




決策樹演算法屬於監督學習演算法的範疇,適用於連續和分類輸出變量,通常會被用來解決分類和迴歸問題。
決策樹是一種類似流程圖的樹狀結構,其中每個內部節點表示對屬性的測試,每個分支表示測試的結果,每個節點都對應一個類別標籤。
決策樹演算法想法
開始,將整個訓練集視為根。
對於資訊增益,假設屬性是分類的,對於基尼指數,假設屬性是連續的。
在屬性值的基礎上,記錄被遞歸地分佈。
使用統計方法將屬性排序為根節點。
找到最佳屬性並將其放在樹的根節點上。
現在,將資料集的訓練集拆分為子集。在製作子集時,請確保訓練資料集的每個子集都應具有相同的屬性值。
透過在每個子集上重複1和2來找出所有分支中的葉節點。
Python實作決策樹演算法
需要經歷建置與營運兩個階段:
#建置階段,預處理資料集。使用Python sklearn套件從訓練和測試中拆分資料集。訓練分類器。
營運階段,作出預測。計算準確度。
資料導入,為了導入和操作數據,我們使用了python中提供的pandas包。
在這裡,我們使用的URL直接從UCI網站取得資料集,無需下載資料集。當您嘗試在系統上執行此程式碼時,請確保系統應具有活動的網路連線。
由於資料集由“,”分隔,所以我們必須將sep參數的值作為傳遞。
另一件事是注意資料集不包含標頭,因此我們將Header參數的值作為none傳遞。如果我們不傳遞header參數,那麼它將把資料集的第一行視為header。
資料切片,在訓練模型之前,我們必須將資料集拆分為訓練和測試資料集。
為了分割資料集進行訓練和測試,我們使用了sklearn模組train_test_split
首先,我們必須將目標變數與資料集中的屬性分開。
X=balance_data.values[:,1:5] Y=balance_data.values[:,0]
以上是分隔資料集的程式碼行。變數X包含屬性,而變數Y包含資料集的目標變數。
下一步是拆分資料集以用於訓練和測試目的。
X_train,X_test,y_train,y_test=train_test_split( X,Y,test_size=0.3,random_state=100)
上一行拆分資料集以進行訓練和測試。由於我們在訓練和測試之間以70:30的比例拆分資料集,因此我們將test_size參數的值傳遞為0.3。
random_state變數是用於隨機取樣的偽隨機數產生器狀態。
以上是Python實作決策樹演算法的原理與實作方式的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 深入剖析灰狼优化算法(GWO)及其优势与弱点Jan 19, 2024 pm 07:48 PM
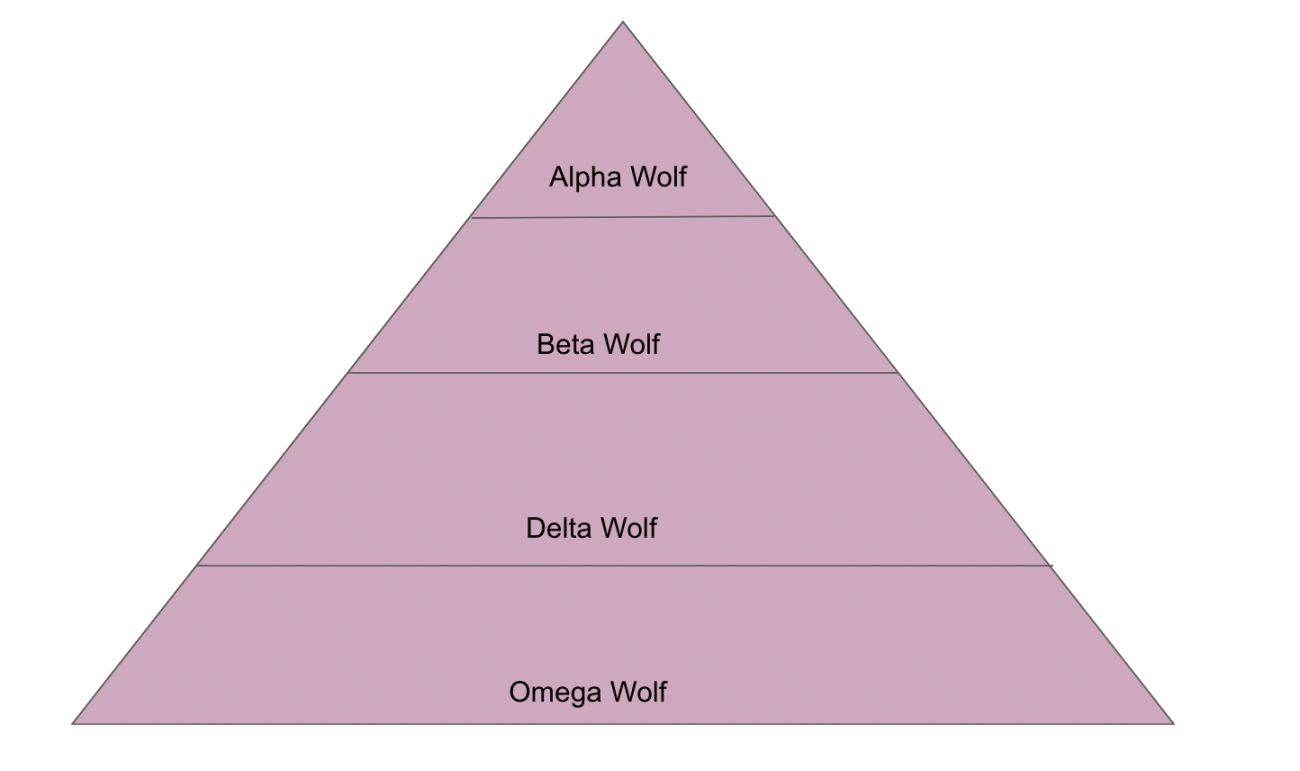
