
大模型也能切片,微軟SliceGPT讓LLAMA-2運算效率大增

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-01-31 11:39:231647瀏覽
大型語言模型(LLM)通常擁有數十億參數,經過數萬億token的資料訓練。然而,這樣的模型訓練和部署成本都非常昂貴。為了降低運算需求,人們常常採用各種模型壓縮技術。
這些模型壓縮技術一般可以分為四類:蒸餾、張量分解(包括低秩因式分解)、剪枝和量化。剪枝方法已經存在一段時間,但許多方法需要在剪枝後進行恢復微調(RFT)以保持性能,這使得整個過程成本高昂且難以擴展。
蘇黎世聯邦理工學院和微軟的研究者提出了一個解決此問題的方法,名為SliceGPT。此方法的核心思想是透過刪除權重矩陣中的行和列來降低網路的嵌入維數,以保持模型的效能。 SliceGPT的出現為解決這個問題提供了一個有效的解決方案。
研究人員指出,借助SliceGPT,他們能夠在幾個小時內使用單一GPU對大型模型進行壓縮,即使沒有RFT,也能在生成和下游任務中保持有競爭力的性能。目前,該研究已被ICLR 2024接受。

- # 論文標題:SLICEGPT: COMPRESS LARGE LANGUAGE MODELS BY DELETING ROWS AND COLUMNS
- 論文連結:https://arxiv.org/pdf/2401.15024.pdf
剪枝方法的工作原理是透過將LLM中的權重矩陣的某些元素設為零,並選擇性地更新周圍元素以進行補償。這樣可以形成一種稀疏模式,在神經網路的前向傳遞中跳過一些浮點運算,從而提高計算效率。
稀疏程度和稀疏模式是決定運算速度相對提升的因素。當稀疏模式更合理時,會帶來更多的運算優勢。與其他剪枝方法不同,SliceGPT使用切除(切掉!)權重矩陣的整行或整列的方式進行剪枝。在進行切除之前,網路會進行一次轉換,以保持預測結果不變,但允許輕微影響的剪切過程。
結果是權重矩陣減小,訊號傳遞減弱,神經網路維度降低。
