
登Nature子刊,滑鐵盧大學團隊評論「量子電腦+大語言模型」當下與未來

- PHPz轉載
- 2024-02-04 14:03:031345瀏覽
模擬當今量子運算設備的關鍵挑戰之一是學習和編碼量子位元之間複雜關聯的能力。新興技術基於機器學習語言模型已展現出學習量子態的獨特能力。
近期,滑鐵盧大學的研究人員在《Nature Computational Science》發表了一篇名為《Language models for quantum simulation》的透視文章,強調了語言模型在構建量子計算機方面的重要貢獻,並探討了它們在未來量子優勢競爭中的潛在作用。這篇文章突顯了語言模型在量子計算領域的獨特價值,指出它們可以用來解決量子系統的複雜性和精確性問題。研究人員認為,透過使用語言模型,可以更好地理解和優化量子演算法的性能,並為量子電腦的開發提供新的思路。文章也強調了語言模型在量子優勢競爭中的潛在作用,認為它們可以幫助加速量子電腦的發展,並有望在解決實際問題方面取得

論文連結:https://www.nature.com/articles/s43588-023-00578-0
量子電腦已經開始成熟,最近許多設備都聲稱具有量子優勢。經典運算能力的持續發展,例如機器學習技術的快速崛起,引發了許多圍繞量子和經典策略之間相互作用的令人興奮的場景。隨著機器學習繼續與量子計算堆疊快速集成,提出了一個問題:它是否可以在未來以強大的方式改變量子技術?
目前量子電腦面臨的主要挑戰之一是學習量子態。最近出現的生成模型提供了兩種常用策略來解決學習量子態的問題。

圖示:自然語言及其他領域的生成模型。 (資料來源:論文)
首先,透過使用代表量子電腦輸出的資料集進行資料驅動學習,可以採用傳統的最大似然方法。其次,我們可以利用物理學方法來處理量子態,這種方法利用了量子位元之間相互作用的知識,定義了替代損失函數。
無論哪種情況,量子位元數量 N 的增加都會導致量子態空間(希爾伯特空間)的大小以指數方式增長,這被稱為維數災難。因此,在擴展模型中表示量子態所需的參數數量以及尋找最佳參數值的計算效率都面臨著巨大的挑戰。為了克服這個問題,人工神經網路生成模型是一種非常合適的解決方案。
語言模型是一種特別有前景的生成模型,它已成為解決高複雜性語言問題的強大架構。由於其可擴展性,也適用於量子計算中的問題。如今,隨著工業語言模型進入數萬億個參數的範圍,人們很自然地想知道類似的大型模型在物理學中可以實現什麼,無論是在擴展量子計算等應用中,還是在量子物質、材料和設備的基礎理論理解中。
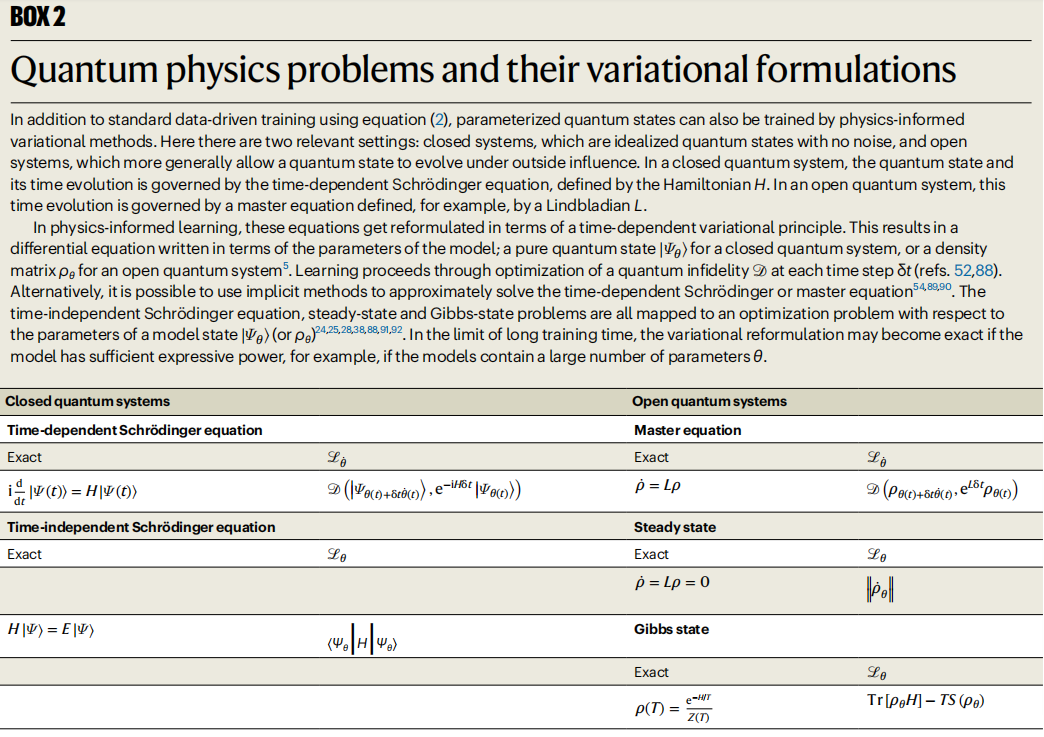
圖示:量子物理問題及其變分公式。 (資料來源:論文)
