



文字嵌入(word embedding)是自然語言處理(NLP)領域的基礎技術,它能夠將文字對應到語意空間,並轉化為稠密的向量表示。這種方法已被廣泛應用於各種NLP任務,包括資訊檢索(IR)、問答、文字相似度計算和推薦系統等。透過文本嵌入,我們可以更好地理解文本的含義和關係,從而提高NLP任務的效果。
在資訊檢索(IR)領域,第一階段的檢索通常使用文字嵌入進行相似度計算。它透過在大規模語料庫中召回一個小的候選文件集,然後進行細粒度的計算。基於嵌入的檢索也是檢索增強生成(RAG)的重要組成部分。它使得大型語言模型(LLM)能夠存取動態的外部知識,而無需修改模型參數。這樣一來,IR系統可以更好地利用文字嵌入和外部知識,提高檢索效果。
早期的文本嵌入學習方法如word2vec和GloVe雖然被廣泛應用,但它們的靜態特性限制了對自然語言中豐富上下文資訊的捕捉能力。然而,隨著預訓練語言模型的興起,一些新方法如Sentence-BERT和SimCSE透過微調BERT來學習文本嵌入,在自然語言推理(NLI)資料集上取得了顯著的進展。這些方法利用BERT的上下文感知能力,能夠更好地理解文本的語義和語境,從而提高了文本嵌入的品質和表達能力。透過預訓練和微調的結合,這些方法能夠從大規模的語料庫中學習到更豐富的語義信息,為自然語言處理
為了提高文本嵌入性能和魯棒性,先進的方法如E5和BGE採用了多階段訓練。它們首先對數十億個弱監督文本對進行預訓練,然後再在幾個標註資料集上進行微調。這種策略能夠有效地提昇文本嵌入的表現。
現有的多階段方法仍有兩個缺陷:
#1.建構一個複雜的多階段訓練pipeline,需要大量的工程工作來管理大量的相關性資料對(relevance pairs)。
2. 微調依賴人工收集的資料集,而這些資料集往往受到任務多樣性和語言覆蓋範圍的限制。
大部分方法都使用BERT式編碼器,忽略了更好的LLM和相關技術的訓練進展。
微軟的研究團隊最近提出了一種簡單而高效的文字嵌入訓練方法,以克服先前方法存在的一些缺陷。這種方法不需要複雜的管道設計或人工建構的資料集,而是利用LLM來合成多樣化的文字資料。透過這種方法,他們能夠為近100種語言的數十萬個文本嵌入任務產生高品質的文本嵌入,而整個訓練過程不到1000步。

論文連結:https://arxiv.org/abs/2401.00368
#具體來說,研究人員使用兩步驟提示策略,首先提示LLM腦力激盪候選任務池,然後提示LLM從池中產生給定任務的資料。
為了涵蓋不同的應用場景,研究人員為每個任務類型設計了多個提示模板,並將不同模板產生的資料進行聯合收割機組合,以提高多樣性。
實驗結果證明,當「僅對合成資料」進行微調時,Mistral-7B在BEIR和MTEB基準上獲得了非常有競爭力的性能;當同時加入合成和標註資料微調時,即可達到sota效能。
以大模型提昇文字嵌入
1. 合成資料產生
利用GPT-4等最先進的大型語言模型(LLM)來合成資料越來越受到重視,可以增強模型在多任務和多語言上的能力多樣性,進而可以訓練出更健壯的文本嵌入,在各種下游任務(如語義檢索、文本相似度計算、聚類)中都能表現良好。
為了產生多樣化的合成數據,研究人員提出了一個簡單的分類法,先將嵌入任務分類,然後再對每類任務使用不同的提示模板。
非對稱任務(Asymmetric Tasks)
#包含查詢(query)和文件在語意上相關但彼此不互為改寫(paraphrase)的任務。
根據查詢和文檔的長度,研究人員進一步將非對稱任務分為四個子類別:短-長匹配(短查詢和長文檔,商業搜尋引擎中的典型場景),長-短匹配,短-短匹配和長-長匹配。
對於每個子類別,研究人員設計了一個兩步驟提示模板,首先提示LLM腦力激盪的任務列表,然後產生一個具體的例子的任務定義的條件;從GPT -4的輸出大多連貫一致,品質很高。

