



背景
大語言模型(LLMs)雖然展現了強大的能力,但也可能產生不可預測和有害的輸出,例如冒犯性回應、虛假資訊和洩漏隱私數據,對用戶和社會造成傷害。 確保這些模型的行為與人類意圖和價值觀相對齊,是一個緊迫的挑戰。
儘管基於人類回饋的強化學習(RLHF)提供了一種解決方案,但它面臨複雜的訓練架構、對參數的高敏感性,以及獎勵模型在不同資料集上的不穩定性等多重挑戰。這些因素導致 RLHF 技術實現困難、奏效困難、復現難。
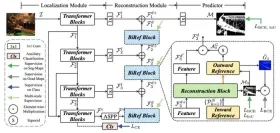
為了克服這些挑戰,北京大學團隊提出了一種新的高效對齊範式——Aligner,其核心在於學習答案對齊與未對齊之間的修正殘差,從而繞過繁瑣的RLHF 流程。
借鑒殘差學習和可擴展監督思想,Aligner簡化了對準過程。它使用Seq2Seq模型學習隱式殘差並透過複製和殘差修正步驟優化對齊效果。
相較於 RLHF 需要訓練多個模型的複雜性,Aligner 的優點在於只需透過在待對齊模型後添加一個模組即可實現對齊。此外,所需計算資源主要取決於對齊效果的期望,而非上游模型的規模。實驗證明,使用 Aligner-7B 能夠顯著提高 GPT-4 的幫助性和安全性,其中幫助性增加了17.5%,安全性增加了26.9%。這些結果表明 Aligner 是一種高效且有效的對齊方法,為模型的效能提升提供了可行的解決方案。
此外,利用Aligner 框架,作者透過弱模型(Aligner-13B)監督訊號增強強模型(Llama-70B)性能,實現了 weak-to-strong 泛化,為超級對齊提供了實踐方案。

- 論文網址:https://arxiv.org/abs/2402.02416
- #專案首頁& 開源位址:https://aligner2024.github.io
- 主題:Aligner : Achieving Efficient Alignment through Weak-to-Strong Correction
什麼是Aligner?

##基於核心洞察:
Correcting unaligned answer is easier than generating aligned answers.
修正未對齊的回答比產生對準的回答容易。
作為一種高效的對齊方法,Aligner 具備以下優秀特性:
- 作為一個自回歸Seq2Seq 模型,Aligner 在問題-答案-修正後的答案(Query-Answer-Correction, Q-A-C)資料集上訓練,學習對齊與未對齊答案之間的差異,從而實現了更精準的模型對齊。例如,在對齊 70B LLM 時,Aligner-7B 大規模降低了訓練參數量,相較於 DPO 小 16.67 倍,比 RLHF 小 30.7 倍。
- Aligner 範式實現了從弱到強的泛化,採用高較小參數量的 Aligner 模型監督訊號微調參數量大的 LLMs ,顯著提升了強模型的性能。例如,利用 Aligner-13B 監督下微調 Llama2-70B,其幫助性和安全性分別提升了 8.2% 和 61.6%。
- 由於 Aligner 即插即用的特性以及它對模型參數並不敏感,它能夠對齊如 GPT3.5、GPT4 和 Claude2,這些無法取得參數的模型。僅有一次訓練,Aligner-7B 對齊並提升了包括閉源、開源及安全 / 未安全對齊模型在內的 11 種模型的幫助性和安全性。其中 Aligner-7B 顯著提升了 GPT-4 的幫助性和安全性,分別提高了 17.5% 和 26.9%。
Aligner 整體表現表現
作者展現了各個尺寸的Aligner(7B,13B,70B )在基於API 的模型、開源模型(包括經過安全對齊和未經過安全對齊)均能提升效能表現。整體來說,隨著模型變大,Aligner 的性能逐步提升,並且修正時所能提供的資訊密度逐漸增大,這也使得修正後的答案更加安全且具有幫助性。