量子計算的自迴歸模型
語言模型是旨在從自然語言資料推斷機率分佈的生成模型。
產生模型的任務是學習語料庫中出現的單字之間的機率關係,允許每次產生一個標記的新短語。主要困難在於對單字之間所有複雜的依賴關係進行建模。
類似的挑戰也適用於量子計算機,其中糾纏等非局部相關性會導致量子位元之間高度不平凡的依賴性。因此,一個有趣的問題是,工業界開發的強大自回歸架構是否也可以應用於解決強相關量子系統中的問題。
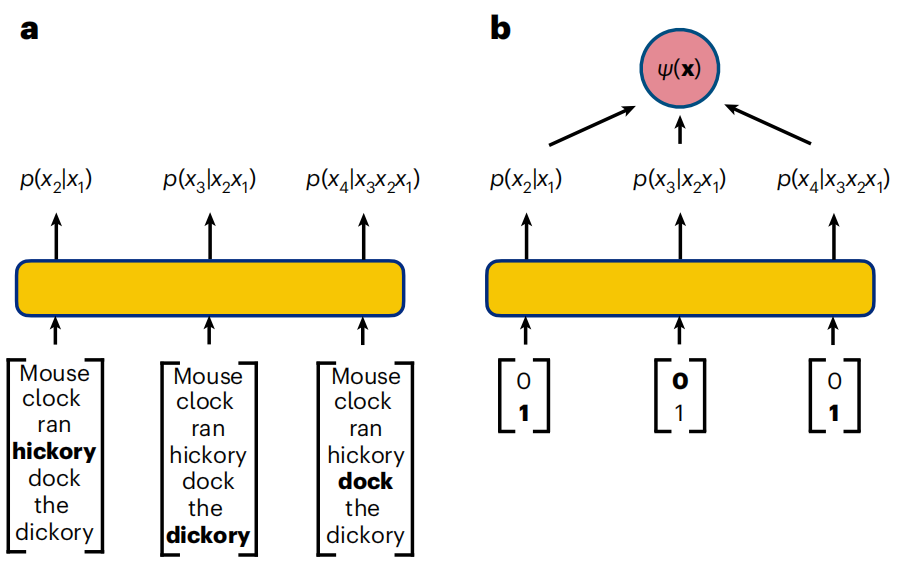
圖示:文字與量子位元序列的自迴歸策略。 (來源:論文)
RNN 波函數
RNN 是任何包含循環連接的神經網絡,因此 RNN 單元的輸出取決於先前的輸出。自 2018 年以來,RNN 的使用迅速擴大,涵蓋了理解量子系統中各種最具挑戰性的任務。
RNN 適合這些任務的關鍵優勢是它們能夠學習和編碼量子位元之間高度重要的相關性,包括本質上非局域的量子糾纏。
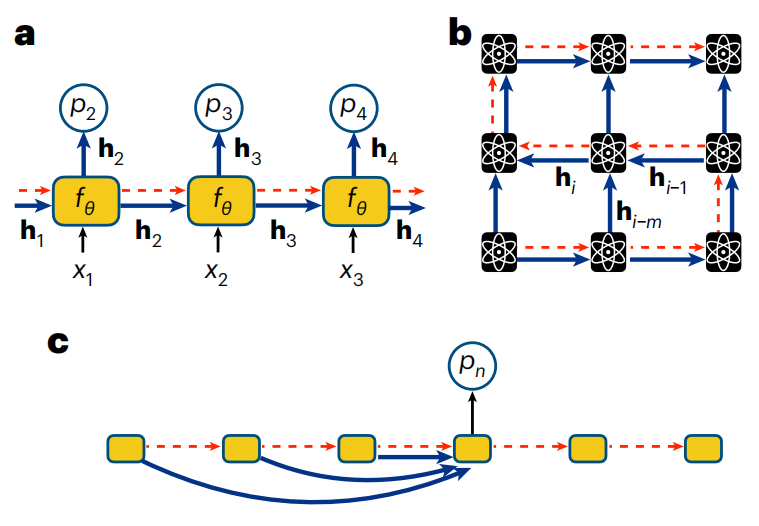
圖示:用於量子位元序列的 RNN。 (資料來源:論文)
物理學家已將 RNN 用於與量子運算相關的各種創新用途。 RNN 已用於根據量子位元測量重建量子態的任務。 RNN 也可以用於模擬量子系統的動態特性,這被認為是量子計算最有前途的應用之一,因此也是定義量子優勢的關鍵任務。 RNN 已被用作構建神經糾錯解碼器的策略,這是容錯量子電腦開發的關鍵要素。此外,RNN 能夠利用數據驅動和物理啟發的最佳化,從而在量子模擬中實現越來越多的創新用途。
物理學家社群繼續積極開發 RNN,希望利用它們來完成量子優勢時代遇到的日益複雜的運算任務。 RNN 在許多量子任務中與張量網路的運算競爭力,加上它們利用量子位元測量資料的價值的天然能力,表明 RNN 將繼續在未來模擬量子電腦的複雜任務中發揮重要作用。
Transformer 量子態
多年來,雖然RNN 在自然語言任務中取得了巨大成功,但最近它們在工業中因Transformer的自註意力機製而黯然失色,而Transformer 是當今大型語言模型(LLM) 編碼器-解碼器架構的關鍵組成部分。
縮放(scaling ) Transformer 的成功,以及它們在語言任務中所展示的非平凡湧現現象所引發的重要問題,一直吸引著物理學家,對他們來說,實現縮放是量子計算研究的主要目標。
從本質上講,Transformer 就是簡單的自迴歸模型。然而,與 RNN 不同的是,RNN 是透過隱藏向量進行相關性的隱式編碼,Transformer 模型輸出的條件分佈明確依賴於序列中有關自回歸特性的所有其他變數。這是透過因果屏蔽的自註意力機制來完成的。
