



簡單線性迴歸是一種用於研究兩個連續變數之間關係的統計方法。其中,一個變數被稱為自變數(x),另一個變數稱為因變數(y)。我們假設這兩個變數之間存在線性關係,並試圖找到一個線性函數,以自變數的特徵來準確預測因變數的反應值(y)。透過擬合一條直線,我們可以得到預測的結果。這個預測模型可以用來理解和預測因變數如何隨著自變數的變化而變化。
為了理解這個概念,我們可以藉助一個薪水資料集,其中包含了每個自變數(經驗年限)對應的因變數(薪水)的值。
薪資資料集
年薪與經驗
1.1 39343.00
1.3 46205.00
1.5 37731.00
2.0 43525.00
2.2 39891.00
2.9 56642.00
3.0 60150.00
3.2 54445.00
3.2 64445.0007#7#7#105#7#510512#7#7#7#7#5.0512#7#。
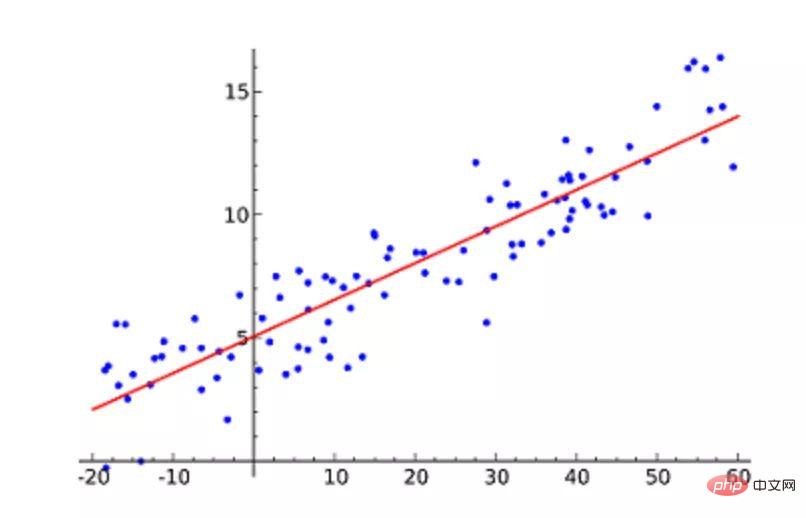
#出於一般目的,我們定義:x作為特徵向量,即x=[x_1,x_2,....,x_n],y作為回應向量,即y=[y_1,y_2,....,y_n]對於n次觀察(在上面的範例中,n=10)。 給定資料集的散佈圖 #現在,我們必須找到一條適合上述散佈圖的線,透過它我們可以預測任何y值或任何x值的反應。 最適合的線稱為迴歸線。 以下R程式碼用於實現簡單線性迴歸
#現在,我們必須找到一條適合上述散佈圖的線,透過它我們可以預測任何y值或任何x值的反應。 最適合的線稱為迴歸線。 以下R程式碼用於實現簡單線性迴歸dataset=read.csv('salary.csv')
install.packages('caTools')
library(caTools)
split=sample.split(dataset$Salary,SplitRatio=0.7)
trainingset=subset(dataset,split==TRUE)
testset=subset(dataset,split==FALSE)
lm.r=lm(formula=Salary~YearsExperience,
data=trainingset)
coef(lm.r)
ypred=predict(lm.r,newdata=testset)
install.packages("ggplot2")
library(ggplot2)
ggplot()+geom_point(aes(x=trainingset$YearsExperience,
y=trainingset$Salary),colour='red')+
geom_line(aes(x=trainingset$YearsExperience,
y=predict(lm.r,newdata=trainingset)),colour='blue')+
ggtitle('Salary vs Experience(Training set)')+
xlab('Years of experience')+
ylab('Salary')
ggplot()+
geom_point(aes(x=testset$YearsExperience,y=testset$Salary),
colour='red')+
geom_line(aes(x=trainingset$YearsExperience,
y=predict(lm.r,newdata=trainingset)),
colour='blue')+
ggtitle('Salary vs Experience(Test set)')+
xlab('Years of experience')+
ylab('Salary')視覺化訓練集結果
以上是用R實作簡單線性迴歸法並解釋其概念的詳細內容。更多資訊請關注PHP中文網其他相關文章!

