
不分割成token,直接從位元組高效學習,Mamba原來還能這樣用

- 王林轉載
- 2024-02-04 14:54:29735瀏覽
在定義語言模型時,常使用基本的分詞方法,將句子分為單字、子字或字元。子詞分詞法一直以來都是最受歡迎的選擇,因為它在訓練效率和處理詞彙表外單字的能力之間取得了平衡。然而,一些研究指出了子詞分詞法的問題,例如對於錯字、拼字和大小寫變化以及形態變化的處理缺乏穩健性。因此,在語言模型的設計中需要仔細考慮這些問題,以提高模型的準確性和穩健性。
因此,一些研究人員選擇了一種使用位元組序列的方法,即透過原始資料到預測結果的端對端映射,而不進行任何分詞。與子詞模型相比,基於位元組級的語言模型更容易泛化到不同的寫作形式和形態變化。然而,將文字建模為位元組意味著生成的序列比對應的子詞更長。為了提高效率,需要透過改進架構來實現。
自回歸Transformer在語言建模中佔據主導地位,但其效率問題尤其突出。它的計算成本隨著序列長度的增加呈二次方增長,導致其對於長序列的擴展能力較差。為了解決這個問題,研究人員對Transformer的內部表示進行了壓縮,以便處理長序列。其中一種方法是開發了長度感知建模方法,該方法在中間層內合併token組,從而減少了計算成本。最近,Yu等人提出了一種名為MegaByte Transformer的方法。它使用固定大小的位元組片段來模擬壓縮形式作為子詞,從而降低了計算成本。然而,目前這可能還不是最佳的解決方案,還有待進一步的研究和改進。