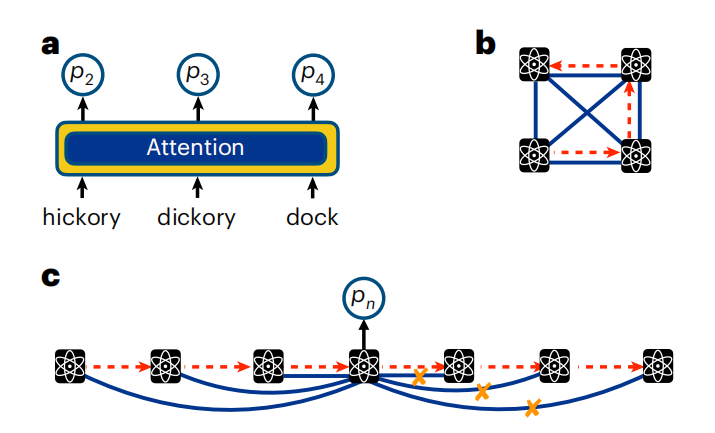
圖示:注意文字與量子位元序列。 (資料來源:論文)
與語言資料一樣,在量子系統中,注意力是透過獲取量子位元測量值並透過一系列參數化函數進行轉換來計算的。透過訓練一堆這樣的參數化函數,Transformer 可以學習量子位元之間的依賴關係。有了注意力機制,就不需要將傳遞隱藏狀態的幾何結構(就像在 RNN 中一樣)與量子位元的物理排列相關聯。
透過利用這種架構,可以訓練具有數十億或數兆參數的 Transformer。
對於當前一代量子電腦來說,結合資料驅動和物理啟發學習的混合兩步驟最佳化非常重要,已經證明了Transformer 能夠減輕當今不完美的輸出資料中出現的錯誤,並可能形成強大的糾錯協議的基礎,以支持未來真正容錯硬體的開發。
隨著涉及量子物理 Transformer 的研究範圍不斷迅速擴大,一系列有趣的問題仍然存在。
量子計算語言模型的未來
儘管物理學家對它們的探索時間很短,但語言模型在應用於量子運算領域的廣泛挑戰時已經取得了顯著的成功。這些成果預示著未來許多有前景的研究方向。
量子物理學中語言模型的另一個關鍵用例來自於它們的最佳化能力,不是透過數據,而是透過哈密頓量或Lindbladian 的基本量子位元相互作用的知識。
Finally, the language model opens up a new field of hybrid training through the combination of data-driven and variation-driven optimization. These emerging strategies offer new ways to reduce errors and show powerful improvements in variational simulations. Since generative models have recently been adapted into quantum error-correcting decoders, hybrid training may be an important step toward the future holy grail of fault-tolerant quantum computers. This suggests that a virtuous cycle is about to emerge between quantum computers and language models trained on their output.
