
螞蟻集團發布新演算法,可加快大型模型推理速度2-6倍

- 王林轉載
- 2024-01-17 21:33:05951瀏覽
近日,螞蟻集團開源了一套新演算法,可幫助大模型在推理時,提速2至6倍,引起業界關注。
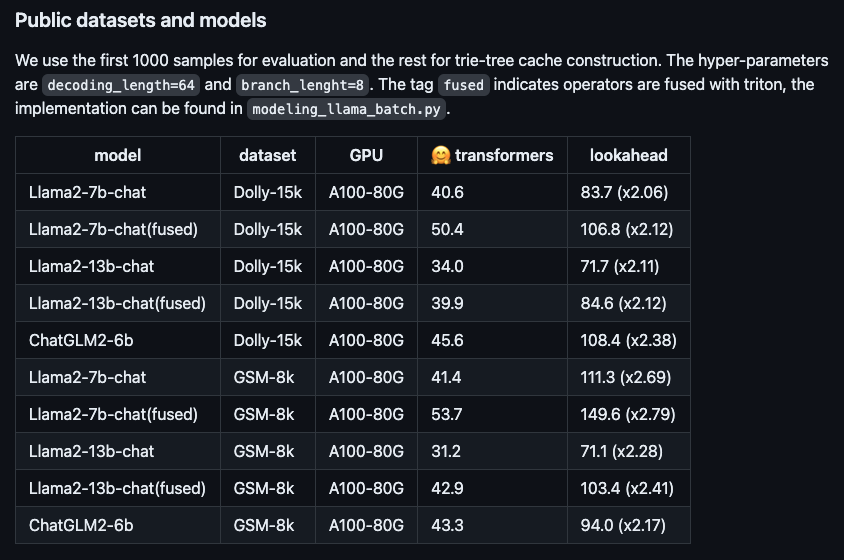
圖:新演算法在不同開源大模型上的提速表現。
這套新演算法名為Lookahead推理加速框架,能做到效果無損,即插即用,演算法已在螞蟻大量場景進行了落地,大幅降低了推理耗時。
以Llama2-7B-chat模型和Dolly資料集為例,我們進行了實測,並發現token生成速度從48.2個/秒提升到112.9個/秒,提速了2.34倍。在螞蟻內部的RAG(檢索增強生成)資料集上,百靈大模型AntGLM 10B版本的加速比達到了5.36。同時,顯存增加和記憶體消耗幾乎可以忽略不計。
目前的大型模型通常是基於自迴歸解碼,每次只產生一個token。這種方式不僅浪費了GPU的平行處理能力,也導致使用者體驗延遲過高,影響了流暢度。為了改善這個問題,可以嘗試採用平行解碼方式,同時產生多個token,以提高效率和使用者體驗。
舉個例子,原來的token產生過程可以比喻為早期中文輸入法的方式,使用者需要一個字一個字地敲擊鍵盤來輸入文字。然而,採用了螞蟻的加速演算法後,token生成的過程就像是現代聯想輸入法,可以透過聯想功能直接跳出整句話。這樣的改進大大提高了輸入速度和效率。
業內先前已經湧現了一些最佳化演算法,主要專注於產生更優質的草稿(即猜測生成token序列)的方法。然而,經過實務驗證,一旦草稿的長度超過30個token,端到端推理的效率就無法再進一步提高。很明顯,這個長度並沒有充分發揮GPU的運算能力。
為了進一步提升硬體效能,螞蟻Lookahead推理加速演算法採用了多分支的策略。這意味著草稿序列不再只有一條分支,而是包含多個並行的分支,這些分支可以同時進行驗證。這樣一來,在保持前向過程的耗時基本不變的情況下,可以增加一次前向過程產生的token個數。
螞蟻Lookahead推理加速演算法透過利用trie樹儲存和檢索token序列,以及合併多條草稿中相同的父節點,進一步提高了計算效率。為了提高易用性,演算法的trie樹構建不依賴額外的草稿模型,而是只利用推理過程中的prompt和產生的回答進行動態構建,從而降低了用戶的存取成本。
此演算法現已在GitHub上開源(https://www.php.cn/link/51200d29d1fc15f5a71c1dab4bb54f7c),相關論文公佈在ARXIV(https://www .php.cn/link/24a29a235c0678859695b10896513b3d)。
公開資訊顯示,螞蟻集團基於豐富的業務場景需求,在人工智慧方向持續投入,佈局了包括大模型、知識圖譜、運籌優化、圖學習、可信AI等技術領域。
以上是螞蟻集團發布新演算法,可加快大型模型推理速度2-6倍的詳細內容。更多資訊請關注PHP中文網其他相關文章!