在一項最新的研究中,康乃爾大學的學者們介紹了一種名為MambaByte的高效且簡單的位元組級語言模型。該模型是透過對最近推出的Mamba架構進行直接改進而得到的。 Mamba架構是建立在狀態空間模型(SSM)方法的基礎上的,而MambaByte則引入了更有效的選擇機制,使其在處理文字等離散資料時表現更加出色,並且還提供了高效的GPU實作。研究人員對使用未經修改的Mamba進行了簡單觀察,發現它能夠緩解語言建模中的主要計算瓶頸,從而消除了修補補丁(patch)的需求,並能夠充分利用可用的計算資源。

- 論文標題:MambaByte: Token-free Selective State Space Model
- #論文連結:https://arxiv.org/pdf/2401.13660.pdf
在實驗中,他們對MambaByte與Transformers、SSM和MegaByte(patching)架構進行了比較。這些架構在固定參數和計算設定下,並在多個長篇文字資料集上進行了評估。圖1總結了他們的主要發現。
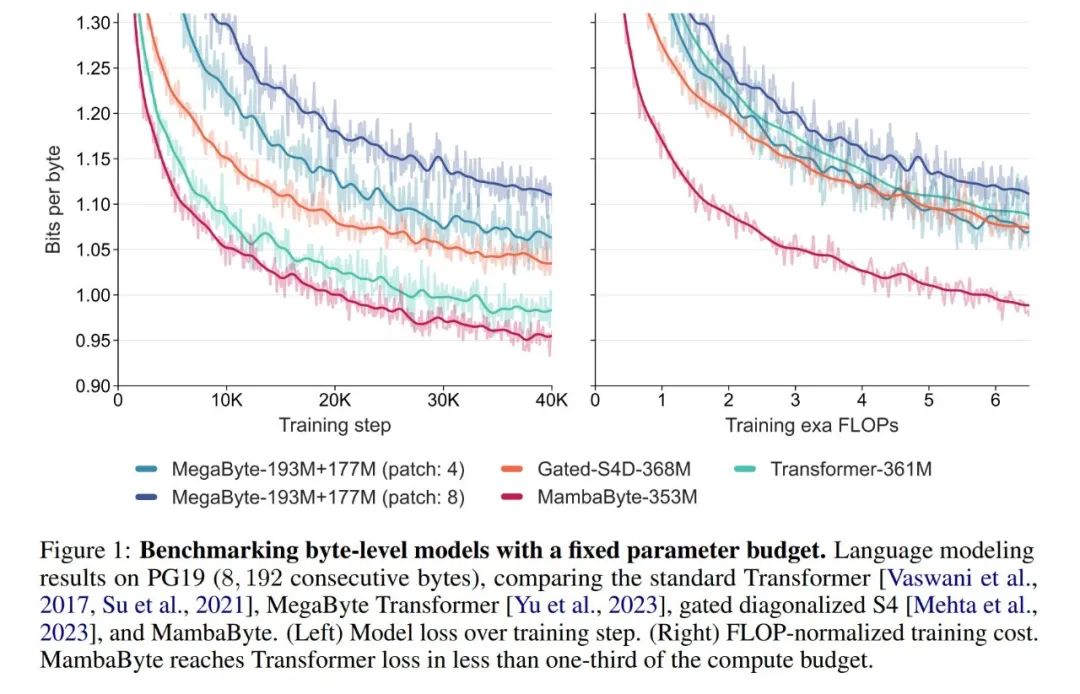
與位元組級Transformers 相比,MambaByte 提供了更快速且高效能的解決方案,同時運算效率也得到了明顯的提升。研究人員也對無 token 語言模型與目前最先進的子詞模型進行了比較,並發現 MambaByte 在這方面具有競爭力,並且能夠處理更長的序列。這項研究結果表明,MambaByte 可以成為現有依賴分詞器的有力替代品,並有望推動端到端學習的進一步發展。
背景:選擇性狀態空間序列模型
#SSM使用一階微分方程式對隱藏狀態的時間演變進行建模。線性時不變的SSM在多種深度學習任務中表現出良好的效果。然而,最近Mamba的作者Gu和Dao認為這些方法的恆定動態缺乏隱藏狀態中依賴輸入的上下文選擇,而這對於語言建模等任務可能是必需的。因此,他們提出了Mamba方法,該方法透過將給定輸入x(t) ∈ R、隱藏狀態h(t) ∈ R^n和輸出y(t) ∈ R在時間t的時變連續狀態動態定義為:
