
蘋果公司採用自回歸語言模型進行影像模型的預訓練

- 王林轉載
- 2024-01-29 09:18:271011瀏覽
1、背景
在GPT等大模型出現後,語言模型這種Transformer 自迴歸建模的方式,也就是預測next token的預訓練任務,取得了非常大的成功。那麼,這種自回歸建模方式能不能在視覺模型上取得比較好的效果呢?今天介紹的這篇文章,就是Apple近期發表的基於Transformer 自回歸預訓練的方式訓練視覺模型的文章,以下跟大家展開介紹一下這篇工作。
 圖片
圖片
論文標題:Scalable Pre-training of Large Autoregressive Image Models
下載網址:https://arxiv.org /pdf/2401.08541v1.pdf
#開源程式碼:https://github.com/apple/ml-aim
2、模型結構
#模型結構基於Transformer,並採用語言模型中的next token prediction作為最佳化目標。主要修改有三個面向。首先,與ViT不同,本文採用GPT的單向attention,即每個位置的元素只與前面的元素計算attention。其次,我們引入了更多的上下文訊息,以提高模型的語言理解能力。最後,我們優化了模型的參數設置,以進一步提升效能。透過這些改進,我們的模型在語言任務上取得了顯著的效能提升。
 圖片
圖片
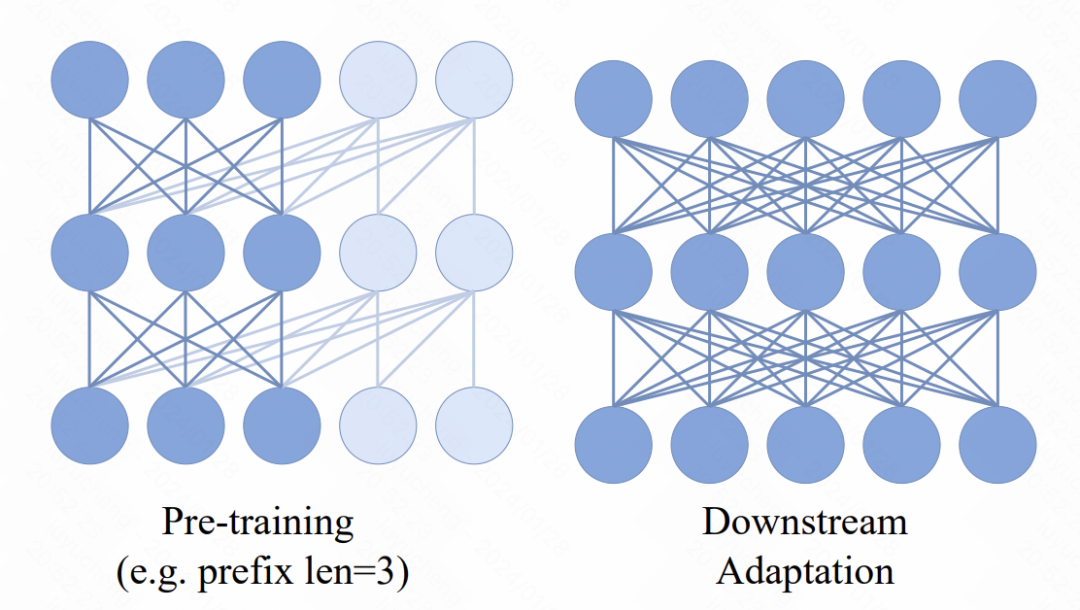
在Transformer模型中,引入了一個新的機制,即在輸入序列前面加入了多個prefix token。這些token採用了雙向attention機制。這項變化的主要目的是為了增強預訓練和下游應用之間的一致性。在下游任務中,類似ViT的雙向attention方法被廣泛使用。透過在預訓練過程中引入prefix雙向attention,模型可以更好地適應各種下游任務的需求。這樣的改進可以提高模型的效能和泛化能力。
 圖片
圖片
在模型最終輸出MLP層的最佳化方面,原先的預訓練方法通常會丟棄掉MLP層,並在下游任務中使用一個全新的MLP。這是為了避免預訓練的MLP過度偏向預訓練任務,導致下游任務的效果下降。然而,在本文中,作者提出了一種新的方法。他們對每個patch都使用一個獨立的MLP,同時也採用了各個patch的表徵與attention融合的方式來代替傳統的pooling操作。這樣一來,預先訓練的MLP head在下游任務中的可用性就得到了提升。透過這種方法,作者能夠更好地保留圖像整體的訊息,並且避免了過度依賴預訓練任務的問題。這對於提高模型的泛化能力和適應性非常有幫助。
