為了不改變原意而重寫內容,需要將語言重寫為中文,不需要出現原句
#本網站的編輯部
PowerInfer 的出現使得在消費級硬體上運行AI 變得更加高效
上海交大團隊,剛推出超強CPU/GPU LLM 高速推理引擎PowerInfer。 
#專案位址:https://github.com/SJTU-IPADS/PowerInfer
#論文網址:https://ipads.se.sjtu.edu.cn/_media /publications/powerinfer-20231219.pdf在運行 Falcon (ReLU)-40B-FP16 的單一 RTX 4090 (24G) 上,PowerInfer 對比 llama.cpp 實現了 11 倍加速! 
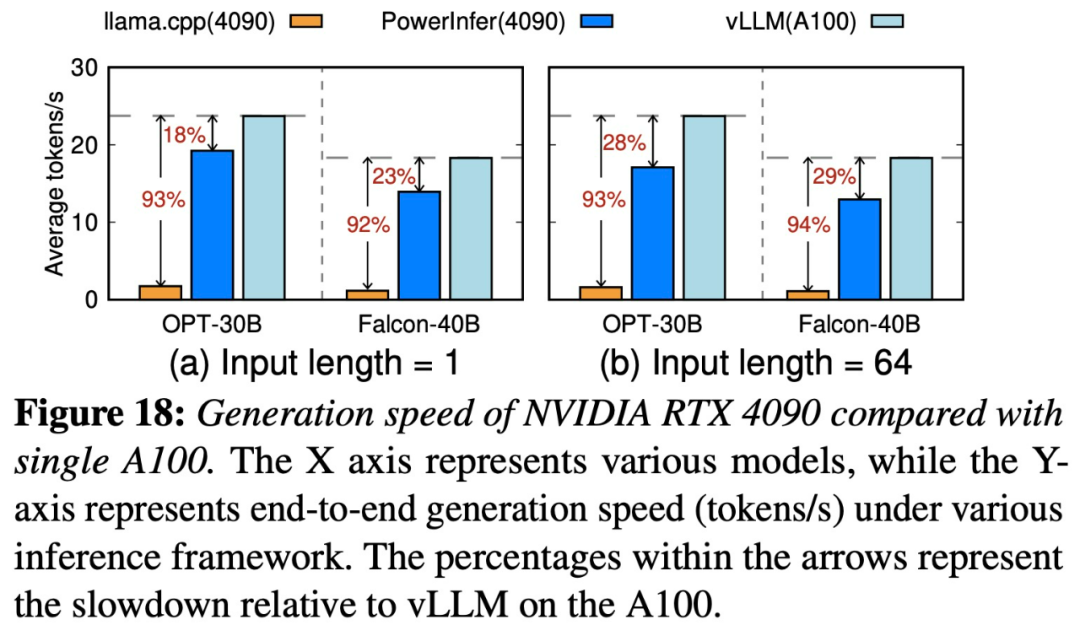
#PowerInfer 和llama.cpp 都在相同的硬體上運行,並充分利用了RTX 4090 上的VRAM。 