
隨機森林演算法原理及實際應用的Python範例(附完整程式碼)

- 王林轉載
- 2024-01-23 18:09:061199瀏覽
隨機森林演算法是一種整合技術,能夠使用多個決策樹和一種稱為Bootstrap和聚合的技術來執行回歸和分類任務。這背後的基本想法是結合多個決策樹來確定最終輸出,而不是依賴單一決策樹。
機器學習中的隨機森林
隨機森林產生大量分類樹。將輸入向量放在森林中的每棵樹下,以根據輸入向量對新物件進行分類。每棵樹都分配了一個分類,我們可以稱之為“投票”,最終選擇最高票數的分類。
以下階段將幫助我們了解隨機森林演算法的工作原理。
第1步:先從資料集中選擇隨機樣本。
第2步:對於每個樣本,演算法將建立一個決策樹。然後將獲得每個決策樹的預測結果。
第3步:將對這一步中的每個預期結果進行投票。
第4步:最後選擇得票最多的預測結果作為最終的預測結果。
隨機森林方法具有以下優點
- #透過平均或整合不同決策樹的輸出,它解決了過度擬合的問題。
- 對於廣泛的資料項,隨機森林比單一決策樹表現更好。
- 即使缺少大量數據,隨機森林演算法也能保持高精度。
隨機森林的特徵
以下是隨機森林演算法的主要特徵:
- 是目前可用的最準確的演算法。
- 適用於龐大的資料庫。
- 可以處理數以萬計的輸入變量,且不用刪除其中任何一個變數。
- 隨著森林的增長,它會產生泛化誤差的內部無偏估計。
- 即使在大量資料遺失的情況下也能保持其準確性。
- 它包括用於平衡類別人群中不均勻資料集的不準確性的方法。
- 所建立的森林可以在將來保存並用於其他資料。
- 建立原型以顯示變數和分類之間的關係。
- 它計算範例對之間的距離,這對於聚類、偵測異常值或提供引人入勝的資料視圖(按比例)很有用。
- 未標記的資料可用於使用上述功能建立無監督聚類、資料視覺化和異常值識別。
隨機森林有多個決策樹作為基礎學習模型。我們從資料集中隨機執行行採樣和特徵採樣,形成每個模型的樣本資料集。這部分稱為引導程式。
如何使用隨機森林迴歸技術
- #設計一個特定的問題或資料並取得來源以確定所需的資料。
- 確保資料是可存取的格式,否則將其轉換為所需的格式。
- 指定獲得所需資料可能需要的所有明顯異常和缺失資料點。
- 建立機器學習模型。
- 設定想要實現的基準模型
- 訓練資料機器學習模型。
- 使用測試資料提供對模型的洞察
- 現在比較測試資料和模型預測資料的效能指標。
- 如果它不能滿足,可以嘗試相應地改進模型或使用其他資料建模技術。
- 在這個階段,解釋所獲得的數據並相應地報告。
Python實作隨機森林演算法流程
第1步:導入所需的函式庫。
import numpy as np import matplotlib.pyplot as plt import pandas as pd
第2步:匯入並列印資料集
ata=pd.read_csv('Salaries.csv') print(data)
第3步:從資料集中選擇所有行和第1列到x,選擇所有行和第2列作為y
x=df.iloc[:,:-1]#”:」表示將選取所有行,「:-1」表示將忽略最後一列
y=df.iloc[: ,-1:]#”:”表示它將選擇所有行,“-1:”表示它將忽略除最後一列之外的所有列
#“iloc()”函數使我們能夠選擇資料集的特定單元格,也就是說,它幫助我們從資料框或資料集的一組值中選擇屬於特定行或列的值。
第4步:將隨機森林迴歸器擬合到資料集
from sklearn.ensemble import RandomForestRegressor regressor=RandomForestRegressor(n_estimators=100,random_state=0) regressor.fit(x,y)
第5步:預測新結果
Y_pred=regressor.predict(np.array([6.5]).reshape(1,1))
第6步:視覺化結果
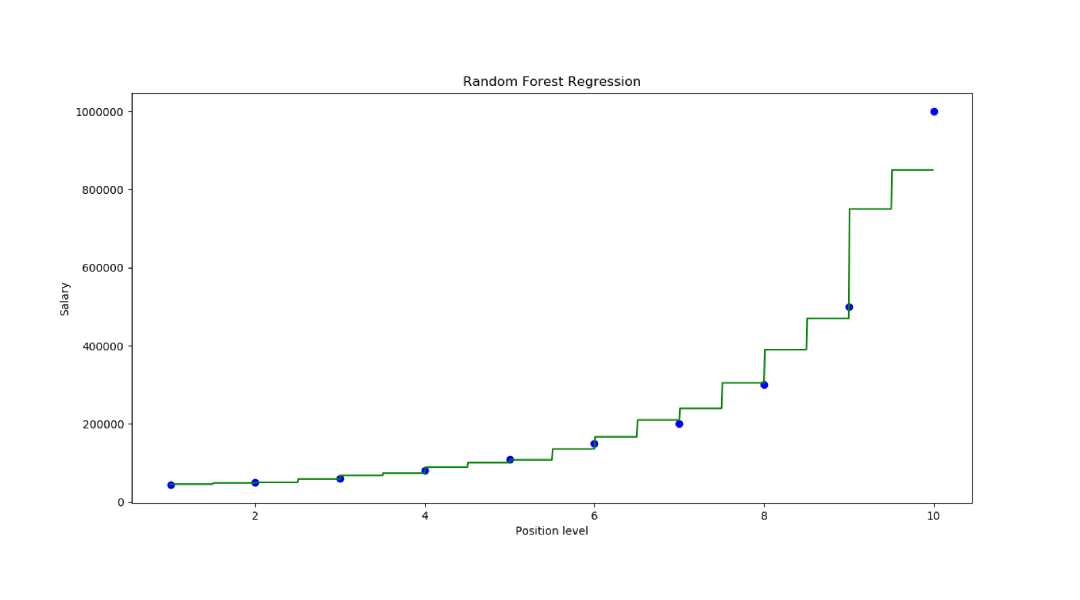
X_grid=np.arrange(min(x),max(x),0.01) X_grid=X_grid.reshape((len(X_grid),1)) plt.scatter(x,y,color='blue') plt.plot(X_grid,regressor.predict(X_grid), color='green') plt.title('Random Forest Regression') plt.xlabel('Position level') plt.ylabel('Salary') plt.show()
以上是隨機森林演算法原理及實際應用的Python範例(附完整程式碼)的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:163.com。如有侵權,請聯絡admin@php.cn刪除