下圖 1 將 SliceGPT 方法與現有的稀疏性方法進行了比較。
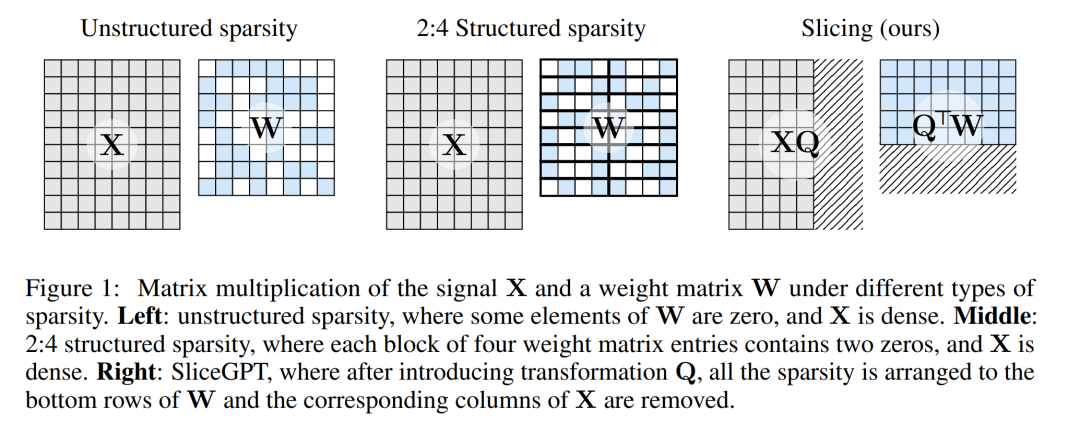
透過大量實驗,作者發現SliceGPT 可以為LLAMA-2 70B、OPT 66B 和Phi-2 模型移除多達25% 的模型參數(包括嵌入),同時分別維持密集模型99%、99% 和90% 的零樣本任務表現。
經過SliceGPT 處理的模型可以在更少的GPU 上運行,而且無需任何額外的程式碼最佳化即可更快地運行:在24GB 的消費級GPU 上,作者將LLAMA-2 70B 的推理總計算量減少到了密集模型的64%;在40GB 的A100 GPU 上,他們將其減少到了66%。
此外,他們還提出了一個新的概念,即 Transformer 網路中的運算不變性(computational invariance),它使 SliceGPT 成為可能。
SliceGPT 詳解
#SliceGPT 方法依賴 Transformer 架構中固有的運算不變性。這意味著,你可以對一個元件的輸出套用一個正交變換,只要在下一個元件中撤銷即可。作者觀察到,在網路區塊之間執行的 RMSNorm 運算不會影響變換:這些運算是可交換的。
在論文中,作者首先介紹了在 RMSNorm 連接的 Transformer 網路中如何實現不變性,然後說明如何將使用 LayerNorm 連接訓練的網路轉換為 RMSNorm。接下來,他們介紹了使用主成分分析法(PCA)計算各層變換的方法,從而將區塊間的訊號投射到其主成分上。最後,他們介紹了刪除次要主成分如何對應於切掉網路的行或列。
Transformer 網路的運算不變性
以Q 表示正交矩陣: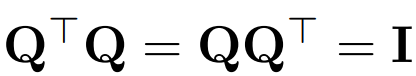
- 注意,向量 x 乘以 Q 不會改變向量的 norm,因為在這項工作中,Q 的維度總是與 transformer D 的嵌入維度相符。