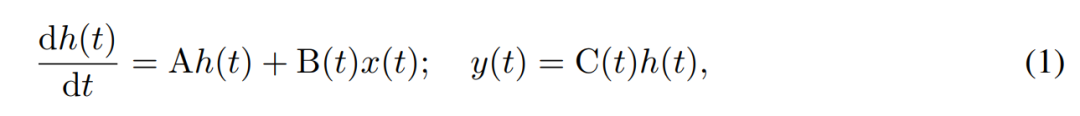
其參數為對角時不變系統矩陣A∈R^(n×n),以及隨時間變化的輸入和輸出矩陣B (t)∈R^(n×1) 和C (t)∈R^(1×n)。
要對位元組等離散時間序列建模,必須透過離散化來逼近 (1) 中的連續時間動態。這就產生了離散時間隱態recurrence,每個時間步都有新矩陣A、B 和C,也就是
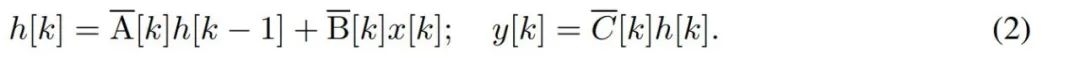
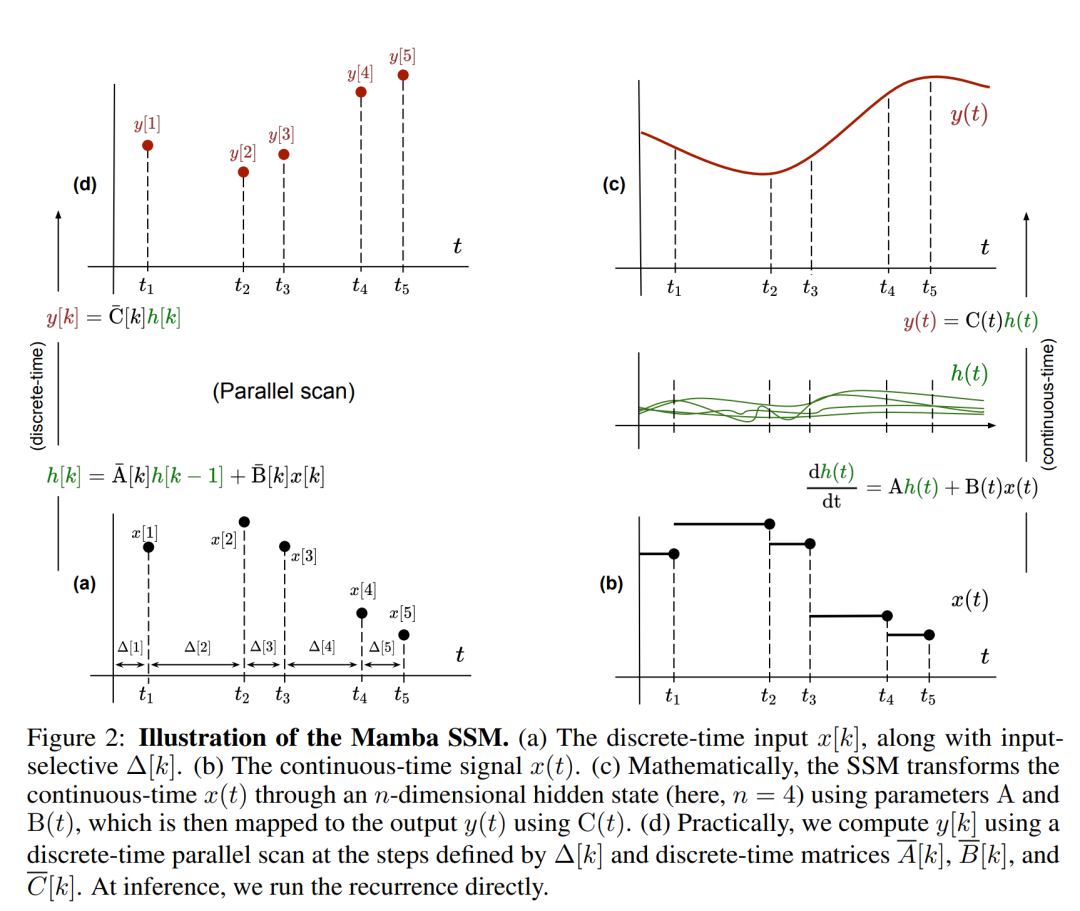
##請注意,( 2) 類似於循環神經網路的線性版本,可以在語言模型生成過程中以此循環形式應用。離散化要求每個輸入位置都有一個時間步,即 ∆[k],對應於 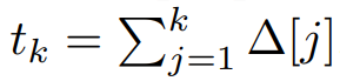 的 x [k] = x (t_k)。然後就可以根據 ∆[k] 計算出離散時間矩陣 A、B 和 C。圖 2 展示了 Mamba 如何為離散序列建模。
的 x [k] = x (t_k)。然後就可以根據 ∆[k] 計算出離散時間矩陣 A、B 和 C。圖 2 展示了 Mamba 如何為離散序列建模。
在Mamba 中,SSM 項是輸入選擇性的,即B、C 和∆ 被定義為輸入x [k]∈R^ d 的函數:
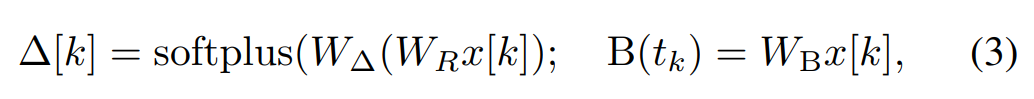