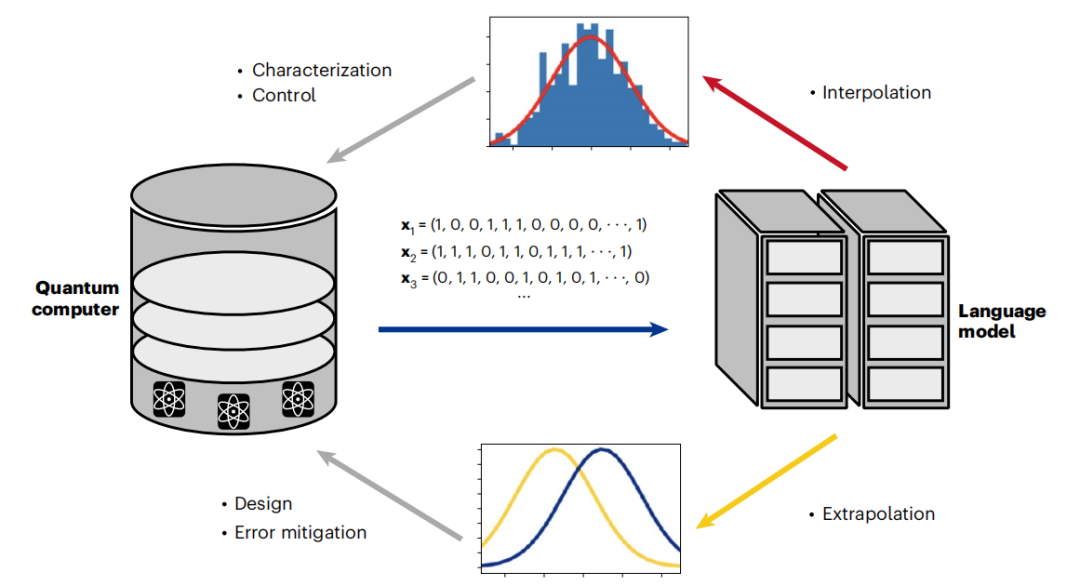
Illustration: The language model realizes the expansion of quantum computing through a virtuous cycle. (Source: Paper)
Looking ahead, the most exciting opportunities to connect the field of language models to quantum computing lie in their ability to demonstrate scale and emergence.
Today, with the demonstration of emergent properties of LLM, a new frontier has been broken, raising many compelling questions. Given enough training data, can LLM learn a digital copy of a quantum computer? How will the inclusion of language models in the control stack affect the characterization and design of quantum computers? If the scale is large enough, can LLM show the emergence of macroscopic quantum phenomena such as superconductivity?
While theorists ponder these questions, experimental and computational physicists have begun to apply language models in earnest to the design, characterization, and control of today's quantum computers. As we cross the threshold of quantum advantage, we also enter new territory in extending language models. While it is difficult to predict how the collision of quantum computers and LLM will unfold, what is clear is that fundamental shifts brought about by the interplay of these technologies have already begun.
以上是登Nature子刊,滑鐵盧大學團隊評論「量子電腦+大語言模型」當下與未來的詳細內容。更多資訊請關注PHP中文網其他相關文章!