


現在的瀏覽器裡,有一個十分有趣的功能,你可以在不刷新頁面的情況下修改瀏覽器URL;在瀏覽過程中.你可以將瀏覽歷史儲存起來,當你在瀏覽器點擊後退按鈕的時候,你可以沖瀏覽歷史上獲得回退的信息,這聽起來並不復雜,是可以實現的,我們來編寫一些程式碼。來看看它是如何運作的。
var stateObject = {};
var title = "Wow Title";
var newUrl = "/my/awesome/url";
history.pushState(stateObject,title,newUrl);
History 物件 pushState() 這個方法有3個參數,你可以從上面的例子看到。第一個參數,是一個Json物件, 在你儲存有關當前URl的任意歷史資訊.第二個參數,title 就相當於傳遞一個文檔的標題,第三個參數是用來傳遞新的URL. 你將看到瀏覽器的網址列發生變化而目前頁面並沒刷新。
讓我們來看一個例子,在這個例子中我們將在每個獨立的URL中儲存一些任意資料。
for(i=0;i<5;i++){
var stateObject = {id: i};
var title = "Wow Title "+i;
var newUrl = "/my/awesome/url/"+i;
history.pushState(stateObject,title,newUrl);
}
現在運行,點擊瀏覽器的返回按鈕,查看URL是怎麼改變的。對於每次URL的改變,是因為它儲存了歷史狀態「id」以及對應的值。但是我們要怎麼重新獲得歷史狀態,並且在此基礎上做些事情呢?我們需要對「popstate」新增事件監聽器,這將會在每次歷史物件的狀態改變的時候觸發。
for(i=0;i<5;i++){
var stateObject = {id: i};
var title = "Wow Title "+i;
var newUrl = "/my/awesome/url/"+i;
history.pushState(stateObject,title,newUrl);
alert(i);
}
window.addEventListener('popstate', function(event) {
readState(event.state);
});
function readState(data){
alert(data.id);
}
現在你會看到無論什麼時候你點擊返回按鈕,一個「popstate」事件就會被觸發。我們的事件偵聽器然後檢索歷史狀態物件與之關聯的URL,並提示「id」的值。
它是非常的簡單有趣,不是嗎?

 PHP函数介绍—get_headers(): 获取URL的响应头信息Jul 25, 2023 am 09:05 AM
PHP函数介绍—get_headers(): 获取URL的响应头信息Jul 25, 2023 am 09:05 AMPHP函数介绍—get_headers():获取URL的响应头信息概述:在PHP开发中,我们经常需要获取网页或远程资源的响应头信息。PHP函数get_headers()能够方便地获取目标URL的响应头信息,并以数组形式返回。本文将介绍get_headers()函数的用法,以及提供一些相关的代码示例。get_headers()函数的用法:get_header
 为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM
为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM报错的原因NameResolutionError(self.host,self,e)frome是由urllib3库中的异常类型,这个错误的原因是DNS解析失败,也就是说,试图解析的主机名或IP地址无法找到。这可能是由于输入的URL地址不正确,或者DNS服务器暂时不可用导致的。如何解决解决此错误的方法可能有以下几种:检查输入的URL地址是否正确,确保它是可访问的确保DNS服务器可用,您可以尝试在命令行中使用"ping"命令来测试DNS服务器是否可用尝试使用IP地址而不是主机名来访问网站如果是在代理
 怎样透过几个步骤获取您的 Steam ID?May 08, 2023 pm 11:43 PM
怎样透过几个步骤获取您的 Steam ID?May 08, 2023 pm 11:43 PM现在很多热爱游戏的windows用户都进入了Steam客户端,可以搜索、下载和玩任何好游戏。但是,许多用户的个人资料可能具有完全相同的名称,这使得查找个人资料或什至将Steam个人资料链接到其他第三方帐户或加入Steam论坛以共享内容变得困难。为配置文件分配了一个唯一的17位id,它保持不变,用户无法随时更改,而用户名或自定义URL可以更改。无论如何,一些用户并不知道他们的Steamid,这对于了解这一点非常重要。如果您也不知道如何找到您帐户的Steamid,请不要惊慌。在这篇文
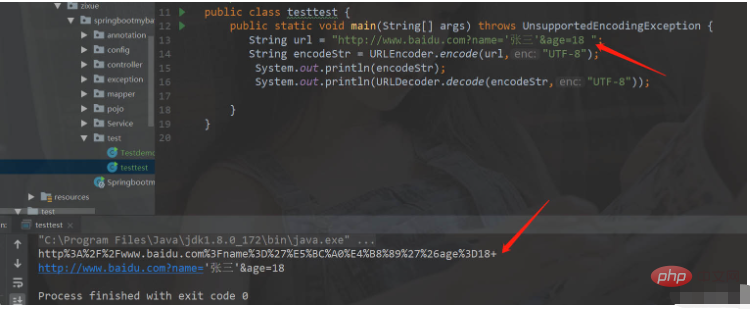 如何在Java中使用URL编码和解码May 08, 2023 pm 05:46 PM
如何在Java中使用URL编码和解码May 08, 2023 pm 05:46 PM使用url进行编码和解码编码和解码的类java.net.URLDecoder.decode(url,解码格式)解码器.解码方法。转化成普通字符串,URLEncoder.decode(url,编码格式)将普通字符串变成指定格式的字符串packagecom.zixue.springbootmybatis.test;importjava.io.UnsupportedEncodingException;importjava.net.URLDecoder;importjava.net.URLEncoder
 html和url的区别是什么Mar 06, 2024 pm 03:06 PM
html和url的区别是什么Mar 06, 2024 pm 03:06 PM区别:1、定义不同,url是是统一资源定位符,而html是超文本标记语言;2、一个html中可以有很多个url,而一个url中只能存在一个html页面;3、html指的是网页,而url指的是网站地址。
 Scrapy优化技巧:如何减少重复URL的爬取,提高效率Jun 22, 2023 pm 01:57 PM
Scrapy优化技巧:如何减少重复URL的爬取,提高效率Jun 22, 2023 pm 01:57 PMScrapy是一个功能强大的Python爬虫框架,可以用于从互联网上获取大量的数据。但是,在进行Scrapy开发时,经常会遇到重复URL的爬取问题,这会浪费大量的时间和资源,影响效率。本文将介绍一些Scrapy优化技巧,以减少重复URL的爬取,提高Scrapy爬虫的效率。一、使用start_urls和allowed_domains属性在Scrapy爬虫中,可
 SpringBoot多controller如何添加URL前缀May 12, 2023 pm 06:37 PM
SpringBoot多controller如何添加URL前缀May 12, 2023 pm 06:37 PM前言在某些情况下,服务的controller中前缀是一致的,例如所有URL的前缀都为/context-path/api/v1,需要为某些URL添加统一的前缀。能想到的处理办法为修改服务的context-path,在context-path中添加api/v1,这样修改全局的前缀能够解决上面的问题,但存在弊端,如果URL存在多个前缀,例如有些URL需要前缀为api/v2,就无法区分了,如果服务中的一些静态资源不想添加api/v1,也无法区分。下面通过自定义注解的方式实现某些URL前缀的统一添加。一、
 url是啥意思Aug 04, 2023 am 11:43 AM
url是啥意思Aug 04, 2023 am 11:43 AMurl是“Uniform Resource Locator”的缩写,中文意为“统一资源定位符”。URL是通过互联网来定位和访问特定资源的地址,常见于网页浏览和HTTP请求中。URL的主要作用是定位和访问互联网上的资源,这些资源可以是网页、图片、视频、文档或其他文件。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

