



pandas資料清洗技巧大揭密!
導語:
在資料分析和機器學習中,資料清洗是一個非常重要的步驟,它涉及對資料集進行預處理、轉換和過濾,以便將資料整理為我們需要的格式和結構。而pandas是Python中最受歡迎且強大的資料分析庫之一,它提供了豐富且靈活的資料清洗工具和操作方法。本文將揭秘一些pandas資料清洗的基本技巧,並提供具體的程式碼範例,幫助讀者更能理解和應用這些技巧。
一、匯入pandas函式庫和資料集
在開始之前,首先需要安裝pandas函式庫。安裝完成後,可以使用以下程式碼匯入pandas庫,並載入需要進行清洗的資料集。
import pandas as pd
# 导入数据集
data = pd.read_csv('data.csv')二、查看資料集
在進行資料清洗之前,首先需要了解資料集的結構和內容。 pandas提供了幾個常用的函數來查看資料集,包括head()、tail()、shape和info()等。
程式碼範例:
# 查看前五行数据 print(data.head()) # 查看后五行数据 print(data.tail()) # 查看数据集的维度 print(data.shape) # 查看数据集的基本信息 print(data.info())
三、處理缺失值
缺失值是資料集中經常遇到的問題之一,而且在真實的資料集中很常見。 pandas提供了處理缺失值的多種方法。常見的處理缺失值的方法有刪除、填入和內插。
- 刪除缺失值
刪除缺失值是最簡單的處理方法之一,但需要謹慎使用。在pandas中,可以使用dropna()函數來刪除包含缺失值的行或列。
程式碼範例:
# 删除包含缺失值的行 data.dropna(axis=0, inplace=True) # 删除包含缺失值的列 data.dropna(axis=1, inplace=True)
- 填滿缺失值
#填滿缺失值是另一種常用的處理方法,它可以用一個常數或其他資料集中的值來填入缺失值。在pandas中,可以使用fillna()函數來填入缺失值。
程式碼範例:
# 使用0填充缺失值 data.fillna(0, inplace=True) # 使用平均值填充缺失值 data.fillna(data.mean(), inplace=True)
- 插值缺失值
#插值缺失值是一種更高級的處理方法,它可以根據已知資料的特徵來推測缺失值。在pandas中,可以使用interpolate()函數來進行插值處理。
程式碼範例:
# 线性插值处理缺失值 data.interpolate(method='linear', inplace=True) # 拟合插值处理缺失值 data.interpolate(method='quadratic', inplace=True)
四、處理重複值
重複值是另一個常見的資料集問題,它可能會導致資料分析和建模的偏差。 pandas提供了幾個函數來處理重複值,包括duplicated()和drop_duplicates()等。
- 找出重複值
可以使用duplicated()函數來找出資料集中的重複值。該函數傳回一個布林類型的Series對象,其中包含了每個元素是否重複的資訊。
程式碼範例:
# 查找重复值 duplicated_data = data.duplicated() # 打印重复值 print(duplicated_data)
- 刪除重複值
#可以使用drop_duplicates()函數來刪除資料集中的重複值。該函數傳回一個經過去重後的新資料集。
程式碼範例:
# 删除重复值 data.drop_duplicates(inplace=True)
五、處理異常值
異常值是資料集中的異常觀測值,它可能會對資料分佈和模型擬合產生不良影響。 pandas提供了一些函數和方法來識別和處理異常值,包括箱線圖、z-score和IQR等。
- 箱線圖
箱線圖是一種常用的異常值偵測方法,它可以用來判斷資料集中是否存在異常值。可以使用boxplot()函數來繪製箱線圖,並透過觀察箱線圖中的離群點來識別異常值。
程式碼範例:
# 绘制箱线图 data.boxplot(column='value', figsize=(10, 6)) # 显示图像 plt.show()
- z-score
#z-score是一種統計概念,它可以用來標準化資料並判斷觀測值是否偏離了平均值。在pandas中,可以使用zscore()函數來計算z-score,並透過設定閾值來判斷是否存在異常值。
程式碼範例:
# 计算z-score z_scores = (data - data.mean()) / data.std() # 判断是否存在异常值 outliers = z_scores[(z_scores > 3) | (z_scores < -3)] # 显示异常值 print(outliers)
- IQR