假設 X_ℓ 是 transformer 一個區塊的輸出,經過 RMSNorm 處理後,以 RMSNorm (X_ℓ) 的形式輸入到下一個區塊。如果在RMSNorm 之前插入具有正交矩陣Q 的線性層,並在RMSNorm 之後插入Q^⊤,那麼網路將保持不變,因為訊號矩陣的每一行都要乘以Q、歸一化並乘以Q^ ⊤。這裡有:
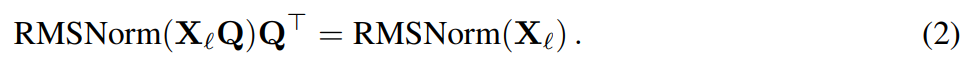
現在,由於網路中的每個注意力或FFN 區塊都對輸入和輸出進行了線性運算,可以將額外的運算Q 吸收到模組的線性層。由於網路包含殘差連接,因此也必須將 Q 應用於所有先前的層(一直到嵌入)和所有後續層(一直到 LM Head)的輸出。
不變函數是指輸入變換不會導致輸出改變的函數。在本文的例子中,可以對 transformer 的權重應用任何正交變換 Q 而不改變結果,因此計算可以在任何變換狀態下進行。作者將此稱為計算不變性,並在下面的定理中加以定義。
定理1:設 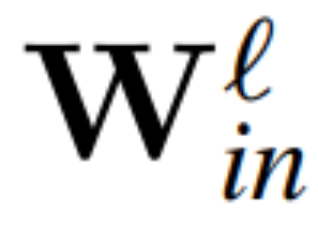 與
與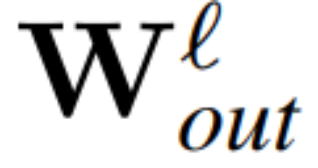 為RMSNorm 連接的transformer 網路第ℓ 區塊線性層的權重矩陣,
為RMSNorm 連接的transformer 網路第ℓ 區塊線性層的權重矩陣,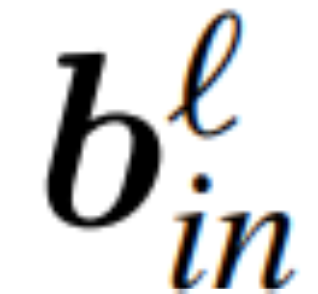 、
、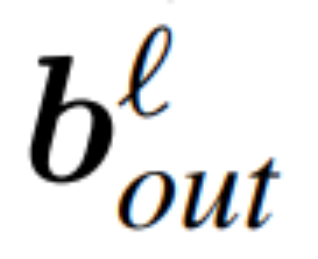 為對應的偏移(如果有),W_embd 和W_head 為嵌入矩陣和頭矩陣。設Q 是維數為D 的正交矩陣,那麼下面的網路就等同於原來的transformer 網路:
為對應的偏移(如果有),W_embd 和W_head 為嵌入矩陣和頭矩陣。設Q 是維數為D 的正交矩陣,那麼下面的網路就等同於原來的transformer 網路:
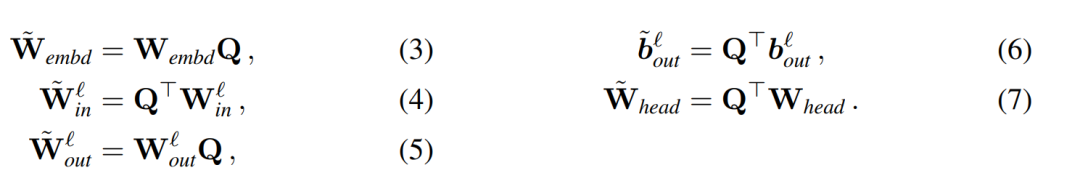
##複製輸入偏壓與頭偏壓:
可以用演算法1 來證明,轉換後的網路計算出的結果與原始網路相同。
