决。active_load_balance_cpu_stop则调用move_one_task函数迁移指定的进程。
上面描述的则是整个pull和push的过程,需要补充的pull触发除了schedule后触发,还有scheduler_tick通过触发中断,调用run_rebalance_domains再调用rebalance_domains触发,不再细数。
void __init sched_init(void)
{
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
}
通过本文,你应该对 Linux 内核的 CPU 负载均衡机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了 CPU 负载均衡机制的作用和影响,以及如何在 Linux 下正确地使用和配置它。我们建议你在使用多核或多处理器的 Linux 系统时,使用 CPU 负载均衡机制来提高系统的性能和效率。同时,我们也提醒你在使用 CPU 负载均衡机制时要注意一些潜在的问题和挑战,如负载均衡策略、能耗、调度延迟等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受 CPU 负载均衡机制的优势和便利。
以上是Linux 核心的 CPU 負載平衡機制:原理、流程與最佳化的詳細內容。更多資訊請關注PHP中文網其他相關文章!