



近端策略最佳化(Proximal Policy Optimization,PPO)是一種強化學習演算法,旨在解決深度強化學習中的訓練不穩定和樣本效率低的問題。 PPO演算法基於策略梯度,透過優化策略以最大化長期回報來訓練智能體。相較於其他演算法,PPO具有簡單、高效、穩定等優點,因此在學術界和工業界廣泛應用。 PPO透過兩個關鍵概念來改進訓練過程:近端策略優化和剪切目標函數。近端策略優化透過限制策略更新的大小,確保每次更新都在可接受的範圍內,從而保持訓練的穩定性。剪切目標函數是PPO演算法的核心思想,它在更新策略時,使用剪切目標函數來約束策略更新的幅度,避免過大的更新導致訓練不穩定。 PPO演算法在實踐中表現出良好的性能
在PPO演算法中,策略由神經網路表示。神經網路接受當前狀態作為輸入,並為每個可用動作輸出一個機率值。在每個時間步,智能體根據策略網路輸出的機率分佈來選擇一個動作。然後,智能體執行該動作並觀察下一個狀態和獎勵訊號。這個過程將不斷重複,直到任務結束。透過不斷重複這個過程,智能體能夠學習如何根據當前狀態選擇最優的動作來最大化累積獎勵。 PPO演算法透過優化策略更新的步長和更新幅度來平衡策略的探索和利用,從而提高演算法的穩定性和性能。
PPO演算法的核心思想是利用近端策略優化的方法進行策略優化,以避免策略更新過於激進而導致效能下降的問題。具體而言,PPO演算法採用剪切函數來限制新策略與舊策略之間的差異在給定範圍內。這個剪切函數可以是線性、二次或指數函數等。透過使用剪切函數,PPO演算法能夠平衡策略更新的劇烈程度,進而提升演算法的穩定性和收斂速度。這種近端策略最佳化的方法使得PPO演算法在強化學習任務中表現出良好的表現和穩健性。
PPO(Proximal Policy Optimization)演算法的核心在於透過更新策略網路的參數來提高政策在目前環境下的適應性。具體而言,PPO演算法透過最大化PPO目標函數來更新策略網路的參數。這個目標函數由兩個部分組成:一部分是策略的最佳化目標,即最大化長期回報;另一部分是一個約束項,用於限制更新後的策略與原始策略之間的差異。透過這種方式,PPO演算法可以在確保穩定性的同時,有效更新策略網路的參數,提升策略的效能。
在PPO演算法中,為了約束更新後的策略與原始策略之間的差異,我們使用一種稱為裁剪(clipping)的技術。具體而言,我們會將更新後的策略與原始策略進行比較,並限制它們之間的差異不超過一個小的閾值。這種裁切技術的作用在於確保更新後的策略不會太遠離原始策略,從而避免在訓練過程中出現過大的更新,從而導致訓練的不穩定性。透過裁切技術,我們能夠平衡更新的幅度,確保訓練的穩定性和收斂性。
PPO演算法透過取樣多個軌跡來利用經驗數據,從而提高樣本效率。在訓練過程中,會採樣多個軌跡,然後使用這些軌跡來估計策略的長期報酬和梯度。這種採樣技術可以降低訓練過程中的方差,從而提高訓練的穩定性和效率。
PPO演算法的最佳化目標是最大化期望回報,其中回報是指從當前狀態開始,執行一系列動作後得到的累積獎勵。 PPO演算法使用一種稱為「重要性取樣」的方法來估計策略梯度,即對於當前狀態和動作,比較當前策略和舊策略的機率比值,將其作為權重,乘以獎勵值,最終得到策略梯度。
總之,PPO演算法是一種高效能、穩定、易於實現的策略最佳化演算法,適用於解決連續控制問題。它採用近端策略最佳化的方法來控制策略更新的幅度,同時使用重要性取樣和價值函數裁剪的方法來估計策略梯度。這些技術的組合使PPO演算法在各種環境下都表現出色,成為目前最受歡迎的強化學習演算法之一。
以上是優化近端策略演算法(PPO)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 使用Pydantic構建結構化研究自動化系統Apr 24, 2025 am 10:32 AM