怎麼訓練一個 Aligner 模型?
1.Query-Answer (Q-A) 資料收集
##作者從各種開源資料集中取得Query,包括Stanford Alpaca、ShareGPT、HH-RLHF 以及其他使用者分享對話。這些問題經歷了重複模式去除和品質過濾的過程,用於後續的答案和更正的答案產生。未修正的答案則是使用各種開源模型產生的,如 Alpaca-7B、Vicuna-(7B,13B,33B)、Llama2-(7B,13B)-Chat, and Alpaca2-(7B,13B)。
2. 答案修正
#作者使用GPT-4、Llama2-70B-Chat 和手動標註來根據大語言模型的3H 標準(幫助性、安全性、誠實性)來修正Q-A 資料集中的答案。
對於已符合標準的答案,保持原樣。修改過程基於一系列定義明確的原則,為 Seq2Seq 模型的訓練建立了約束條件,重點在於提升答案的幫助性和安全性。答案的修正前後分佈變化明顯,下圖清楚展示了修改對資料集的影響:

3. 模型訓練
基於上述過程,作者建立了新的修正資料集 #,其中表示使用者的問題,
#,其中表示使用者的問題,
 #是問題的原始答案,
#是問題的原始答案, 是根據既定原則修正的答案。
是根據既定原則修正的答案。
模型訓練過程相對簡單。作者訓練一個由 參數化的條件 Seq2Seq 模型
參數化的條件 Seq2Seq 模型 #,讓原始答案重分佈到對齊的答案。
#,讓原始答案重分佈到對齊的答案。 
基於上游大語言模型的對齊答案生成過程為:

訓練的loss 如下:

其中第2 項與Aligner 參數無關,Aligner 的訓練目標可以推導為:

下圖動態地展示了Aligner 的中間過程:

值得注意的是,Aligner 在訓練和推理階段都不需要存取上游模型的參數。 Aligner 的推理過程只需要取得使用者的問題和上游大語言模型產生的初始答案,然後產生更符合人類價值的答案。
修正现有答案而不是直接回答,这使得 Aligner 能够容易地与人类价值观对齐,从而显著降低了对模型能力的要求。
Aligner 与现有对齐范式对比
Aligner vs SFT
与 Aligner 相反,SFT 直接从 Query 语义空间创建到 Answer 语义空间的跨域映射,这个过程学习依赖于上游模型来推断和模拟语义空间中的各种上下文,这比学习修正信号要难得多。
Aligner 训练范式可以被认为是一种残差学习(残差修正)形式,作者在 Aligner 中创建 「复制(copy) 修正(correct)」学习范式。因此,Aligner 在本质上创建了从回答语义空间到修正的回答的语义空间的残差映射,这两个语义空间在分布上更接近。
为此,作者从 Q-A-C 训练数据集中以不同比例构造了 Q-A-A 数据,训练 Aligner 进行恒等映射学习(也称为 copy mapping)(称为预热步骤)。在此基础上,使用整个 Q-A-C 训练数据集进行训练,这种残差学习范式,也被 ResNet 中采用用来解决堆叠过深的神经网络导致的梯度消失的问题。实验结果表明:当预热比例为 20% 时,模型能够获得最佳表现。
Aligner vs RLHF
RLHF 通过在人类偏好数据集上训练奖励模型(RM),并利用这个奖励模型来进行 PPO 算法微调 LLMs,从而使 LLMs 和人类偏好的行为相一致。
具体而言,奖励模型需要将人类偏好数据从离散映射到连续的数值空间以进行优化,但是相较于在文本空间具有较强泛化能力的 Seq2Seq 模型,这类数值奖励模型在文本空间的泛化能力较弱,从而导致了 RLHF 在不同的模型上效果不稳定。
而 Aligner 通过训练一个 Seq2Seq 模型来学习对齐和未对齐答案之间的差异性(残差),从而有效的避开了 RLHF 过程,并取得了比 RLHF 更具备泛化性的表现。
Aligner vs. Prompt Engineering
提示词工程(Prompt Engineering )是激发 LLMs 能力的常见方法,然而这种方法存在着一些关键问题,如:难以设计 prompt,且需要针对不同模型进行不同设计,最终效果依赖于模型的能力,当模型能力不足以解决任务时,可能需要多次迭代,浪费上下文窗口,小模型的上下文窗口受限会影响到提示词工程的效果,而对于大模型而言,占用过长的上下文极大增加了训练的成本。
Aligner 本身可以支持任意模型的对齐,经过一次训练可以对齐 11 类不同类型的模型,并且能够不占用原模型的上下文窗口。值得注意的是,Aligner 可以与现有的提示词工程方法无缝结合起来,达到 1 1>2 的效果。
总的来说:Aligner 展现出了以下显著优势:
1.Aligner 训练更加简单。相较于 RLHF 复杂的奖励模型学习及基于该模型的强化学习(RL)微调过程,Aligner 的实现过程更为直接且易于操作。反观 RLHF 中涉及的多项工程调参细节以及 RL 算法的固有不稳定性和超参数敏感性,Aligner 大大简化了工程复杂度。
2.Aligner 训练数据少且对齐效果明显。基于 20K 数据训练一个 Aligner-7B 的模型,可以提升 GPT-4 在帮助性方面 12% 以及安全性方面 26%,并提升 Vicuna 33B 模型 29% 的帮助性以及 45.3% 的安全性,而 RLHF 需要更多的偏好数据,并需要精细化的调参才有望达到这个效果。
3.Aligner 不需要接触模型权重。虽然 RLHF 在模型对齐方面被证明有效,但依赖于对模型直接训练。面对未开源的 API-based 模型如 GPT-4 及其在下游任务中的微调需求,RLHF 的适用性受限。相反,Aligner 无需直接操作模型原始参数,通过将对齐需求外置于一个独立的对齐模块中,实现了灵活的对齐方式。
4.Aligner 對模型型別無感。 在 RLHF 框架下,針對不同模型(如 Llama2,Alpaca)的微調不僅需要重新收集偏好數據,還需在獎勵模型訓練及 RL 階段調整訓練參數。而 Aligner 透過一次性訓練,可以支援任意模型的對齊。例如,只需要在修正資料集上訓練一次,Aligner-7B 可以對齊 11 種不同模型(包括開源模型、API 模型如 GPT),並在幫助性和安全性方面分別提升 21.9% 和 23.8% 效能。
5.Aligner 對訓練資源的需求更為靈活。 RLHF 微調一個 70B 的模型仍然對運算資源有著極高的要求,需要數百個 GPU 卡才能進行。因為 RLHF 方法還需要額外載重與模型參數量相當的獎勵模型、Actor 模型及 Critic 模型。因此,就單位時間內的訓練資源消耗而言,RLHF 實際上需要比預訓練更多的運算資源。
相比之下,Aligner 提供了更靈活的訓練策略,讓使用者可以根據自身的實際運算資源狀況,靈活選擇 Aligner 的訓練規模。例如,針對一個 70B 模型的對齊需求,使用者可以根據實際可用的資源選擇不同規模的 Aligner 模型(7B、13B、70B 等),以實現目標模型的有效對齊。
這種彈性不僅降低了對運算資源的絕對需求,也為使用者提供了在有限資源下進行高效對齊的可能性。
Weak-to-strong Generalization