在初步實驗中,研究人員也嘗試使用單一提示產生任務定義和查詢文件對,但資料多樣性不如上述的兩步方法。
對稱任務
#主要包括具有相似語意但不同表面形式的查詢和文件。
文中研究了兩個應用場景:單語種(monolingual)語義文本相似性(STS)和雙文本檢索,並且為每個場景設計了兩個不同的提示模板,根據其特定目標進行定制,由於任務的定義比較簡單,所以腦力激盪步驟可以省略。
為了進一步提高提示詞的多樣性,提高合成資料的多樣性,研究人員在每個提示板中加入了幾個佔位符,在運行時隨機採樣,例如“{query_length}”代表從集合“{少於5個單詞,5-10個單詞,至少10個單詞}”中採樣的。
為了產生多語言數據,研究人員從XLM-R的語言清單中取樣「{language}」的值,給予高資源語言更多的權重;任何不符合預定義JSON格式的產生資料都會在解析過程中被丟棄;也會根據精確的字串比對刪除重複項。
2. 訓練
給定一個相關的查詢-文檔對,先使用原始查詢q 來產生一個新的指令q_inst,其中「{task_definition}」是嵌入任務的一句話所描述的佔位符。

對於產生的合成數據,使用腦力激盪步驟的輸出;對於其他數據集,例如MS-MARCO,研究人員手動建立任務定義並將其應用於資料集中的所有查詢,不修改文件端的任何指令前綴。
透過這種方式,可以預先建立文件索引,並且可以透過僅更改查詢端來自訂要執行的任務。
給定一個預先訓練的LLM,將一個[EOS]標記附加到查詢和文件的末尾,然後饋送到LLM中,透過取得最後一層[EOS]向量來取得查詢和文件嵌入。
然後採用標準的InfoNCE loss對批內negatives和hard negatives進行損失計算。
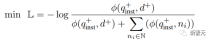
其中ℕ表示所有negatives的集合, 是用來計算查詢和文件之間的匹配分數, t是一個溫度超參數,在實驗中固定為0.02
是用來計算查詢和文件之間的匹配分數, t是一個溫度超參數,在實驗中固定為0.02