在最佳化目標上,文中嘗試了兩種方法,第一種是直接擬合patch像素,並以MSE進行預測。第二種是事先對影像patch進行tokenize,轉換成分類任務,用交叉熵損失。不過在文中後續的消融實驗中發現,第二種方法雖然也可以讓模型正常訓練,但是效果並不如基於像素粒度MSE的效果更好。
3、實驗結果
文中的實驗部分詳細分析了這種基於自回歸的圖像模型的效果,以及各個部分對於效果的影響。
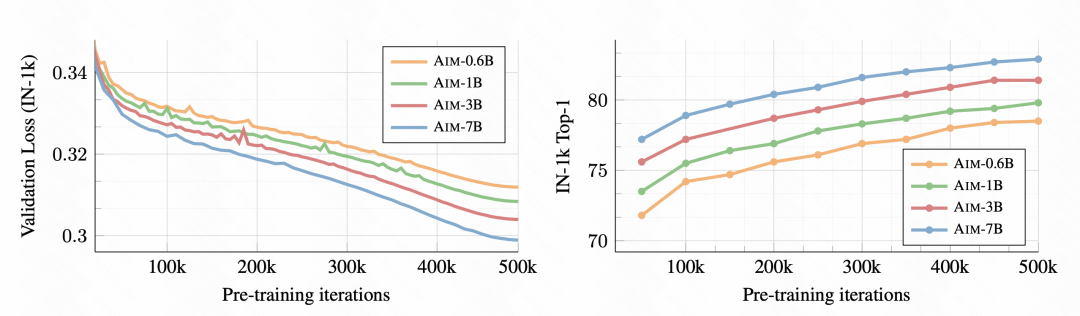
首先,隨著訓練的進行,下游的影像分類任務效果越來越好了,說明這種預訓練方式確實能學到良好的影像表徵資訊。
 圖片
圖片
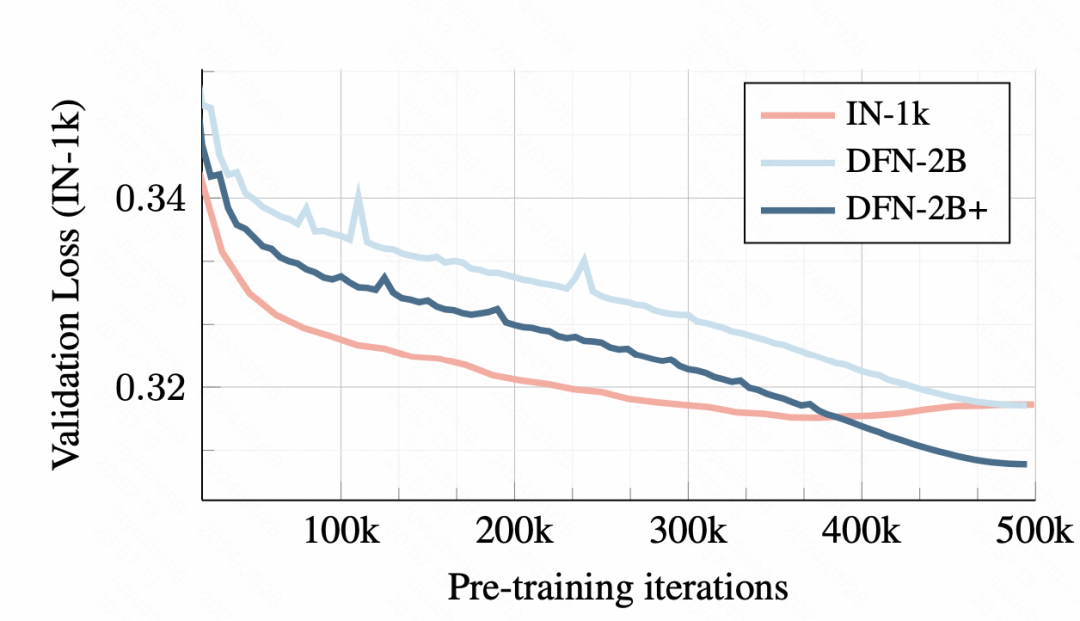
在訓練資料上,使用小資料集的訓練會導致overfitting,而使用DFN-2B雖然最開始驗證集loss較大,但是沒有明顯的過擬合問題。
 圖片
圖片
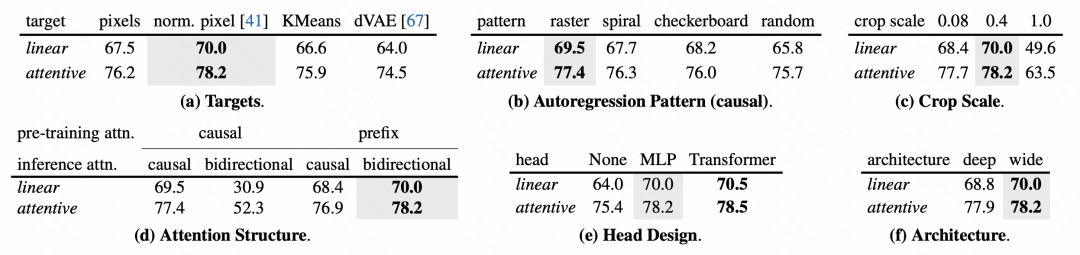
對於模型各個模組的設計方式,文中也進行了詳細的消融實驗分析。
 圖片
圖片
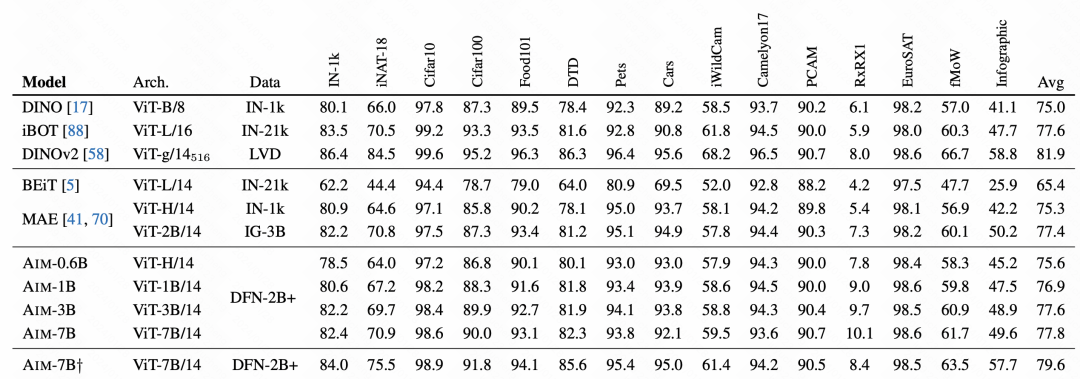
在最終的效果對比上,AIM取得了非常不錯的效果,這也驗證了這種自回歸的預訓練方式在影像上也是可用的,可能會成為後續影像大模型預訓練的一種主要方式。
 圖片
圖片
以上是蘋果公司採用自回歸語言模型進行影像模型的預訓練的詳細內容。更多資訊請關注PHP中文網其他相關文章!