深入剖析灰狼优化算法(GWO)及其优势与弱点Jan 19, 2024 pm 07:48 PM灰狼优化算法(GWO)是一种基于种群的元启发式算法,模拟自然界中灰狼的领导层级和狩猎机制。灰狼算法灵感1、灰狼被认为是顶级掠食者,处于食物链的顶端。2、灰狼喜欢群居(群居),每个狼群平均有5-12只狼。3、灰狼具有非常严格的社会支配等级,如下图:Alpha狼:Alpha狼在整个灰狼群中占据优势地位,拥有统领整个灰狼群的权利。在算法应用中,Alpha狼是最佳解决方案之一,由优化算法产生的最优解。Beta狼:Beta狼定期向Alpha狼报告,并帮助Alpha狼做出最佳决策。在算法应用中,Beta狼可
 解析麻雀搜索算法(SSA)的原理、模型和构成Jan 19, 2024 pm 10:27 PM
解析麻雀搜索算法(SSA)的原理、模型和构成Jan 19, 2024 pm 10:27 PM麻雀搜索算法(SSA)是基于麻雀反捕食和觅食行为的元启发式优化算法。麻雀的觅食行为可分为两种主要类型:生产者和拾荒者。生产者主动寻找食物,而拾荒者则争夺生产者的食物。麻雀搜索算法(SSA)原理在麻雀搜索算法(SSA)中,每只麻雀都密切关注着邻居的行为。通过采用不同的觅食策略,个体能够有效地利用保留的能量来追求更多的食物。此外,鸟类在搜索空间中更容易受到捕食者的攻击,因此它们需要寻找更安全的位置。群体中心的鸟类可以通过靠近邻居来最大限度地减少自身的危险范围。当一只鸟发现捕食者时,会发出警报声,以便
 探究嵌套采样算法的基本原理和实施流程Jan 22, 2024 pm 09:51 PM
探究嵌套采样算法的基本原理和实施流程Jan 22, 2024 pm 09:51 PM嵌套采样算法是一种高效的贝叶斯统计推断算法,用于计算复杂概率分布下的积分或求和。它通过将参数空间分解为多个体积相等的超立方体,并逐步迭代地将其中一个最小体积的超立方体“推出”,然后用随机样本填充该超立方体,以更好地估计概率分布的积分值。通过不断迭代,嵌套采样算法可以得到高精度的积分值和参数空间的边界,从而可应用于模型比较、参数估计和模型选择等统计学问题。该算法的核心思想是将复杂的积分问题转化为一系列简单的积分问题,通过逐步缩小参数空间的体积,逼近真实的积分值。每个迭代步骤都通过随机采样从参数空间
 信息增益在id3算法中的作用是什么Jan 23, 2024 pm 11:27 PM
信息增益在id3算法中的作用是什么Jan 23, 2024 pm 11:27 PMID3算法是决策树学习中的基本算法之一。它通过计算每个特征的信息增益来选择最佳的分裂点,以生成一棵决策树。信息增益是ID3算法中的重要概念,用于衡量特征对分类任务的贡献。本文将详细介绍信息增益的概念、计算方法以及在ID3算法中的应用。一、信息熵的概念信息熵是信息论中的概念,衡量随机变量的不确定性。对于离散型随机变量X,其信息熵定义如下:H(X)=-\sum_{i=1}^{n}p(x_i)log_2p(x_i)其中,n代表随机变量X可能的取值个数,而p(x_i)表示随机变量X取值为x_i的概率。信
 鲸鱼优化算法 (WOA) 的数值优化原理和分析Jan 19, 2024 pm 07:27 PM