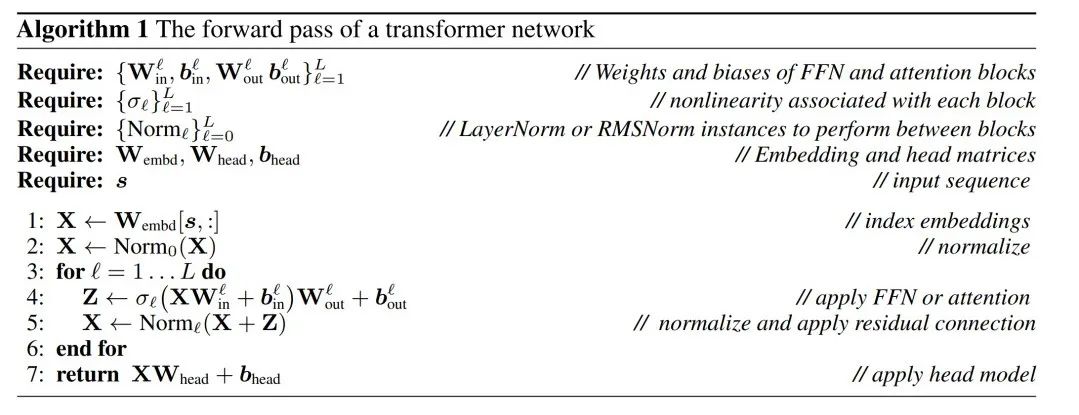
#LayerNorm Transformer 可以轉換成RMSNorm
Transformer 網路的運算不變性僅適用於RMSNorm 連線的網路。在處理使用 LayerNorm 的網路之前,作者先將 LayerNorm 的線性區塊吸收到相鄰區塊中,將網路轉換為 RMSNorm。
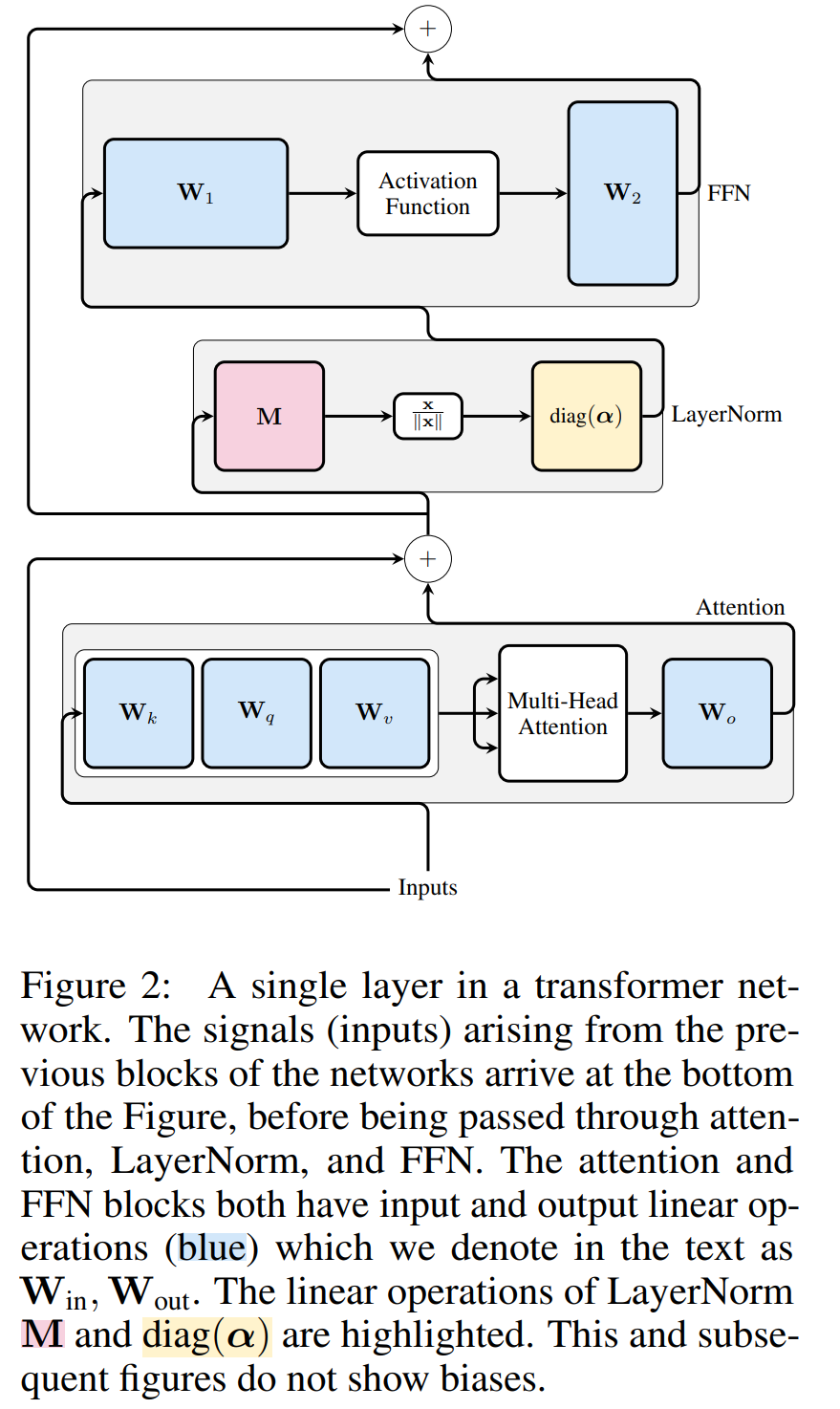
圖 3 顯示了 Transformer 網路(見圖 2)的這種轉換。在每個區塊中,作者將輸出矩陣 W_out 與均值減法矩陣 M 相乘,後者考慮了後續 LayerNorm 中的平均值減法。輸入矩陣 W_in 被前面 LayerNorm 區塊的比例預乘。嵌入矩陣 W_embd 必須進行均值減法,而 W_head 必須按照最後一個 LayerNorm 的比例重新縮放。這只是運算順序的簡單改變,不會影響網路輸出。
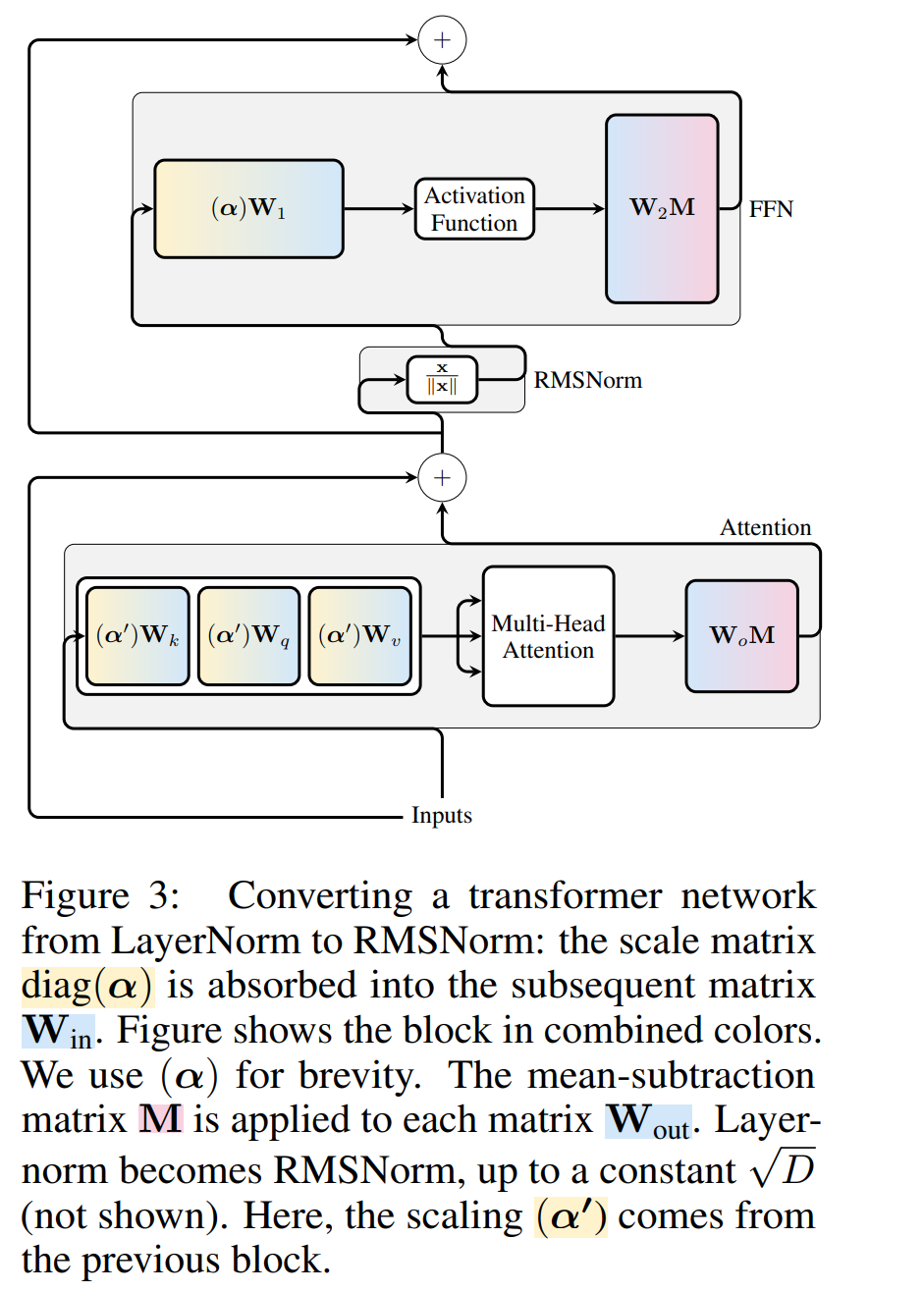
每個區塊的轉換
#現在transformer 中的每個LayerNorm 都已轉換為RMSNorm,可以選擇任意Q 來修改模型。作者最初的計劃是從模型中收集訊號,利用這些訊號來建立一個正交矩陣,然後刪除部分網路。他們很快就發現,網路中不同區塊的訊號並沒有對齊,因此他們需要在每個區塊上應用不同的正交矩陣,也就是 Q_ℓ。
如果每個區塊使用的正交矩陣不同,則模型不會改變,證明方法與定理 1 相同,但演算法 1 第 5 行除外。在這裡可以看到,殘差連接和區塊的輸出必須具有相同的旋轉。為了解決這個問題,作者透過對殘差進行線性變換 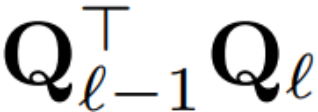 來修改殘差連接。
來修改殘差連接。
圖 4 顯示如何透過對殘差連接進行額外的線性運算,對不同的區塊進行不同的旋轉。與權重矩陣的修改不同,這些附加運算無法預先計算,並且會為模型增加少量(D × D)開銷。儘管如此,還是需要透過這些操作來對模型進行切除操作,而且可以看到整體速度確實加快了。
