
自動化操作 DBMS的機器學習應用

- 王林轉載
- 2024-01-24 12:21:16712瀏覽
数据库管理系统(DBMS)是任何数据密集应用的关键部分。它们可以处理大量数据和复杂的工作负载,但同时也难以管理,因为有成百上千个“旋钮”(即配置变量)控制着各种要素,比如要使用多少内存做缓存和写入磁盘的频率。组织机构经常要雇佣专家来做调优,而专家对很多组织来说太过昂贵了。卡耐基梅隆大学数据库研究组的学生和研究人员在开发一个新的工具,名为 OtterTune,可以自动为 DBMS 的“旋钮”找到合适的设置。工具的目的是让任何人都可以部署 DBMS,即使没有任何数据库管理专长。
OtterTune 跟其他 DBMS 设置工具不同,因为它是利用对以前的 DBMS 调优知识来调优新的 DBMS,这显著降低了所耗时间和资源。OtterTune 通过维护一个之前调优积累的知识库来实现这一点,这些积累的数据用来构建机器学习(ML)模型,去捕获 DBMS 对不同的设置的反应。OtterTune 利用这些模型指导新的应用程序实验,对提升最终目标(比如降低延迟和增加吞吐量)给出建议的配置。
本文中,我们将讨论 OtterTune 的每一个机器学习流水线组件,以及它们是如何互动以便调优 DBMS 的设置。然后,我们评估 OtterTune 在 MySQL 和 Postgres 上的调优表现,将它的最优配置与 DBA 和其他自动调优工具进行对比。
OtterTune 是卡耐基梅隆大学数据库研究组的学生和研究人员开发的开源工具,所有的代码都托管在 Github 上,以 Apache License 2.0 许可证发布。
OtterTune 工作原理下图是 OtterTune 组件和工作流程
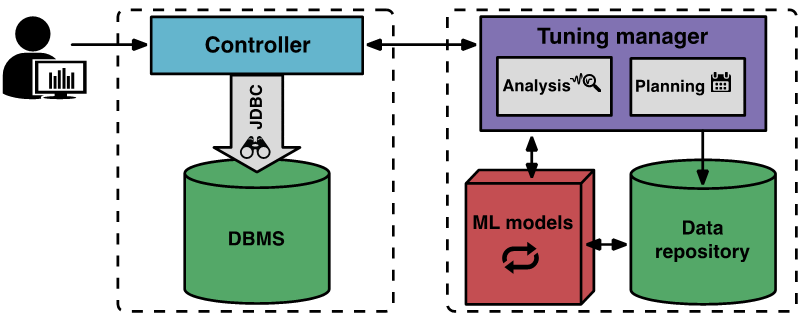
调优过程开始,用户告知 OtterTune 要调优的最终目标(比如,延迟或吞吐量),客户端控制器程序连接目标 DBMS,收集 Amazon EC2 实例类型和当前配置。
然后,控制器启动首次观察期,来观察并记录最终目标。观察结束后,控制器收集 DBMS 的内部指标,比如 MySQL 磁盘页读取和写入的计数。控制器将这些数据返回给调优管理器程序。
OtterTune 的调优管理器将接收到的指标数据保存到知识库。OtterTune 用这些结果计算出目标 DBMS 的下一个配置,连同预估的性能提升,返回给控制器。用户可以决定是否继续或终止调优过程。
注意OtterTune 对每个支持的 DBMS 版本维护了一份“旋钮”黑名单,包括了对调优无关紧要的部分(比如保存数据文件的路径),或者那些会产生严重或隐性后果(比如丢数据)的部分。调优过程开始时,OtterTune 会向用户提供这份黑名单,用户可以添加他们希望 OtterTune 避开的其它“旋钮”。
OtterTune 有一些预定假设,对某些用户可能会造成一定的限制。比如,它假设用户拥有管理员权限,以便控制器来修改 DBMS 配置。否则,用户必须在其他硬件上部署一份数据库拷贝给 OtterTune 做调优实验。这要求用户或者重现工作负载,或者转发生产 DBMS 的查询。完整的预设和限制请看我们的论文 。
机器学习流水线下图是 OtterTune ML 流水线处理数据的过程,所有的观察结果都保存在知识库中。