鲸鱼优化算法 (WOA) 的数值优化原理和分析Jan 19, 2024 pm 07:27 PM鲸鱼优化算法(WOA)是一种基于自然启发的元启发式优化算法,模拟了座头鲸的狩猎行为,用于数值问题的优化。鲸鱼优化算法(WOA)以一组随机解作为起点,通过每次迭代中搜索代理的位置更新,根据随机选择的搜索代理或迄今为止的最佳解决方案来进行优化。鲸鱼优化算法灵感鲸鱼优化算法的灵感源自座头鲸的狩猎行为。座头鲸喜欢的食物位于海面附近,如磷虾和鱼群。因此,座头鲸在狩猎时通过自下而上螺旋吐泡泡的方式,将食物聚集在一起形成泡泡网。在“向上螺旋”机动中,座头鲸下潜约12m,然后开始在猎物周围形成螺旋形气泡并向上游
 尺度转换不变特征(SIFT)算法Jan 22, 2024 pm 05:09 PM
尺度转换不变特征(SIFT)算法Jan 22, 2024 pm 05:09 PM尺度不变特征变换(SIFT)算法是一种用于图像处理和计算机视觉领域的特征提取算法。该算法于1999年提出,旨在提高计算机视觉系统中的物体识别和匹配性能。SIFT算法具有鲁棒性和准确性,被广泛应用于图像识别、三维重建、目标检测、视频跟踪等领域。它通过在多个尺度空间中检测关键点,并提取关键点周围的局部特征描述符来实现尺度不变性。SIFT算法的主要步骤包括尺度空间的构建、关键点检测、关键点定位、方向分配和特征描述符生成。通过这些步骤,SIFT算法能够提取出具有鲁棒性和独特性的特征,从而实现对图像的高效
 Wu-Manber算法简介及Python实现说明Jan 23, 2024 pm 07:03 PM
Wu-Manber算法简介及Python实现说明Jan 23, 2024 pm 07:03 PMWu-Manber算法是一种字符串匹配算法,用于高效地搜索字符串。它是一种混合算法,结合了Boyer-Moore和Knuth-Morris-Pratt算法的优势,可提供快速准确的模式匹配。Wu-Manber算法步骤1.创建一个哈希表,将模式的每个可能子字符串映射到该子字符串出现的模式位置。2.该哈希表用于快速识别文本中模式的潜在起始位置。3.遍历文本并将每个字符与模式中的相应字符进行比较。4.如果字符匹配,则可以移动到下一个字符并继续比较。5.如果字符不匹配,可以使用哈希表来确定在模式的下一个潜
 详解贝尔曼福特算法并用Python实现Jan 22, 2024 pm 07:39 PM
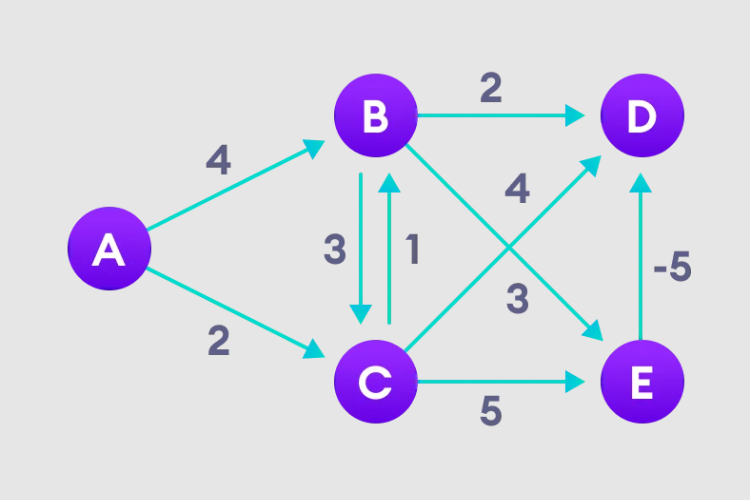
详解贝尔曼福特算法并用Python实现Jan 22, 2024 pm 07:39 PM贝尔曼福特算法(BellmanFord)可以找到从目标节点到加权图其他节点的最短路径。这一点和Dijkstra算法很相似,贝尔曼福特算法可以处理负权重的图,从实现来看也相对简单。贝尔曼福特算法原理详解贝尔曼福特算法通过高估从起始顶点到所有其他顶点的路径长度,迭代寻找比高估路径更短的新路径。因为我们要记录每个节点的路径距离,可以将其存储在大小为n的数组中,n也代表了节点的数量。实例图1、选择起始节点,并无限指定给其他所有顶点,记录路径值。2、访问每条边,并进行松弛操作,不断更新最短路径。3、我们需


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

SublimeText3 Linux新版
SublimeText3 Linux最新版

