
無注意力大模型Eagle7B:基於RWKV,推理成本降低10-100 倍

- WBOY轉載
- 2024-02-01 14:39:461197瀏覽
無注意力大模型Eagle7B:基於RWKV,推理成本降低10-100 倍
在AI賽道中,小模型近來備受矚目,相較於擁有上千億參數的模型。例如,法國AI新創公司發布的Mistral-7B模型在每個基準測試中都表現優於Llama 2 13B,並且在程式碼、數學和推理方面都超過了Llama 1 34B。
與大模型相比,小模型具有許多優點,例如對算力的要求低、可在端側運行等。
近日,又有一個新的語言模型出現了,即7.52B 參數Eagle 7B,來自開源非營利組織RWKV,其具有以下特點:

- 基於RWKV-v5 架構構建,該架構的推理成本較低(RWKV 是線性transformer,推理成本降低10-100 倍以上);
- 在100 多種語言、1.1 兆token 上訓練而成;
- ##在多語言基準測驗中優於所有的7B 類別模型;
- 在英文評測中,Eagle 7B 表現接近Falcon (1.5T)、LLaMA2 (2T)、Mistral;
- #英文評測中與MPT-7B (1T) 相當;
- #沒有註意力的Transformer。

Eagle 7B是基於RWKV-v5架構建構而成的。 RWKV(Receptance Weighted Key Value)是結合了RNN和Transformer的優點,並避免了它們的缺點的新穎架構。它的設計非常精良,能夠緩解Transformer在記憶體和擴充功能方面的瓶頸問題,實現更有效的線性擴充。同時,RWKV也保留了讓Transformer在該領域主導的一些性質。
目前RWKV已經迭代到第六代RWKV-6,效能與大小與Transformer相似。未來研究者可利用此架構創造更有效率的模型。
關於 RWKV 更多信息,大家可以參考「Transformer 時代重塑 RNN,RWKV 將非 Transformer 架構擴展到數百億參數」。
值得一提的是,RWKV-v5 Eagle 7B 可以不受限制地供個人或商業使用。
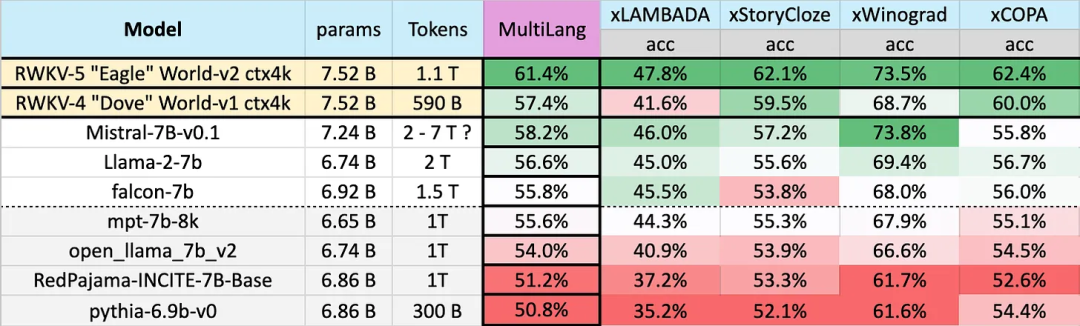
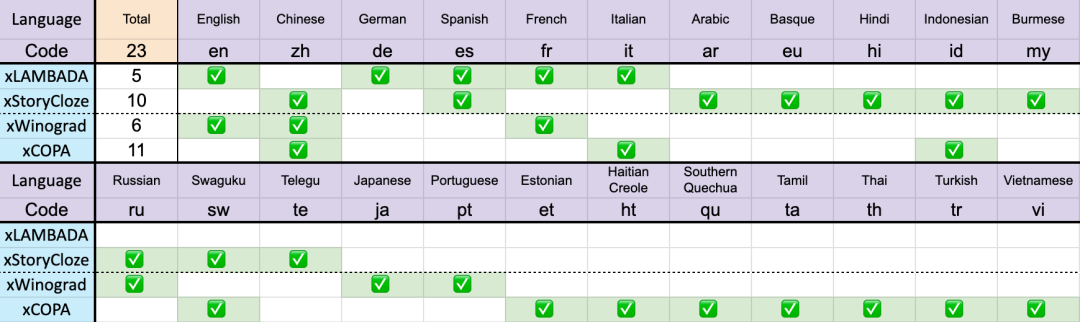
在23 種語言上的測試結果
不同模型在多語言上的表現如下所示,測試基準包括xLAMBDA、xStoryCloze、xWinograd、xCopa。
#共23 種語言
這些基準測試包含了大部分常識推理,顯示出RWKV 架構從v4 到v5 在多語言效能上的巨大飛躍。不過由於缺乏多語言基準,研究只能測試其在 23 種較常用語言上的能力,其餘 75 種以上語言的能力目前仍無法得知。
在英文上的表現
#不同模型在英文上的表現透過12 個基準來判別,包括常識性推理和世界知識。