為了計算矩陣 Q_ℓ,作者使用了 PCA。他們從訓練集中選擇一個校準資料集,在模型中運行(在將 LayerNorm 運算轉換為 RMSNorm 之後),並提取該層的正交矩陣。更確切地說,如果 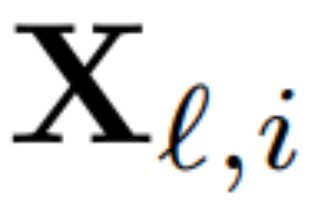 他們使用轉換後網路的輸出來計算下一層的正交矩陣。更確切地說,如果
他們使用轉換後網路的輸出來計算下一層的正交矩陣。更確切地說,如果 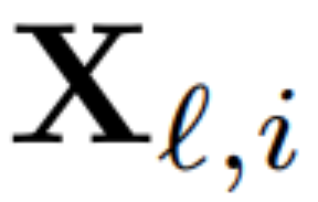 是校準資料集中第i 個序列的第ℓ 個RMSNorm 模組的輸出,計算:
是校準資料集中第i 個序列的第ℓ 個RMSNorm 模組的輸出,計算:

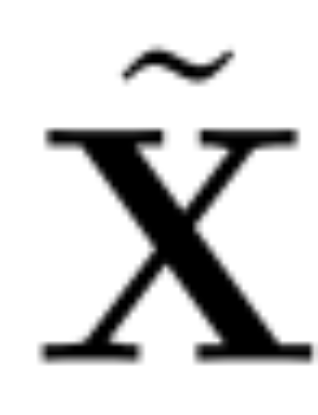
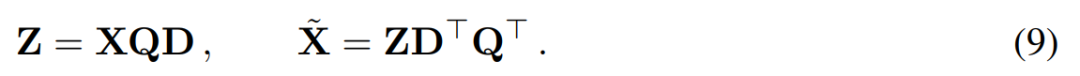
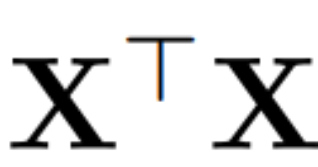
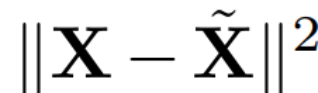
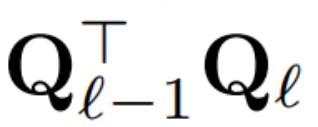
#主成分分析的目標通常是取得資料矩陣X 並計算低維表示Z 和近似重構:
#其中Q 是 # 的特徵向量,D是一個D × D 小刪除矩陣(包含D × D 同位矩陣的D 小列),用來刪除矩陣左邊的一些列。從 QD 是最小化 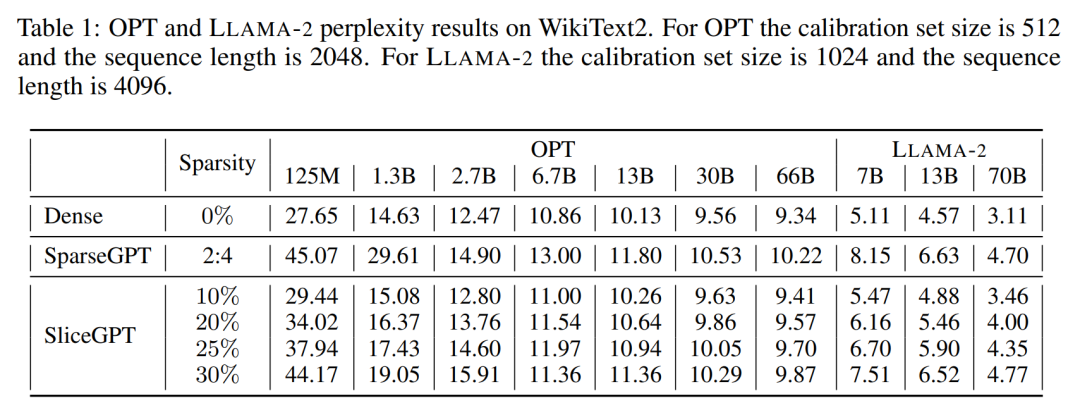 的線性映射的意義上來說,重建是 L_2 最佳(L_2 optimal)的。
的線性映射的意義上來說,重建是 L_2 最佳(L_2 optimal)的。
當對區塊間的訊號矩陣X 應用PCA 時,作者從未將N × D 訊號矩陣具體化,而是將刪除矩陣D 應用於建構此矩陣前後的運算。在上述運算中,此矩陣已乘以 Q。作者刪除了 W_in 的行以及 W_out 和 W_embd 的欄位。他們也刪除了插入到殘差連結中的矩陣 的行和列(見圖 4)。