在單一NVIDIA RTX 4090 GPU 上的各種LLM 中,PowerInfer 的平均token 產生率為13.20 個token / 秒,峰值為29.08 個token /秒,僅比頂級伺服器等級A100 GPU 低18%。 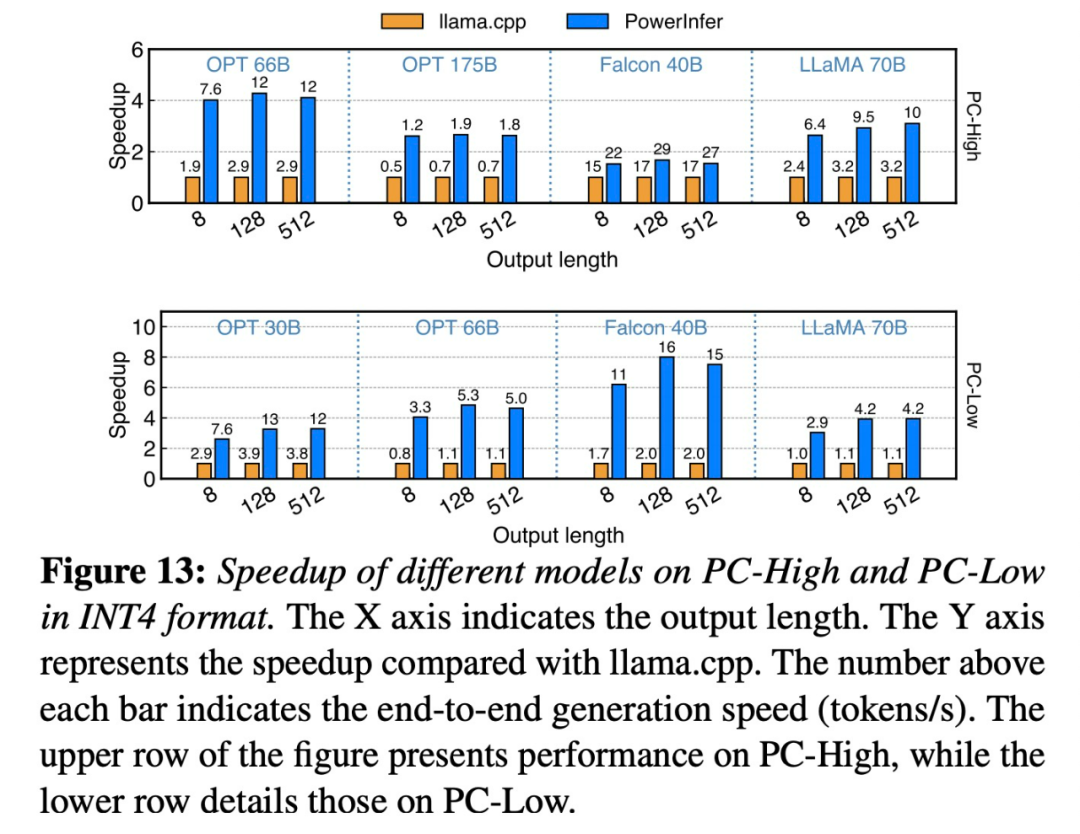
#
具体来说,PowerInfer 是一个用于本地部署 LLM 的高速推理引擎。它利用 LLM 推理中的高局部性来设计 GPU-CPU 混合推理引擎。其中热激活(hot-activated)神经元被预加载到 GPU 上以便快速访问,而冷激活(cold-activated)神经元(大部分)则在 CPU 上计算。这种方法显著减少了 GPU 内存需求和 CPU-GPU 数据传输。PowerInfer 可以在配备单个消费级 GPU 的个人计算机 (PC) 上高速运行大型语言模型 (LLM) 。现在用户可以将 PowerInfer 与 Llama 2 和 Faclon 40B 结合使用,即将支持 Mistral-7B。