OtterTune 先将观察数据输送到“工作流特征化组件”Workload Characterization component,这个组件可以识别一小部分 DBMS 指标,这些指标能最有效地捕捉到性能变化和不同工作负载的显著特征。
下一步,“旋钮识别组件”Knob Identification component生成一个旋钮排序表,包含哪些对 DBMS 性能影响最大的旋钮。OtterTune 接着把所有这些信息“喂”给自动调优器Automatic Tuner,后者将目标 DBMS 的工作负载与知识库里最接近的负载进行映射,重新使用这份负载数据来生成更佳的配置。
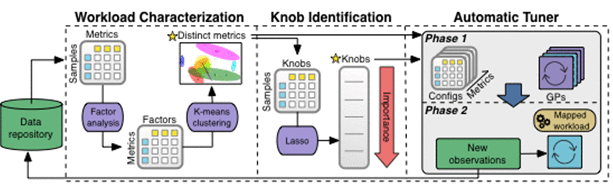
我们来深入挖掘以下机器学习流水线的每个组件。
工作負載特徵化: OtterTune 利用 DBMS 的內部執行時間指標來特徵化某個工作負載的行為,這些指標精確地代表了工作負載,因為它們捕捉了負載的多個面向行為。然而,許多指標是冗餘的:有些是用不同的單位表示相同的度量值,其他的表示 DBMS 的一些獨立組件,但它們的值高度相關。梳理冗餘度量值非常重要,可以降低機器學習模型的複雜度。因此,我們基於相關性將 DBMS 的測量值集中起來,然後選出其中最具代表性的一個,具體說就是最接近中間值的。機器學習的後續組件將使用這些度量值。
旋鈕辨識: DBMS 可以有幾百個旋鈕,但只有一部分會影響效能。 OtterTune 使用一種流行的「特性-選擇」技術,稱為 Lasso,來判斷哪些旋鈕對系統的整體性能影響最大。用這個技術處理知識庫中的數據,OtterTune 得以確定 DBMS 旋鈕的重要性順序。
接著,OtterTune 必須決定在做出配置建議時使用多少個旋鈕,旋鈕用的太多會明顯增加 OtterTune 的調優時間,而旋鈕用的太少則難以找到最好的配置。 OtterTune 用了一個增量方法來自動化這個過程,在一次調優過程中,逐步增加使用的旋鈕。這個方法讓 OtterTune 可以先用少量最重要的旋鈕來探索並調優配置,然後再擴大範圍考慮其他旋鈕。
自動調優器: 自動調優器元件在每次觀察階段後,透過兩步驟分析法來決定推薦哪個配置。
首先,系統使用工作負載特徵化組件找到的效能資料來確認與目前的目標DBMS 工作負載最接近的歷史調優過程,比較兩者的度量值以確認哪些值對不同的旋鈕設定有相似的反應。
然後,OtterTune 嘗試另一個旋鈕配置,將一個統計模型套用到收集的數據,以及知識庫中最貼近的工作負載數據。這個模型讓 OtterTune 預測 DBMS 在每個可能的配置下的表現。 OtterTune 調優下一個配置,在探索(收集用來改進模型的資訊)和利用(貪婪地接近目標度量值)之間交替進行。
實作OtterTune 用 Python 寫。
對於工作負載特徵化和旋鈕識別組件,運行時效能不是著重考慮的,所以我們用 scikit-learn實現對應的機器學習演算法。這些演算法運行在後台進程中,把新產生的資料吸收到知識庫裡。
對於自動調優元件,機器學習演算法就非常關鍵了。每次觀察階段完成後就需要運行,吸收新資料以便 OtterTune 挑選下一個旋鈕來進行測試。由於需要考慮效能,我們用 TensorFlow來實現。