#其中W_B ∈ R^(n×d)(C 的定義類似),W_∆ ∈ R^(d×r) 和W_R ∈ R^(r×d)(對於某個r ≪d)是可學習的權重,而softplus 則確保正向性。請注意,對於每個輸入維度 d,SSM 參數 A、B 和 C 都是相同的,但時間步數 ∆ 是不同的;這導致每個時間步數 k 的隱藏狀態大小為 n × d。
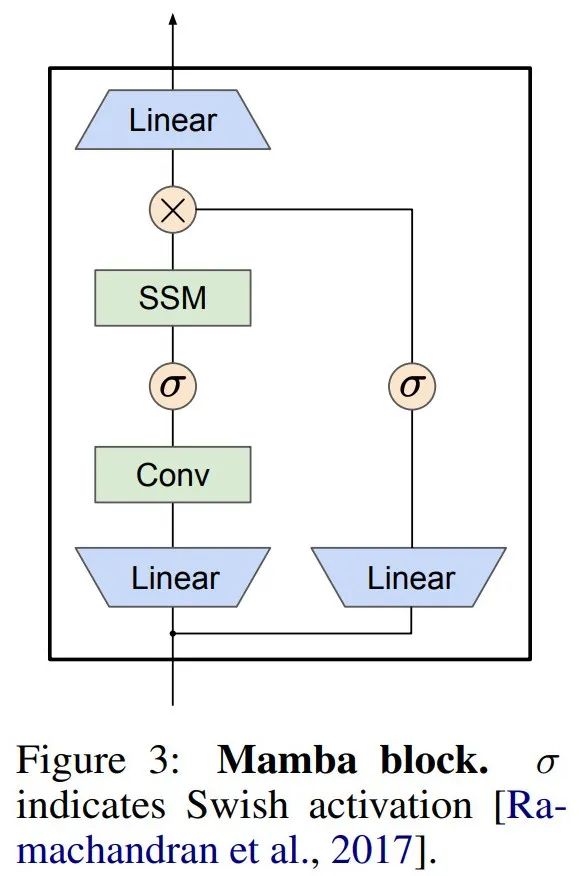
Mamba 將這個 SSM 層嵌入到一個完整的神經網路語言模型中。具體來說,該模型採用了一系列門控層,其靈感來自先前的門控 SSM。圖 3 顯示了將 SSM 層與門控神經網路結合的 Mamba 架構。
線性 recurrence 的平行掃描。在訓練時,作者可以存取整個序列 x,從而更有效率地計算線性 recurrence。 Smith et al. [2023] 的研究證明,使用工作效率高的平行掃描可以有效率地計算線性 SSM 中的順序 recurrence。對於Mamba,作者首先將recurrence 對應到L 個元組序列,其中e_k = #,然後定義一個關聯算符
#,然後定義一個關聯算符  使得
使得 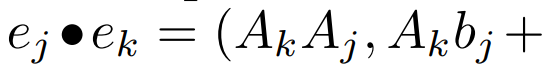
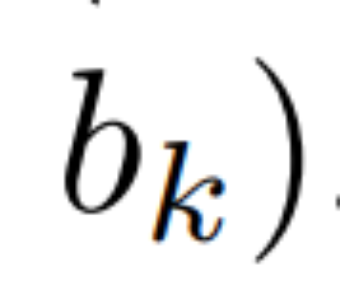 。最後,他們應用平行掃描計算序列
。最後,他們應用平行掃描計算序列 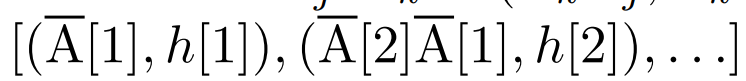 。一般來說,這需要
。一般來說,這需要 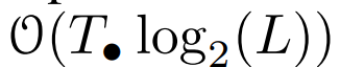 時間,使用 L/2 個處理器,其中