#########實驗結果###############產生任務################### ##作者對經過SliceGPT 和SparseGPT 剪裁後大小不同的OPT 和LLAMA-2 模型系列在WikiText-2 資料集中進行了效能評估。表 1 展示了模型經過不同等級的剪裁後保留的複雜度。相較於 LLAMA-2 模型,SliceGPT 在應用於 OPT 模型時表現出了更優越的性能,這與作者根據模型頻譜的分析得出的推測相符。 ###########################SliceGPT 的效能將隨著模型規模的增加而提升。在對所有 LLAMA-2 系列模型剪裁 25% 情況下,SparseGPT 2:4 模式的表現都遜於 SliceGPT。對於 OPT,可以發現在 2.7B 模型之外的所有模型中,30% 切除比例的模型的稀疏性都優於 2:4 的稀疏性。 ######零樣本任務
作者採用了PIQA、WinoGrande、HellaSwag、ARC-e 和ARCc 五個任務來評估SliceGPT 在零樣本任務上的表現,他們在評估中使用了LM Evaluation Harness 作為預設參數。
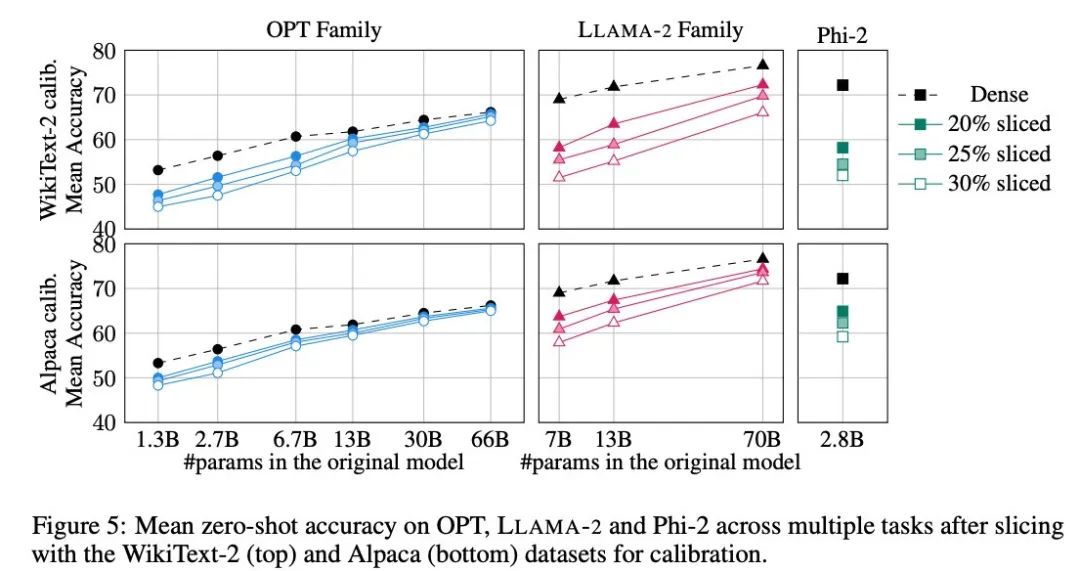
圖 5 展示了經過剪裁的模型在上述任務中所獲得的平均分數。圖中上行顯示的是 SliceGPT 在 WikiText-2 中的平均準確率,下行顯示的是 SliceGPT 在 Alpaca 的平均準確率。從結果可以觀察到與生成任務類似的結論:OPT 模型比 LLAMA-2 模型更適應壓縮,越大的模型經過剪裁後精確度的下降越不明顯。
作者在 Phi-2 這樣的小模型中測試了 SliceGPT 的效果。經過剪裁的 Phi-2 模型與經過剪裁的 LLAMA-2 7B 模型表現相當。最大型的 OPT 和 LLAMA-2 模型可以有效壓縮,當從 66B 的 OPT 模型中刪除 30% 時,SliceGPT 可以做到僅損失了幾個百分點。