IQR(Inter-Quartile Range)是一種計算概念,它可以透過計算資料集的四分位差來決定異常值的範圍。在pandas中,可以使用quantile()函數來計算四分位數,然後使用IQR公式來判斷是否有異常值。
程式碼範例:
# 计算四分位差 Q1 = data.quantile(0.25) Q3 = data.quantile(0.75) IQR = Q3 - Q1 # 判断是否存在异常值 outliers = data[((data < (Q1 - 1.5 * IQR)) | (data > (Q3 + 1.5 * IQR))).any(axis=1)] # 显示异常值 print(outliers)
六、轉換資料型別
資料型別是資料集中一個重要的屬性,它涉及資料的儲存方式、計算方式和視覺化方式等。在pandas中,可以使用astype()函數來轉換資料型別。
程式碼範例:
# 将字符串类型转换为整数类型 data['column'] = data['column'].astype(int) # 将浮点型转换为整数类型 data['column'] = data['column'].astype(int) # 将字符串类型转换为日期类型 data['column'] = pd.to_datetime(data['column'])
七、其他常用操作
除了上述的資料清洗技巧外,pandas還提供了其他一些常用的資料清洗操作,包括重新命名列、拆分列和合併列等。
- 重新命名資料列
可以使用rename()函數來重新命名資料集中的資料列。
程式碼範例:
# 重命名列
data.rename(columns={'old_name': 'new_name'}, inplace=True)- 分割列
#可以使用str.split()函數來將含有多個值的列拆分成多個列。
程式碼範例:
# 拆分列
new_columns = data['column'].str.split(',', expand=True)
# 重新命名新列
new_columns.columns = ['column1', 'column2', 'column3']
# 合并新列到数据集
data = pd.concat([data, new_columns], axis=1)- 合併列
#可以使用pd.merge()函數來合併資料集中的多個列。
程式碼範例:
# 新数据集1
data1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value1': [1, 2, 3]})
# 新数据集2
data2 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value2': [4, 5, 6]})
# 合并数据集
merged_data = pd.merge(data1, data2, on='key')
# 打印合并后的数据集
print(merged_data)總結:
本文介紹了一些常用的pandas資料清洗技巧,並提供了具體的程式碼範例。這些技巧包括處理缺失值、處理重複值、處理異常值、轉換資料類型和其他常用操作。透過學習和應用這些技巧,讀者可以更好地處理和準備數據,為後續的數據分析和建模打下堅實的基礎。當然,除了本文介紹的這些技巧外,pandas還有許多其他功能和方法,讀者可以根據自己的需求和實際情況進一步深入學習和應用。
以上是揭示pandas資料清洗的重要技巧!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 python pandas安装方法Nov 22, 2023 pm 02:33 PM
python pandas安装方法Nov 22, 2023 pm 02:33 PMpython可以通过使用pip、使用conda、从源代码、使用IDE集成的包管理工具来安装pandas。详细介绍:1、使用pip,在终端或命令提示符中运行pip install pandas命令即可安装pandas;2、使用conda,在终端或命令提示符中运行conda install pandas命令即可安装pandas;3、从源代码安装等等。
 日常工作中,Python+Pandas是否能代替Excel+VBA?May 04, 2023 am 11:37 AM
日常工作中,Python+Pandas是否能代替Excel+VBA?May 04, 2023 am 11:37 AM知乎上有个热门提问,日常工作中Python+Pandas是否能代替Excel+VBA?我的建议是,两者是互补关系,不存在谁替代谁。复杂数据分析挖掘用Python+Pandas,日常简单数据处理用Excel+VBA。从数据处理分析能力来看,Python+Pandas肯定是能取代Excel+VBA的,而且要远远比后者强大。但从便利性、传播性、市场认可度来看,Excel+VBA在职场工作上还是无法取代的。因为Excel符合绝大多数人的使用习惯,使用成本更低。就像Photoshop能修出更专业的照片,为