# #Weak-to-strong generalization 討論的問題在於能否使用弱模型的標籤來訓練強模型,使得強模型在效能上有所提升。 OpenAI 使用這一類比旨在解決超對齊(SuperAlignment) 的問題,具體來說,他們使用真值標籤(groud truth)訓練弱模型。
OpenAI 的研究人員進行了一些初步實驗,例如在文字分類(text classfication)的任務上,訓練資料集被分成了兩部分,前半部的輸入和真值標籤被用來訓練弱模型,而後半部的訓練資料僅保留輸入,標籤由弱模型產生。在訓練強模型時僅使用弱模型產生的弱標籤為強模型提供監督訊號。
使用真值標籤訓練弱模型是為了使弱模型獲得解決對應任務的能力,但是用於產生弱標籤的輸入和訓練弱模型的輸入並不相同。這個典範類似 「教學」 的概念,也就是用弱點模式來引導強模型。
作者基於 Aligner 的性質,提出了一種新穎的 weak-to-strong generalization 範式。
作者的核心觀點是讓 Aligner 充當 「站在巨人肩膀上的監督者」。與 OpenAI 直接監督「巨人」的方法不同,Aligner 將透過弱到強的修正,修正更強的模式在這過程中提供更準確的標籤。
具體來說,在 Aligner 的訓練過程中,修正資料包含 GPT-4、人類標註員和更大的模型標註。隨後,作者使用 Aligner 在新的 Q-A 資料集上產生弱標籤(即修正);進而使用弱標籤對原始模型進行微調。
實驗結果顯示此範式可以進一步提升模型的對齊表現。實驗結果
Aligner vs SFT/RLHF/DPO