為了收集 DBMS 的硬體、旋鈕配置和執行時間效能指標,我們把 OLTP-Bench 基準測試框架整合到 OtterTune 的控制器內。
實驗設計我們比較了 OtterTune 對 MySQL 和 Postgres 做出的最佳配置與如下配置方案進行了比較,以便評估:
預設: DBMS 初始設定
調優腳本: 一個開源調優建議工具所做的設定
DBA: 人類 DBA 選擇的配置
RDS: 將亞馬遜開發人員管理的 DBMS 的客製化設定套用到相同的 EC2 執行個體類型。
我們在亞馬遜 EC2 競價執行個體上執行了所有的實驗。每個實驗運行在兩個實例上,分別是m4.large 和 m3.xlarge 類型:一個用於 OtterTune 控制器,一個用於目標 DBMS 部署。 OtterTune 調優管理器和知識庫部署在本地一台 20 核心 128G 記憶體的伺服器上。
工作負載用的是 TPC-C,這是評估線上交易系統效能的工業標準。
評估我們給每個實驗中的資料庫 —— MySQL 和 Postgres —— 測量了延遲和吞吐量,下面的圖表顯示了結果。第一個圖表顯示了「第99百分位延遲」的數量,代表「最差情況下」完成一個事務的時長。第二個圖表顯示了吞吐量結果,以平均每秒執行的交易數來衡量。
MySQL 實驗結果OtterTune 產生的最佳配置與調優腳本和 RDS 的配置相比,OtterTune 讓 MySQL 的延遲下降了約 60%,吞吐量提升了 22% 到 35%。 OtterTune 也產生了幾乎跟 DBA 一樣好的配置。
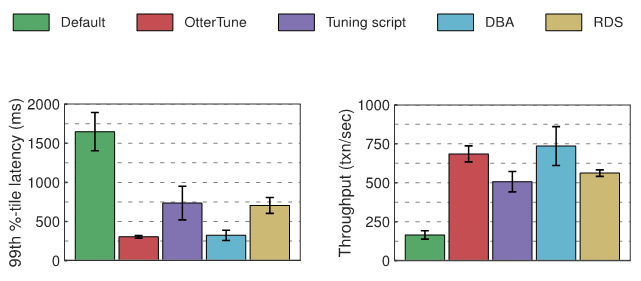
#在 TPC-C 負載下,只有幾個 MySQL 的旋鈕顯著影響效能。 OtterTune 和 DBA 的配置為這幾個旋鈕設定了很好的值。 RDS 表現略遜一籌,因為給一個旋鈕配置了欠佳的值。調優腳本表現最差,因為只修改一個旋鈕。
Postgres 實驗結果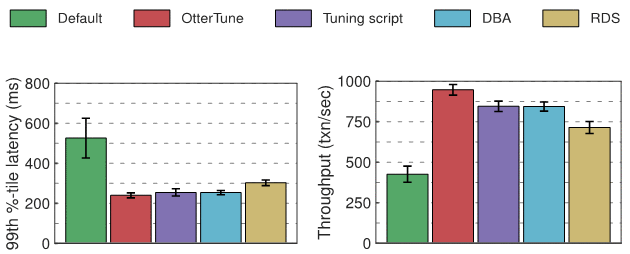
在延遲方面,相較於 Postgres 預設配置,OtterTune、調優工具、DBA 和 RDS 的配置獲得了近似的提升。我們大概可以把這歸於 OLTP-Bench 用戶端和 DBMS 之間的網路開銷。在吞吐量方面,Postgres 在 OtterTune 的配置下比 DBA 和調優腳本高 12%,比 RDS 高 32%。
結束語OtterTune 將尋找 DBMS 配置旋鈕的最優值這一過程自動化了。它透過重複使用先前的調優過程所收集的訓練數據,來調優新部署的 DBMS。因為 OtterTune 不需要產生初始化資料集來訓練它的機器學習模型,調優時間得以大幅減少。
下一步會怎麼樣?為了順應的越來越流行的 DBaaS (遠端登入 DBMS 主機是不可能的),OtterTune 很快就會能夠自動探查目標 DBMS 的硬體能力,而不需要遠端登入。
想了解 OtterTune 的詳細資料,請查看我們的論文和 GitHub 上的程式碼。關注這個網站,我們很快就會讓 OtterTune 成為一個線上調優服務。
以上是自動化操作 DBMS的機器學習應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!