 如何使用Python中的Pandas按特定列合并两个CSV文件?Sep 08, 2023 pm 02:01 PM
如何使用Python中的Pandas按特定列合并两个CSV文件?Sep 08, 2023 pm 02:01 PMCSV(逗号分隔值)文件广泛用于以简单格式存储和交换数据。在许多数据处理任务中,需要基于特定列合并两个或多个CSV文件。幸运的是,这可以使用Python中的Pandas库轻松实现。在本文中,我们将学习如何使用Python中的Pandas按特定列合并两个CSV文件。什么是Pandas库?Pandas是一个用于Python信息控制和检查的开源库。它提供了用于处理结构化数据(例如表格、时间序列和多维数据)以及高性能数据结构的工具。Pandas广泛应用于金融、数据科学、机器学习和其他需要数据操作的领域。
 时间序列特征提取的Python和Pandas代码示例Apr 12, 2023 pm 05:43 PM
时间序列特征提取的Python和Pandas代码示例Apr 12, 2023 pm 05:43 PM使用Pandas和Python从时间序列数据中提取有意义的特征,包括移动平均,自相关和傅里叶变换。前言时间序列分析是理解和预测各个行业(如金融、经济、医疗保健等)趋势的强大工具。特征提取是这一过程中的关键步骤,它涉及将原始数据转换为有意义的特征,可用于训练模型进行预测和分析。在本文中,我们将探索使用Python和Pandas的时间序列特征提取技术。在深入研究特征提取之前,让我们简要回顾一下时间序列数据。时间序列数据是按时间顺序索引的数据点序列。时间序列数据的例子包括股票价格、温度测量和交通数据。
 pandas写入excel有哪些方法Nov 22, 2023 am 11:46 AM
pandas写入excel有哪些方法Nov 22, 2023 am 11:46 AMpandas写入excel的方法有:1、安装所需的库;2、读取数据集;3、写入Excel文件;4、指定工作表名称;5、格式化输出;6、自定义样式。Pandas是一个流行的Python数据分析库,提供了许多强大的数据清洗和分析功能,要将Pandas数据写入Excel文件,可以使用Pandas提供的“to_excel()”方法。
 pandas如何读取txt文件Nov 21, 2023 pm 03:54 PM
pandas如何读取txt文件Nov 21, 2023 pm 03:54 PMpandas读取txt文件的步骤:1、安装Pandas库;2、使用“read_csv”函数读取txt文件,并指定文件路径和文件分隔符;3、Pandas将数据读取为一个名为DataFrame的对象;4、如果第一行包含列名,则可以通过将header参数设置为0来指定,如果没有,则设置为None;5、如果txt文件中包含缺失值或空值,可以使用“na_values”指定这些缺失值。
 pandas怎么读取csv文件Dec 01, 2023 pm 04:18 PM
pandas怎么读取csv文件Dec 01, 2023 pm 04:18 PM读取CSV文件的方法有使用read_csv()函数、指定分隔符、指定列名、跳过行、缺失值处理、自定义数据类型等。详细介绍:1、read_csv()函数是Pandas中最常用的读取CSV文件的方法。它可以从本地文件系统或远程URL加载CSV数据,并返回一个DataFrame对象;2、指定分隔符,默认情况下,read_csv()函数将使用逗号作为CSV文件的分隔符等等。
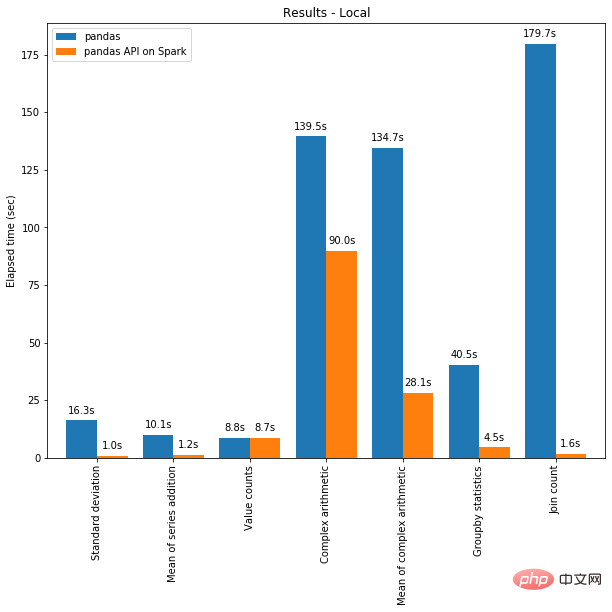 Pandas 与 PySpark 强强联手,功能与速度齐飞!May 01, 2023 pm 09:19 PM
Pandas 与 PySpark 强强联手,功能与速度齐飞!May 01, 2023 pm 09:19 PM使用Python做数据处理的数据科学家或数据从业者,对数据科学包pandas并不陌生,也不乏像云朵君一样的pandas重度使用者,项目开始写的第一行代码,大多是importpandasaspd。pandas做数据处理可以说是yyds!而他的缺点也是非常明显,pandas只能单机处理,它不能随数据量线性伸缩。例如,如果pandas试图读取的数据集大于一台机器的可用内存,则会因内存不足而失败。另外pandas在处理大型数据方面非常慢,虽然有像Dask或Vaex等其他库来优化提升数


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

Atom編輯器mac版下載
最受歡迎的的開源編輯器

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

禪工作室 13.0.1
強大的PHP整合開發環境