作者也進行了恢復微調(RFT)實驗。使用 LoRA 對剪裁過的 LLAMA-2 和 Phi-2 模型進行了少量 RFT。
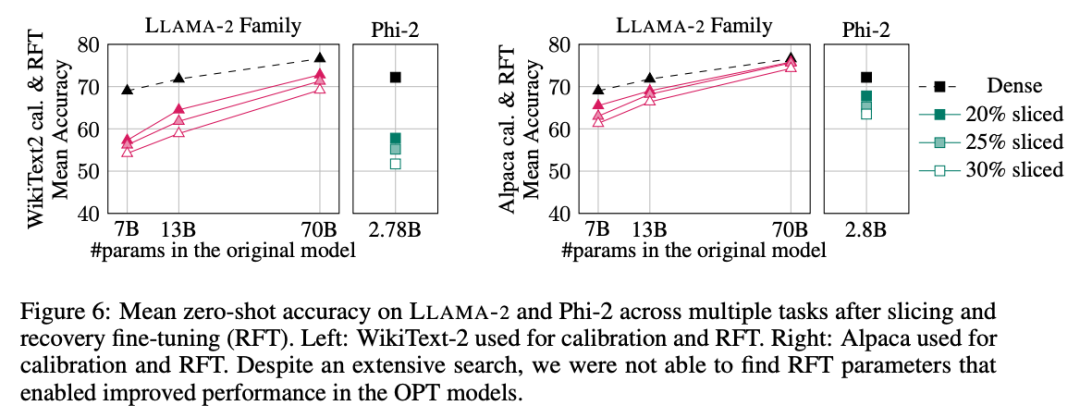
實驗結果如圖 6 所示。可以發現,RFT 的結果在 WikiText-2 和 Alpaca 資料集上存在顯著差異,模型在 Alpaca 資料集中展現了更好的效能。作者認為出現差異的原因在於 Alpaca 資料集中的任務和基準任務更接近。
對於規模最大的LLAMA-2 70B 模型,剪裁30% 再進行RFT 後,最終在Alpaca 資料集中的平均準確率為74.3%,原稠密模型的準確率為76.6%。經過剪裁的模型 LLAMA-2 70B 保留了約 51.6B 個參數,其吞吐量得到了顯著提高。
作者也發現Phi-2 無法在WikiText-2 資料集中,從被剪裁過的模型中恢復原有準確率,但在Alpaca 資料集中能恢復幾個百分點的準確率。被剪裁 25% 並經過 RFT 的 Phi-2 在 Alpaca 資料集中,平均準確率為 65.2%,原稠密模型的準確率為 72.2%。剪裁過的模型保留了 2.2B 個參數,保留了 2.8B 模型準確率的 90.3%。這表明即使是小型語言模型也可以有效剪枝。
基準吞吐量
#和傳統剪枝方法不同,SliceGPT 在矩陣X中引入了(結構化)稀疏性:整列X 被切掉,降低了嵌入維度。這種方法既增強了 SliceGPT 壓縮模型的計算複雜度(浮點運算次數),也提高了資料傳輸效率。
在 80GB 的 H100 GPU 上,將序列長度設為 128,並將序列長度批次翻倍以找到最大吞吐量,直到 GPU 記憶體耗盡或吞吐量下降。作者比較了剪裁過 25% 和 50% 的模型的吞吐量與原稠密模型 80GB 的 H100 GPU 上的吞吐量。剪裁過 25% 的模型最多達到了 1.55 倍的吞吐量提升。
在剪裁 50% 的情況下,最大的模型在使用一個 GPU 時,吞吐量實現了 3.13 倍和 1.87 倍的大幅增加。這表明在 GPU 數量固定的情況下,被剪裁過的模型的吞吐量將分別達到原稠密模型的 6.26 倍和 3.75 倍。