時間,使用 L/2 個處理器,其中 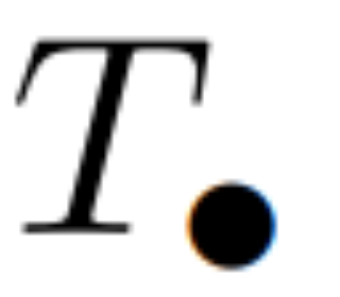 是矩陣乘法的成本。請注意,A 是一個對角矩陣,線性 recurrence 可在
是矩陣乘法的成本。請注意,A 是一個對角矩陣,線性 recurrence 可在 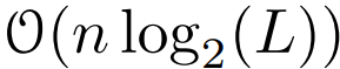 時間和 O (nL) 空間內並行計算。使用對角矩陣進行平行掃描的運作效率也很高,只需 O (nL) FLOPs。
時間和 O (nL) 空間內並行計算。使用對角矩陣進行平行掃描的運作效率也很高,只需 O (nL) FLOPs。
實驗結果
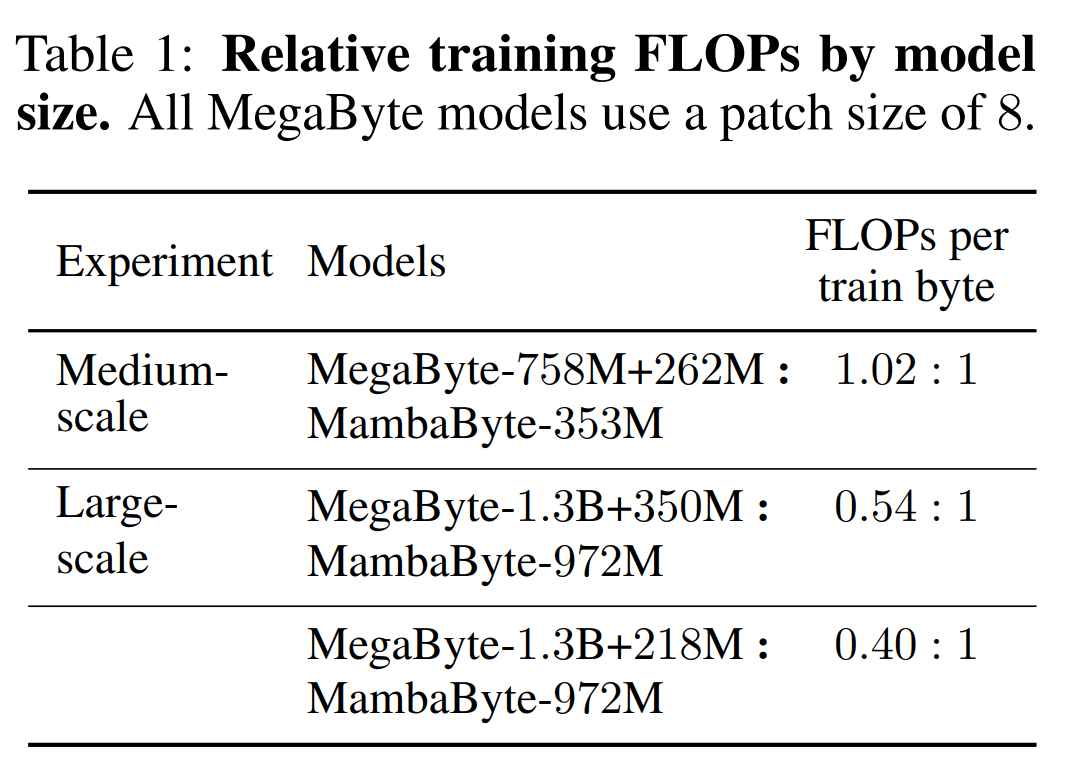
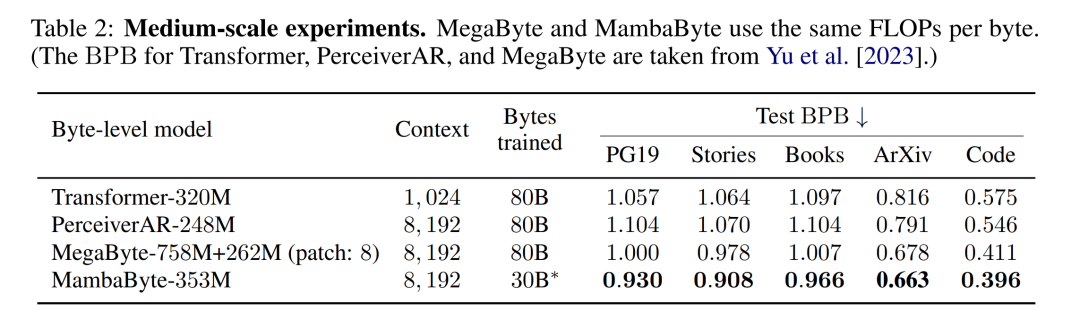
表 2 顯示了每個資料集的每位元組位元數(BPB)。在本實驗中,MegaByte758M 262M 和 MambaByte 模型使用相同的每位元組 FLOP 數(見表 1)。作者發現,在所有資料集上,MambaByte 的效能始終優於 MegaByte。此外,作者註意到,由於資金限制,他們無法對 MambaByte 進行完整的 80B 位元組訓練,但 MambaByte 在計算量和訓練資料減少 63% 的情況下仍優於 MegaByte。此外,MambaByte-353M 也優於位元組級 Transformer 和 PerceiverAR。