PowerInfer 设计的关键是利用 LLM 推理中固有的高度局部性,其特征是神经元激活中的幂律分布。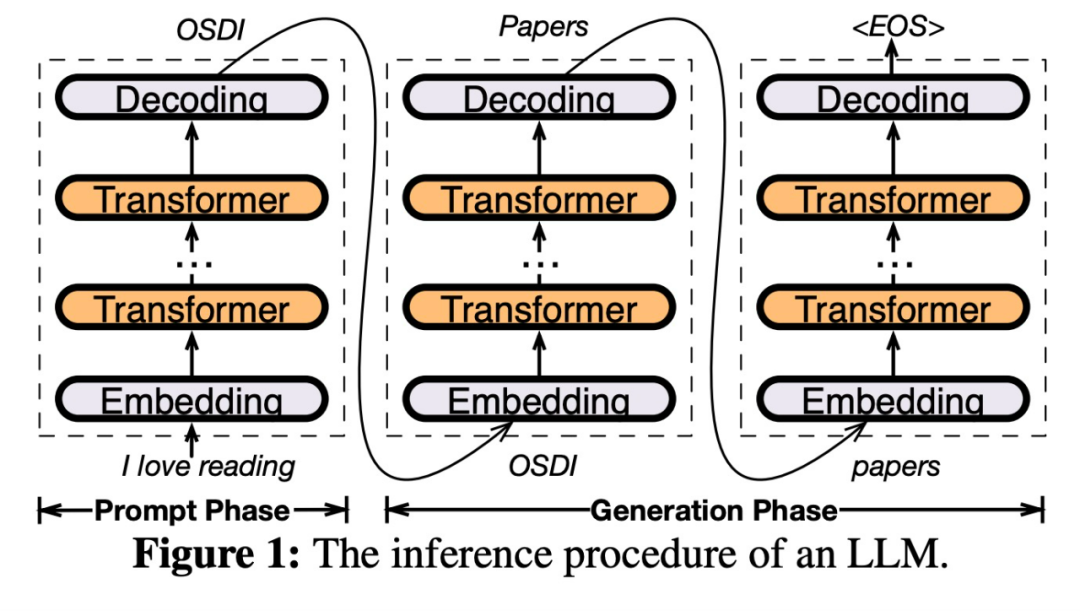
下图 7 展示了 PowerInfer 的架构概述,包括离线和在线组件。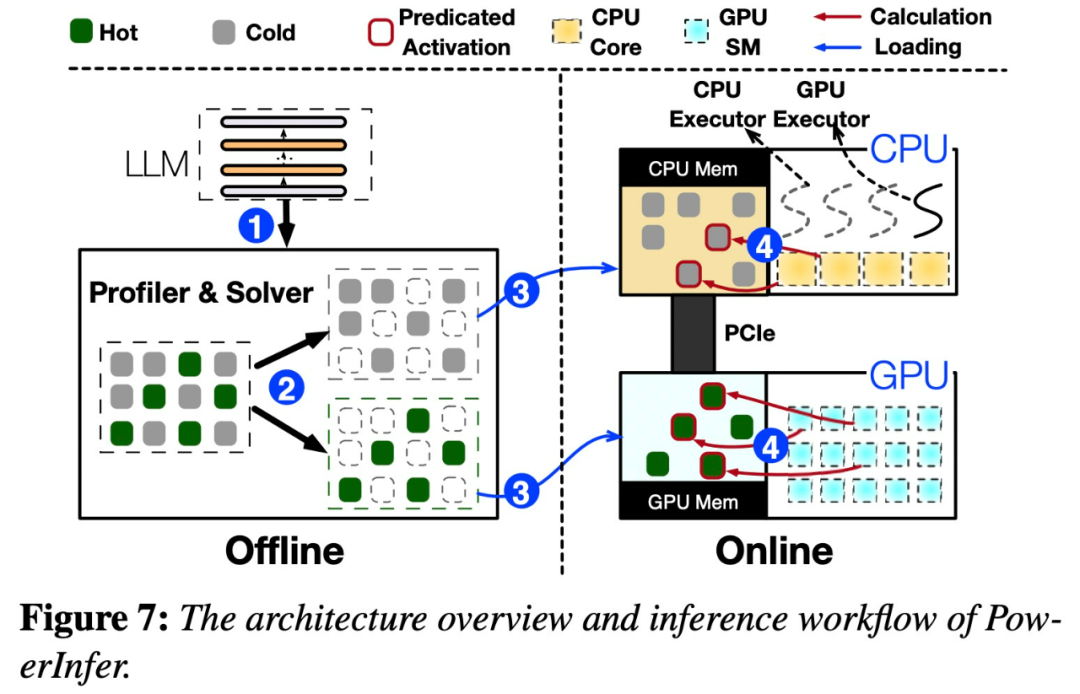
这种分布表明,一小部分神经元(称为热神经元)跨输入一致激活,而大多数冷神经元则根据特定输入而变化。PowerInfer 利用这种机制设计了 GPU-CPU 混合推理引擎。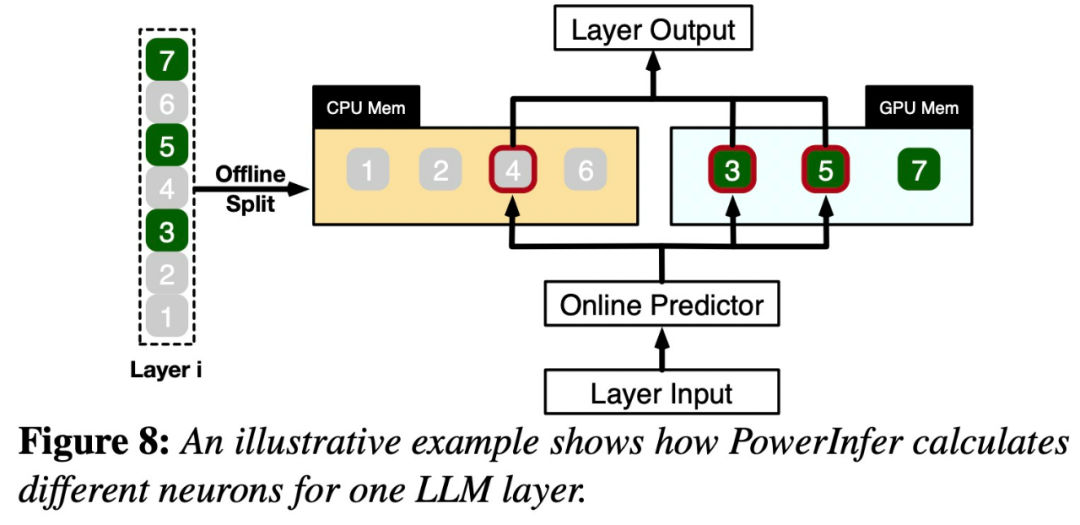
PowerInfer 进一步集成了自适应预测器和神经元感知稀疏算子,优化了神经元激活和计算稀疏性的效率。看到这项研究后,网友激动的表示:单卡 4090 跑 175B 大模型不再是梦。
以上是上交大發布推理引擎PowerInfer,其token生成速率僅比A100低18%,或將取代4090成為A100的替代品的詳細內容。更多資訊請關注PHP中文網其他相關文章!