從結果可以再看出 RWKV 從 v4 到 v5 架構的巨大飛躍。 v4 之前輸給了1T token 的MPT-7b,但v5 卻在基準測試中開始追上來,在某些情況下(甚至在某些基準測試LAMBADA、StoryCloze16、WinoGrande、HeadQA_en、Sciq 上)它可以超過FalconCloze16、WinoGrande、HeadQA_en、Sciq 上)它可以超過FalconCloze ,甚至llama2。
此外,根據給定的近似 token 訓練統計,v5 表現開始與預期的 Transformer 表現水準一致。
此前,Mistral-7B 利用 2-7 兆 Token 的訓練方法在 7B 規模的模型上保持領先。該研究希望縮小這一差距,使得 RWKV-v5 Eagle 7B 超越 llama2 性能並達到 Mistral 的水平。
下圖表明,RWKV-v5 Eagle 7B 在3000 億token 點附近的checkpoints 顯示出與pythia-6.9b 類似的性能:
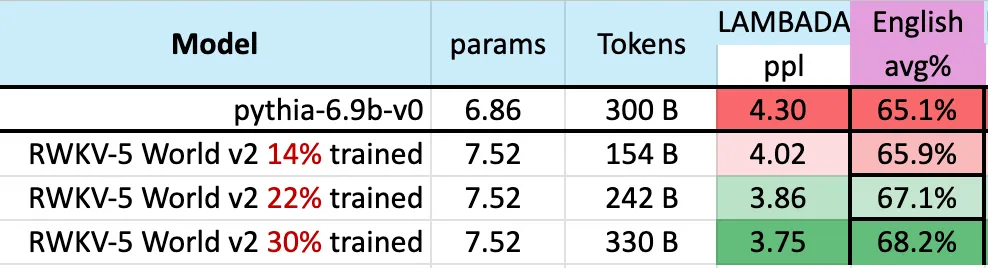
這與先前在RWKV-v4 架構上進行的實驗(pile-based)一致,像RWKV 這樣的線性transformers 在性能水平上與transformers 相似,並且具有相同的token 數訓練。
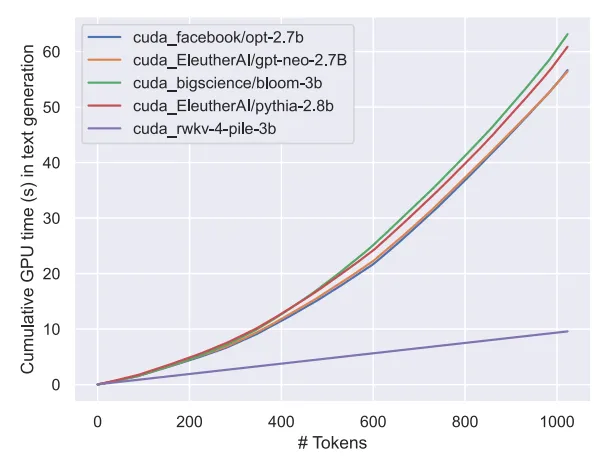
可以預見,模型的出現標誌著迄今為止最強的線性 transformer(就評估基準而言)已經來了。
以上是無注意力大模型Eagle7B:基於RWKV,推理成本降低10-100 倍的詳細內容。更多資訊請關注PHP中文網其他相關文章!