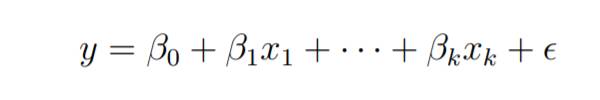 深入解析多元线性回归模型的概念与应用Jan 22, 2024 pm 06:30 PM
深入解析多元线性回归模型的概念与应用Jan 22, 2024 pm 06:30 PM多元线性回归是最常见的线性回归形式,用于描述单个响应变量Y如何与多个预测变量呈现线性关系。可以使用多重回归的应用示例:房子的售价可能受到位置、卧室和浴室数量、建造年份、地块面积等因素的影响。2、孩子的身高取决于母亲的身高、父亲的身高、营养和环境因素。多元线性回归模型参数考虑一个具有k个独立预测变量x1、x2……、xk和一个响应变量y的多元线性回归模型。假设我们对k+1个变量有n个观测值,并且n的变量应该大于k。最小二乘回归的基本目标是将超平面拟合到(k+1)维空间中,以最小化残差平方和。在对模型
 Python中的线性回归模型详解Jun 10, 2023 pm 12:28 PM
Python中的线性回归模型详解Jun 10, 2023 pm 12:28 PMPython中的线性回归模型详解线性回归是一种经典的统计模型和机器学习算法。它被广泛应用于预测和建模的领域,如股票市场预测、天气预测、房价预测等。Python作为一种高效的编程语言,提供了丰富的机器学习库,其中就包括线性回归模型。本文将详细介绍Python中的线性回归模型,包括模型原理、应用场景和代码实现等。线性回归原理线性回归模型是建立在变量之间存在线性关
 吉洪诺夫正则化Jan 23, 2024 am 09:33 AM
吉洪诺夫正则化Jan 23, 2024 am 09:33 AM吉洪诺夫正则化,又称为岭回归或L2正则化,是一种用于线性回归的正则化方法。它通过在模型的目标函数中添加一个L2范数惩罚项来控制模型的复杂度和泛化能力。该惩罚项对模型的权重进行平方和的惩罚,以避免权重过大,从而减轻过拟合问题。这种方法通过在损失函数中引入正则化项,通过调整正则化系数来平衡模型的拟合能力和泛化能力。吉洪诺夫正则化在实际应用中具有广泛的应用,可以有效地改善模型的性能和稳定性。在正则化之前,线性回归的目标函数可以表示为:J(w)=\frac{1}{2m}\sum_{i=1}^{m}(h_
 机器学习必知必会十大算法!Apr 12, 2023 am 09:34 AM
机器学习必知必会十大算法!Apr 12, 2023 am 09:34 AM1.线性回归线性回归(Linear Regression)可能是最流行的机器学习算法。线性回归就是要找一条直线,并且让这条直线尽可能地拟合散点图中的数据点。它试图通过将直线方程与该数据拟合来表示自变量(x 值)和数值结果(y 值)。然后就可以用这条线来预测未来的值!这种算法最常用的技术是最小二乘法(Least of squares)。这个方法计算出最佳拟合线,以使得与直线上每个数据点的垂直距离最小。总距离是所有数据点的垂直距离(绿线)的平方和。其思想是通过最小化这个平方误差或距离来拟合模型。例如
 Logistic回归中OR值的定义、意义和计算详解Jan 23, 2024 pm 12:48 PM
Logistic回归中OR值的定义、意义和计算详解Jan 23, 2024 pm 12:48 PMLogistic回归是一种用于分类问题的线性模型,主要用于预测二分类问题中的概率值。它通过使用sigmoid函数将线性预测值转换为概率值,并根据阈值进行分类决策。在Logistic回归中,OR值是一个重要的指标,用于衡量模型中不同变量对结果的影响程度。OR值代表了自变量的单位变化对因变量发生的概率的倍数变化。通过计算OR值,我们可以判断某个变量对模型的贡献程度。OR值的计算方法是取指数函数(exp)的自然对数(ln)的系数,即OR=exp(β),其中β是Logistic回归模型中自变量的系数。具
 线性与非线性分析的多项式回归性质Jan 22, 2024 pm 03:03 PM
线性与非线性分析的多项式回归性质Jan 22, 2024 pm 03:03 PM多项式回归是一种适用于非线性数据关系的回归分析方法。与简单线性回归模型只能拟合直线关系不同,多项式回归模型可以更准确地拟合复杂的曲线关系。它通过引入多项式特征,将变量的高阶项加入模型,从而更好地适应数据的非线性变化。这种方法可以提高模型的灵活性和拟合度,从而更准确地预测和解释数据。多项式回归模型的基本形式为:y=β0+β1x+β2x^2+…+βn*x^n+ε在这个模型中,y是我们要预测的因变量,x是自变量。β0~βn是模型的系数,它们决定了自变量对因变量的影响程度。ε表示模型的误差项,它是由无法
 广义线性模型和普通线性模型的区别Jan 23, 2024 pm 01:45 PM
广义线性模型和普通线性模型的区别Jan 23, 2024 pm 01:45 PM广义线性模型和一般线性模型是统计学中常用的回归分析方法。尽管这两个术语相似,但它们在某些方面有区别。广义线性模型允许因变量服从非正态分布,通过链接函数将预测变量与因变量联系起来。而一般线性模型假设因变量服从正态分布,使用线性关系进行建模。因此,广义线性模型更加灵活,适用范围更广。1.定义和范围一般线性模型是一种回归分析方法,适用于因变量与自变量之间存在线性关系的情况。它假设因变量服从正态分布。广义线性模型是一种适用于因变量不一定服从正态分布的回归分析方法。它通过引入链接函数和分布族,能够描述因变
 逻辑回归分析模型Jan 22, 2024 pm 04:09 PM
逻辑回归分析模型Jan 22, 2024 pm 04:09 PMLogistic回归模型是用于预测二元变量概率的分类模型。它是基于线性回归模型的,通过将线性回归的输出转换为预测概率来实现分类任务。Logistic回归模型在预测二元变量概率方面发挥着重要作用。它广泛应用于各种分类问题,如预测股票市场的涨跌、信用卡持有者是否违约等。此外,Logistic回归模型还可以用于特征选择,即选取对预测结果有显著影响的特征。另外,通过绘制ROC曲线来评估模型性能,Logistic回归模型也可以用于可视化。通过这种方式,我们可以直观地了解模型的预测能力。Logistic回归


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Dreamweaver CS6
視覺化網頁開發工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

記事本++7.3.1
好用且免費的程式碼編輯器

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