作者使用Aligner 的Query -Answer-Correction 訓練資料集,分別以SFT/RLHF/DPO 方法對Alpaca-7B 進行微調。
###進行效能評估時,使用開源的BeaverTails 和HarmfulQA 的測試prompt 資料集,將微調後模型產生的答案與原始Alpaca-7B 模型的答案使用Aligner 進行修正後產生的回答,在幫助性和安全性方面進行比較,結果如下:######################實驗結果表明,Aligner 對比諸如SFT/RLHF/DPO這樣成熟的LLM 對齊範式具有明顯的優勢,在幫助性和安全性這兩個指標上均有顯著領先。 ######分析具體的實驗案例,可以發現,使用RLHF/DPO 範式微調的對齊模型,為了提升安全性可能更傾向於產生保守的回答,而在提升幫助性的過程中又無法兼顧安全性,導致回答中的危險訊息增加。
Aligner vs Prompt Engineering
比較Aligner-13B 與CAI / Self-Critique 方法對同一上游模型的效能提升,實驗結果如下圖所示:Aligner-13B 對GPT-4 在幫助性和安全性兩方面的提升,均高於CAI/Self-Critique 方法,這說明Aligner 範式相較於常用prompt engineering 方法具有明顯優勢。
值得注意的是,實驗中僅在推理時使用 CAI prompts,以鼓勵其自我修改答案,這也是 Self-Refine 的形式之一。

除此之外,作者也進行了進一步探究,他們對使用CAI 方法修正後的回答再經過Aligner 進行修正,並將經過Aligner 前後的回答進行直接比較,實驗結果如下圖所示。

Method A:CAI Aligner Method B:CAI only
##使用Aligner 對CAI 修正後的回答進行二次修正後,回答在不損失安全性的同時,在幫助性方面的獲得了極為顯著的提升。這說明 Aligner 不僅在單獨使用時具有強大的競爭力,還能與其他現有對齊方法結合,進一步提升其性能。
Weak-to-strong Generalization

