



對抗性學習是一種機器學習技術,透過對模型進行對抗性訓練來提高其穩健性。這種訓練方法的目的是透過故意引入具有挑戰性的樣本,使模型產生不準確或錯誤的預測。透過這種方式,訓練後的模型能夠更好地適應現實世界中資料的變化,從而提高其效能的穩定性。
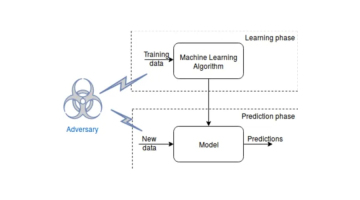
對機器學習模型的對抗性攻擊
對於機器學習模型的攻擊,可以分為兩類:白盒攻擊和黑盒子攻擊。白盒攻擊指的是攻擊者可以存取模型的架構和參數,從而進行攻擊;而黑盒攻擊則是指攻擊者無法存取這些資訊。一些常見的對抗性攻擊方法包括快速梯度符號法(FGSM)、基本迭代法(BIM)和基於雅可比矩陣的顯著性圖攻擊(JSMA)。
為什麼對抗性學習對於提升模型穩健性很重要?
對抗性學習在提高模型穩健性方面具有重要作用。它可以幫助模型更好地泛化,並識別、適應資料結構,從而提高穩健性。此外,對抗性學習也能夠發現模型的弱點,並提供改進模型的指導。因此,對抗性學習對於模型的訓練和最佳化至關重要。
如何將對抗性學習納入機器學習模型?
將對抗性學習納入機器學習模型需要兩個步驟:產生對抗性範例並將這些範例納入訓練過程。
對抗樣本的生成和訓練
產生資訊的方法多種多樣,包括基於梯度的方法、遺傳演算法和強化學習。其中,基於梯度的方法是最常使用的。這種方法涉及計算輸入的損失函數的梯度,並根據梯度的方向來調整訊息,以增加損失。
對抗樣本可以透過對抗訓練和對抗增強的方式納入訓練過程。在訓練中,使用對抗性範例來更新模型參數,同時透過向訓練資料添加對抗性範例來提高模型的穩健性。
增強資料是一種簡單而有效的實踐方法,廣泛用於提升模型效能。其基本想法是將對抗性範例引入訓練數據,然後在增強數據上訓練模型。經過訓練後的模型能夠準確地預測原始範例和對抗範例的類別標籤,從而使其對資料的變化和失真更加穩健。這種方法在實際應用中非常常見。
對抗性學習的應用實例
對抗性學習已應用於各種機器學習任務,包括電腦視覺、語音辨識和自然語言處理。
在電腦視覺中,對於提高影像分類模型的穩健性,對卷積神經網路(CNN)的穩健性進行調整,可提高未見資料的準確性。
對抗性學習在語音辨識中扮演了提升自動語音辨識(ASR)系統穩健性的作用。此方法透過使用對抗性範例來改變輸入語音訊號,這些範例被設計成人類無法察覺但會導致ASR系統錯誤轉錄的方式。研究表明,對抗性訓練可以提高ASR系統對這些對抗性範例的穩健性,從而提高辨識的準確性和可靠性。
在自然語言處理中,對抗性學習已被用於提高情緒分析模型的穩健性。此NLP領域中的對抗性範例旨在以導致模型預測錯誤和不準確的方式操縱輸入文字。對抗性訓練已被證明可以提高情緒分析模型對這些類型的對抗性範例的穩健性,從而提高準確性和穩健性。
以上是深入解析機器學習中的對抗性學習技術的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 商業領袖生成引擎優化指南(GEO)May 03, 2025 am 11:14 AM
商業領袖生成引擎優化指南(GEO)May 03, 2025 am 11:14 AMGoogle正在領導這一轉變。它的“ AI概述”功能已經為10億用戶提供服務,在任何人單擊鏈接之前提供完整的答案。 [^2] 其他球員也正在迅速獲得地面。 Chatgpt,Microsoft Copilot和PE
 該初創公司正在使用AI代理來與惡意廣告和模仿帳戶進行戰鬥May 03, 2025 am 11:13 AM
該初創公司正在使用AI代理來與惡意廣告和模仿帳戶進行戰鬥May 03, 2025 am 11:13 AM2022年,他創立了社會工程防禦初創公司Doppel,以此做到這一點。隨著網絡犯罪分子越來越高級的AI模型來渦輪增壓,Doppel的AI系統幫助企業對其進行了大規模的對抗 - 更快,更快,
 世界模型如何從根本上重塑生成AI和LLM的未來May 03, 2025 am 11:12 AM
世界模型如何從根本上重塑生成AI和LLM的未來May 03, 2025 am 11:12 AM瞧,通過與合適的世界模型進行交互,可以實質上提高生成的AI和LLM。 讓我們來談談。 對創新AI突破的這種分析是我正在進行的《福布斯》列的最新覆蓋範圍的一部分,包括
 2050年五月:我們要慶祝什麼?May 03, 2025 am 11:11 AM
2050年五月:我們要慶祝什麼?May 03, 2025 am 11:11 AM勞動節2050年。全國范圍內的公園充滿了享受傳統燒烤的家庭,而懷舊遊行則穿過城市街道。然而,慶祝活動現在具有像博物館般的品質 - 歷史重演而不是紀念C
 您從未聽說過的DeepFake探測器準確是98%May 03, 2025 am 11:10 AM
您從未聽說過的DeepFake探測器準確是98%May 03, 2025 am 11:10 AM為了幫助解決這一緊急且令人不安的趨勢,在2025年2月的TEM期刊上進行了同行評審的文章,提供了有關該技術深擊目前面對的最清晰,數據驅動的評估之一。 研究員
 量子人才戰爭:隱藏的危機威脅技術的下一個邊界May 03, 2025 am 11:09 AM
量子人才戰爭:隱藏的危機威脅技術的下一個邊界May 03, 2025 am 11:09 AM從大大減少制定新藥所需的時間到創造更綠色的能源,企業將有巨大的機會打破新的地面。 不過,有一個很大的問題:嚴重缺乏技能的人
 原型:這些細菌可以產生電力May 03, 2025 am 11:08 AM
原型:這些細菌可以產生電力May 03, 2025 am 11:08 AM幾年前,科學家發現某些類型的細菌似乎通過發電而不是吸收氧氣而呼吸,但是它們是如何做到的,這是一個謎。一項發表在“雜誌”雜誌上的新研究確定了這種情況的發生方式:Microb
 AI和網絡安全:新政府的100天估算May 03, 2025 am 11:07 AM
AI和網絡安全:新政府的100天估算May 03, 2025 am 11:07 AM在本週的RSAC 2025會議上,Snyk舉辦了一個及時的小組,標題為“前100天:AI,政策和網絡安全如何碰撞”,其中包括全明星陣容:前CISA董事Jen Easterly;妮可·珀洛斯(Nicole Perlroth),前記者和帕特納(Partne)


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