使用Pydantic構建結構化研究自動化系統Apr 24, 2025 am 10:32 AM在學術研究的動態領域,有效的信息收集,綜合和演示至關重要。 文獻綜述的手動過程是耗時的,阻礙了更深入的分析。 多代理研究助理系統BUI
 10 GPT-4O圖像生成會提示今天嘗試!Apr 24, 2025 am 10:26 AM
10 GPT-4O圖像生成會提示今天嘗試!Apr 24, 2025 am 10:26 AMAI世界中發生了絕對野生的事情。 Openai的本地形像生成現在很瘋狂。我們正在談論令人jaw目結舌的視覺效果,可怕的細節和拋光的輸出
 用帆板編碼的氛圍指南Apr 24, 2025 am 10:25 AM
用帆板編碼的氛圍指南Apr 24, 2025 am 10:25 AM毫不費力地將您的編碼願景帶入Codeium's Windsurf,這是您的AI驅動的編碼伴侶。 Windsurf簡化了整個軟件開發生命週期,從編碼和調試到優化,將過程轉換為INTU
 使用RMGB v2.0探索圖像背景刪除Apr 24, 2025 am 10:20 AM
使用RMGB v2.0探索圖像背景刪除Apr 24, 2025 am 10:20 AMBraiai的RMGB v2.0:強大的開源背景拆卸模型 圖像分割模型正在徹底改變各個領域,而背景刪除是進步的關鍵領域。 Braiai的RMGB v2.0是最先進的開源M
 評估大語模型中的毒性Apr 24, 2025 am 10:14 AM
評估大語模型中的毒性Apr 24, 2025 am 10:14 AM本文探討了大語言模型(LLM)中的毒性至關重要問題以及用於評估和減輕它的方法。 LLM,為從聊天機器人到內容生成的各種應用程序提供動力,需要強大的評估指標,機智
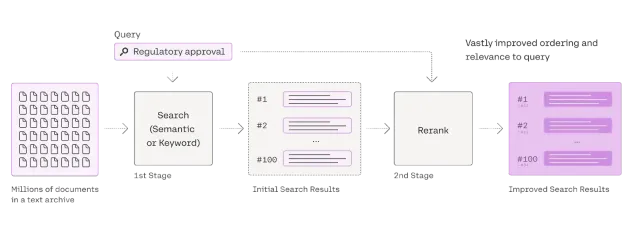 Rag Reranker的綜合指南Apr 24, 2025 am 10:10 AM
Rag Reranker的綜合指南Apr 24, 2025 am 10:10 AM檢索增強發電(RAG)系統正在轉換信息訪問,但其有效性取決於檢索到的數據的質量。 這是重讀者變得至關重要的地方 - 充當搜索結果的質量過濾器,以確保僅確保
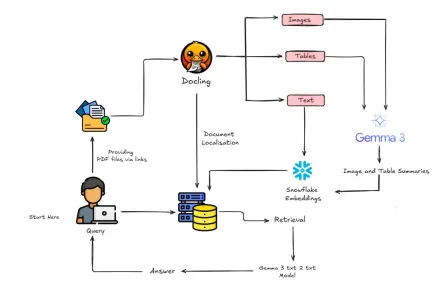 如何使用Gemma 3&Docling構建多模式抹布?Apr 24, 2025 am 10:04 AM
如何使用Gemma 3&Docling構建多模式抹布?Apr 24, 2025 am 10:04 AM該教程通過在Google Colab中構建精緻的多式聯運檢索一代(RAG)管道來指導您。 我們將使用Gemma 3(用於語言和視覺),文檔(文檔轉換),Langchain等尖端工具
 可擴展AI和機器學習應用的射線指南Apr 24, 2025 am 10:01 AM
可擴展AI和機器學習應用的射線指南Apr 24, 2025 am 10:01 AM雷:擴展AI和Python應用程序的有力框架 Ray是一個革命性的開源框架,旨在輕鬆擴展AI和Python應用程序。 它的直觀API使研究人員和開發人員可以通過其代碼過渡


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SublimeText3漢化版
中文版,非常好用

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript開發工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