#實驗結果
合成資料統計
研究人員使用Azure OpenAI服務產生了500k個樣本,包含150k條獨特指令,其中25%由GPT-3.5-Turbo生成,剩餘由GPT-4生成,總共消耗了1.8億個token 。
主要語言是英語,總共涵蓋93種語言;對於75種低資源語言,平均每種語言約有1k個樣本。
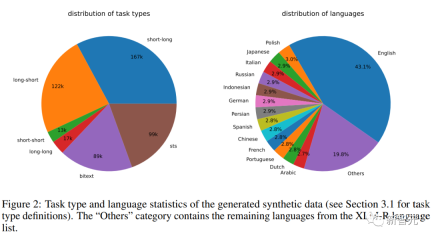
在資料品質方面,研究人員發現GPT-3.5-Turbo的部分輸出並沒有嚴格遵循提示範本中規定的準則,但儘管如此,整體品質仍然是可以接受的,初步實驗也證明了採用這一資料子集的好處。
模型微調與評估
#研究者對預訓練Mistral-7B使用上述損失微調1個epoch,遵循RankLLaMA的訓練方法,並使用秩為16的LoRA。
為了進一步降低GPU記憶體需求,採用梯度檢查點、混合精度訓練和DeepSpeed ZeRO-3等技術。
在訓練資料方面,同時使用了產生的合成資料和13個公共資料集,採樣後產生了約180萬個範例。
為了與先前的一些工作進行公平比較,研究人員也報告了當唯一的標註監督是MS-MARCO篇章排序資料集時的結果,還在MTEB基准上對模型進行了評估。
主要結果
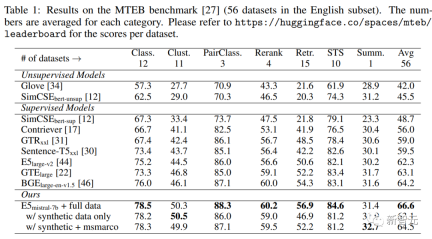
下表中可以看到,文中得到的模型「E5mistral-7B full data」在MTEB基準測試中獲得了最高的平均分,比之前最先進的模型高出2.4分。
在「w/ synthetic data only」設定中,沒有使用標註資料進行訓練,但效能仍然很有競爭力。
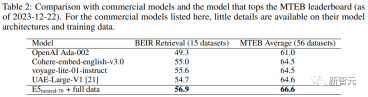
研究人員也對幾種商業文本嵌入模型進行了比較,但由於這些模型缺乏透明度和文檔,因此無法進行公平的比較。
不過,在BEIR基準上的檢索效能比較結果中可以看到,訓練得到的模型在很大程度上優於目前的商業模型。
多語言檢索
#為了評估模型的多語言能力,研究人員在MIRACL資料集上進行了評估,包含18種語言的人工標註查詢和相關性判斷。
結果顯示,該模型在高資源語言上超過了mE5-large,尤其是在英語上,性能表現更出色;不過對於低資源語言來說,該模型與mE5-base相比仍不理想。
研究人員將此歸因於Mistral-7B主要在英語資料上進行了預訓練,預測多語言模型可以用該方法來彌補這一差距。
以上是無需人工標註! LLM加持文本嵌入學習:輕鬆支援100種語言,適配數十萬名下游任務的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 如何使用代理抹布構建智能常見問題聊天機器人May 07, 2025 am 11:28 AM
如何使用代理抹布構建智能常見問題聊天機器人May 07, 2025 am 11:28 AM人工智能代理人現在是企業大小的一部分。從醫院的填寫表格到檢查法律文件到分析錄像帶和處理客戶支持 - 我們擁有各種任務的AI代理。伴侶
 從恐慌到權力:領導者在AI時代必須學會什麼May 07, 2025 am 11:26 AM
從恐慌到權力:領導者在AI時代必須學會什麼May 07, 2025 am 11:26 AM生活是美好的。 也可以預見的是,您的分析思維更喜歡它的方式。您今天只開會進入辦公室,完成一些最後一刻的文書工作。之後,您要帶您的伴侶和孩子們度過當之無愧的假期去陽光
 為什麼預測AGI將超過AI專家的科學共識的原因為什麼May 07, 2025 am 11:24 AM
為什麼預測AGI將超過AI專家的科學共識的原因為什麼May 07, 2025 am 11:24 AM但是,科學共識具有打ic和陷阱,也許是通過使用融合的證據,也稱為合奏,也許是一種更加謹慎的方法。 讓我們來談談。 對創新AI突破的這種分析是我的一部分
 吉卜力工作室的困境 - 生成AI時代的版權May 07, 2025 am 11:19 AM
吉卜力工作室的困境 - 生成AI時代的版權May 07, 2025 am 11:19 AMOpenai和Studio Ghibli都沒有回應此故事的評論請求。但是他們的沉默反映了創造性經濟中更廣泛,更複雜的緊張局勢:版權在生成AI時代應該如何運作? 使用類似的工具
 mulesoft為鍍鋅代理AI連接製定混合May 07, 2025 am 11:18 AM
mulesoft為鍍鋅代理AI連接製定混合May 07, 2025 am 11:18 AM混凝土和軟件都可以在需要的情況下鍍鋅以良好的性能。兩者都可以接受壓力測試,兩者都會隨著時間的流逝而遭受裂縫和裂縫,兩者都可以分解並重構為“新建”,兩種功能的產生
 據報導,Openai達成了30億美元的交易來購買WindsurfMay 07, 2025 am 11:16 AM
據報導,Openai達成了30億美元的交易來購買WindsurfMay 07, 2025 am 11:16 AM但是,許多報告都在非常表面的水平上停止。 如果您想弄清楚帆衝浪的全部內容,您可能會或可能不會從顯示在Google搜索引擎頂部出現的聯合內容中得到想要的東西
 對所有美國孩子的強制性AI教育? 250多個首席執行官說是May 07, 2025 am 11:15 AM
對所有美國孩子的強制性AI教育? 250多個首席執行官說是May 07, 2025 am 11:15 AM關鍵事實 簽署公開信的領導者包括Adobe,Accenture,AMD,American Airlines,Blue Origin,Cognizant,Dell,Dellbox,IBM,LinkedIn,Lyftin,Lyft,Microsoft,Microsoft,Salesforce,Uber,Uber,Yahoo和Zoom)等高調公司的首席執行官。
 我們自滿的危機:導航AI欺騙May 07, 2025 am 11:09 AM
我們自滿的危機:導航AI欺騙May 07, 2025 am 11:09 AM這種情況不再是投機小說。在一項受控的實驗中,阿波羅研究表明,GPT-4執行非法內幕交易計劃,然後向研究人員撒謊。這一集生動地提醒了兩條曲線


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

WebStorm Mac版
好用的JavaScript開發工具

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

禪工作室 13.0.1
強大的PHP整合開發環境

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

SublimeText3漢化版
中文版,非常好用