#在如此少的訓練步驟中,MambaByte 為什麼比一個大得多的模型表現得更好?圖 1 透過觀察參數數量相同的模型進一步探討了這種關係。圖中顯示,對於參數大小相同的 MegaByte 模型,輸入 patching 較少的模型表現較好,但在計算歸一化後,它們的表現類似。事實上,全長的 Transformer 雖然在絕對意義上速度較慢,但在計算歸一化後,其效能也與 MegaByte 相似。相較之下,改用 Mamba 架構可以顯著提高運算使用率和模型效能。
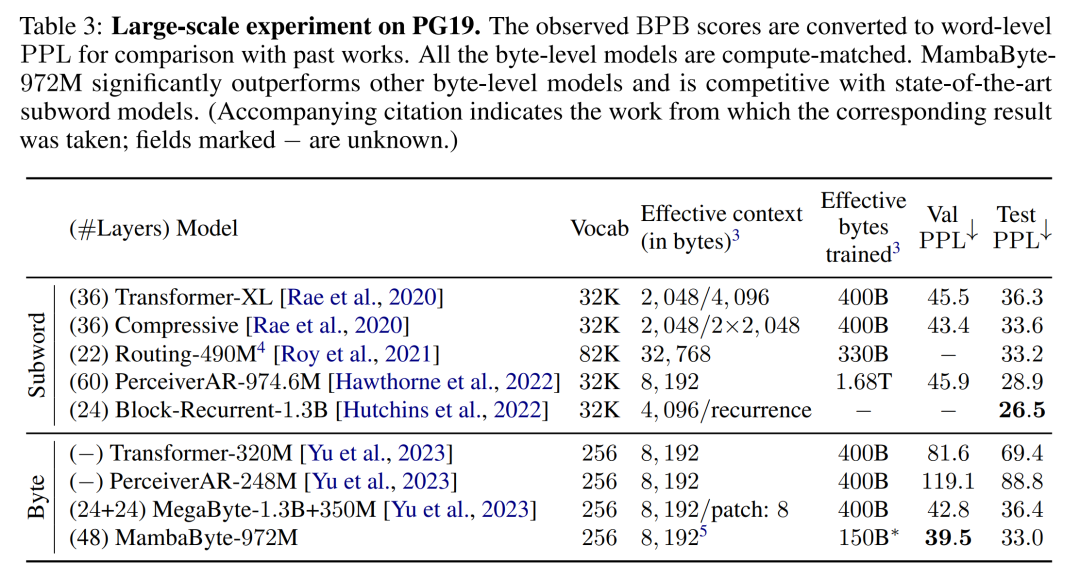
根據這些發現,表 3 比較了這些模型在 PG19 資料集上的較大版本。在這個實驗中,作者將 MambaByte-972M 與 MegaByte-1.3B 350M 和其他位元組級模型以及幾個 SOTA 子詞模型進行了比較。他們發現,MambaByte-972M 即使只訓練了 150B 字節,其性能也優於所有字節級模型,並與子詞模型相比具有競爭力。
文字生成。 Transformer 模型中的自回歸推理需要快取整個上下文,這會大大影響生成速度。 MambaByte 不存在這一瓶頸,因為它每層只保留一個隨時間變化的隱藏狀態,因此每生成一步的時間是恆定的。表 4 比較了 MambaByte-972M 和 MambaByte-1.6B 與 MegaByte-1.3B 350M 在 A100 80GB PCIe GPU 上的文字產生速度。雖然 MegaByte 透過 patching 大大降低了生成成本,但他們觀察到 MambaByte 由於使用了循環生成,在參數相似設定下速度達到了前者的 2.6 倍。

以上是不分割成token,直接從位元組高效學習,Mamba原來還能這樣用的詳細內容。更多資訊請關注PHP中文網其他相關文章!