#Method:weak-to -strong 訓練資料集由(q,a,a′)三元組組成,其中q 表示來自Aligner 訓練資料集- 50K 的問題,a 表示Alpaca-7B 模型產生的答案,a′表示Aligner-7B 給定的對齊答案(q,a)。與僅利用 a′作為基本事實標籤的 SFT 不同,在 RLHF 和 DPO 訓練中,a′被認為比 a 更好。
作者在新的Q-A 資料集上用Aligner 對原始答案進行修正,將修正後的回答作為弱標籤,並用這些弱標籤作為監督訊號訓練更大尺寸的模型。這個過程和 OpenAI 的訓練範式是類似的。
作者透過三種方法基於弱標籤對強模型進行訓練:SFT、RLHF 和 DPO。上表的實驗結果顯示,透過 SFT 微調上游模型時,Aligner-7B 和 Aligner-13B 的弱標籤在所有場景中都提高了 Llama2 系列強模型的效能。
展望:Aligner 潛在的研究方向
#Aligner 作為一種創新的對準方法,擁有巨大的研究潛力。在論文中,作者提出了幾個 Aligner 的應用場景,包括:
1. 多輪對話場景的應用。 在多輪對話中,面對稀疏獎勵的挑戰尤其突出。在問答式對話(QA)中,通常只有在對話結束時才能獲得標量形式的監督訊號。
這種稀疏性在多輪對話(例如連續的 QA 場景)中的問題會進一步放大,導致基於強化學習的人類回饋(RLHF)難以發揮效果。研究 Aligner 在改善多輪對話對齊效果方面的潛力,是值得深入探索的領域。
2. 人類價值向獎勵模型的對齊。 在基於人類偏好的獎勵模型建構和大型語言模型(LLMs)微調的多階段過程中,確保LLMs 與特定的人類價值(例如公平性、同理心等)對齊面臨巨大挑戰。
透過將價值對齊任務交由模型外的Aligner 對齊模組處理,並利用特定語料訓練Aligner,不僅為價值對齊提供了新的思路,還使Aligner 能夠修正前置模型的輸出以反映特定的價值觀。
3.MoE-Aligner 的串流和平行處理。 透過將 Aligner 專門化處理並集成,可以創建更強大且全面的混合專家(MoE)Aligner,這種 Aligner 能夠滿足多重混合安全及價值對齊需求。同時,進一步提升 Aligner 的平行處理能力,以減少推理時間的損耗,是可行的發展方向。
4. 模型訓練過程中的融合。 透過在特定的權重層後面整合 Aligner 層,可以實現對模型訓練過程中輸出的即時幹預。這種方法不僅能提高對齊效率,還有助於優化模型訓練流程,實現更有效率的模型對齊。
團隊介紹
此工作由北京大學人工智慧研究院 AI 安全與治理中心楊耀東課題組獨立完成。團隊深耕大語言模型的對齊技術,包括開源百萬級安全對齊偏好資料集 BeaverTails(NeurIPS 2023)、大語言模型的安全對齊演算法 SafeRLHF(ICLR 2024 Spotlight),相關技術已被多個開源模型採納。撰寫業內首個人工智慧對齊的全面性綜述並配套了資源網站www.alignmentsurvey.com(點擊原文可直接跳轉),系統性的闡述了Learning from Feedback、Learning under Distribution Shift,Assurance,Governance 四個視角下的AI 對齊問題。該團隊關於對齊與超對齊的觀點被採編為 2024 年第 5 期《三聯生活周刊》封面。
以上是无需RLHF显著提升GPT-4/Llama2性能,北大团队提出Aligner对齐新范式的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 DeepSeek V3 vs Claude 3.7:V3-0324在編碼方面是否更好?Apr 24, 2025 am 10:55 AM
DeepSeek V3 vs Claude 3.7:V3-0324在編碼方面是否更好?Apr 24, 2025 am 10:55 AM隨著AI模型的發展,他們的編程和軟件開發功能已成為關鍵基準。編碼場景中的兩個主要競爭者是DeepSeek V3和Claude 3.7。 DeepSeek V3-0324,最新的DeepSeek AI,C
 Gemini和Groq的草稿提示鏈Apr 24, 2025 am 10:46 AM
Gemini和Groq的草稿提示鏈Apr 24, 2025 am 10:46 AM推理模型(例如OpenAI的O1和DeepSeek R1)的最新進步已推動LLM通過諸如Thought(COT)等技術的令人印象深刻的性能。但是,cot的詳細性質導致
 RF-DER:橋接速度和對象檢測的準確性Apr 24, 2025 am 10:40 AM
RF-DER:橋接速度和對象檢測的準確性Apr 24, 2025 am 10:40 AM歡迎讀者,簡歷課程重新參加了會議!迄今為止,我們以前已經在我以前的博客中研究了30種不同的計算機視覺模型,每個博客都從快速檢測技巧中帶來了自己的獨特優勢
 Agent SDK vs Crewai vs Langchain:哪個何時使用?Apr 24, 2025 am 10:39 AM
Agent SDK vs Crewai vs Langchain:哪個何時使用?Apr 24, 2025 am 10:39 AM本文比較了建立AI代理的三個流行框架:OpenAI的Agent SDK,Langchain和Crewai。 每個都為自動化任務和增強決策提供了獨特的優勢。 這篇文章指導您選擇最佳幀
 使用Pydantic構建結構化研究自動化系統Apr 24, 2025 am 10:32 AM
使用Pydantic構建結構化研究自動化系統Apr 24, 2025 am 10:32 AM在學術研究的動態領域,有效的信息收集,綜合和演示至關重要。 文獻綜述的手動過程是耗時的,阻礙了更深入的分析。 多代理研究助理系統BUI
 10 GPT-4O圖像生成會提示今天嘗試!Apr 24, 2025 am 10:26 AM
10 GPT-4O圖像生成會提示今天嘗試!Apr 24, 2025 am 10:26 AMAI世界中發生了絕對野生的事情。 Openai的本地形像生成現在很瘋狂。我們正在談論令人jaw目結舌的視覺效果,可怕的細節和拋光的輸出
 用帆板編碼的氛圍指南Apr 24, 2025 am 10:25 AM
用帆板編碼的氛圍指南Apr 24, 2025 am 10:25 AM毫不費力地將您的編碼願景帶入Codeium's Windsurf,這是您的AI驅動的編碼伴侶。 Windsurf簡化了整個軟件開發生命週期,從編碼和調試到優化,將過程轉換為INTU
 使用RMGB v2.0探索圖像背景刪除Apr 24, 2025 am 10:20 AM
使用RMGB v2.0探索圖像背景刪除Apr 24, 2025 am 10:20 AMBraiai的RMGB v2.0:強大的開源背景拆卸模型 圖像分割模型正在徹底改變各個領域,而背景刪除是進步的關鍵領域。 Braiai的RMGB v2.0是最先進的開源M


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SublimeText3漢化版
中文版,非常好用

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript開發工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