經過 50% 的剪裁後,雖然 SliceGPT 在 WikiText2 中的保留的複雜度比 SparseGPT 2:4 差,但吞吐量卻遠超 SparseGPT 的方法。對於大小為 13B 的模型,在記憶體較少的消費級 GPU 上,小模型的吞吐量可能也會有所提高。
推理時間
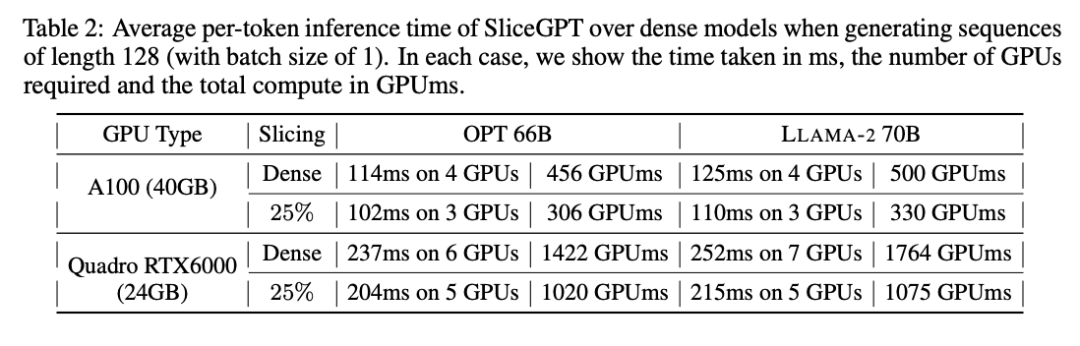
#作者也研究了使用SliceGPT 壓縮的模型從端到端的運轉時間。表 2 比較了在 Quadro RTX6000 和 A100 GPU 上,OPT 66B 和 LLAMA-2 70B 模型產生單一 token 所需的時間。可以發現,在 RTX6000 GPU 上,對模型剪裁過 25% 後,推理速度提高了 16-17%;在 A100 GPU 上,速度提高了 11-13%。相比原稠密模型,對於 LLAMA-2 70B,使用 RTX6000 GPU 所需的計算量減少了 64%。作者將這種提升歸功於 SliceGPT 採用了用較小的權重矩陣替換原權重矩陣,並使用了 dense kernels ,這是其他剪枝方案無法實現的。
作者表示,在撰寫本文時,他們的基準 SparseGPT 2:4 無法實現端到端的效能提升。相反,他們透過比較 transformer 層中每個運算的相對時間,將 SliceGPT 與 SparseGPT 2:4 進行比較。他們發現,對於大型模型,SliceGPT (25%) 與 SparseGPT (2:4) 在速度提升和困惑度方面具有競爭力。
計算成本
#所有LLAMA-2、OPT 和Phi-2 模型都可以在單一GPU 上花費1 到3 小時的時間進行切分。如表 3 所示,透過恢復微調,可以在 1 到 5 個小時內壓縮所有 LM。

了解更多內容,請參考原文。
以上是大模型也能切片,微軟SliceGPT讓LLAMA-2運算效率大增的詳細內容。更多資訊請關注PHP中文網其他相關文章!