
谷歌發布 BIG-Bench Mistake 資料集以幫助 AI 語言模型提升自我糾錯能力

- 王林轉載
- 2024-01-16 16:39:131398瀏覽

Google研究院使用自家BIG-Bench基準測試建立了「BIG-Bench Mistake」資料集,並對市場上流行的語言模型進行出錯機率和糾錯能力的評估研究。這項措施旨在提高語言模型的品質和準確性,為智慧搜尋和自然語言處理領域的應用提供更好的支援。
Google研究人員表示,他們創建了一個名為「BIG-Bench Mistake」的專用資料集,用於評估大語言模型的出錯機率和自我糾錯能力。這個資料集的目的是為了填補過去缺乏評估這些能力的資料集的空白。
研究人員使用 PaLM 語言模型在 BIG-Bench 基準測試任務中執行了 5 項任務。隨後,他們修改了產生的「思維鏈(Chain-of-Thought)」軌跡,並添加了「邏輯錯誤」部分,並再次使用模型判斷思維鏈軌跡中的錯誤。
為了提高資料集的準確性,Google研究人員反覆進行了上述過程,並形成了一個專用基準資料集,名為“BIG-Bench Mistake”,其中包含了255個邏輯錯誤。
研究人員指出,「BIG-Bench Mistake」資料集中的邏輯錯誤非常明顯,因此可以作為一個很好的測試標準,幫助語言模型從簡單的邏輯錯誤開始練習,逐步提高識別錯誤的能力。
研究人員利用該資料集對市面上模型進行測試,發現雖然絕大多數語言模型可以識別在推理過程中出現的邏輯錯誤並進行自我修正,但這個過程「並不夠理想”,通常需要人工幹預來修正模型輸出的內容。
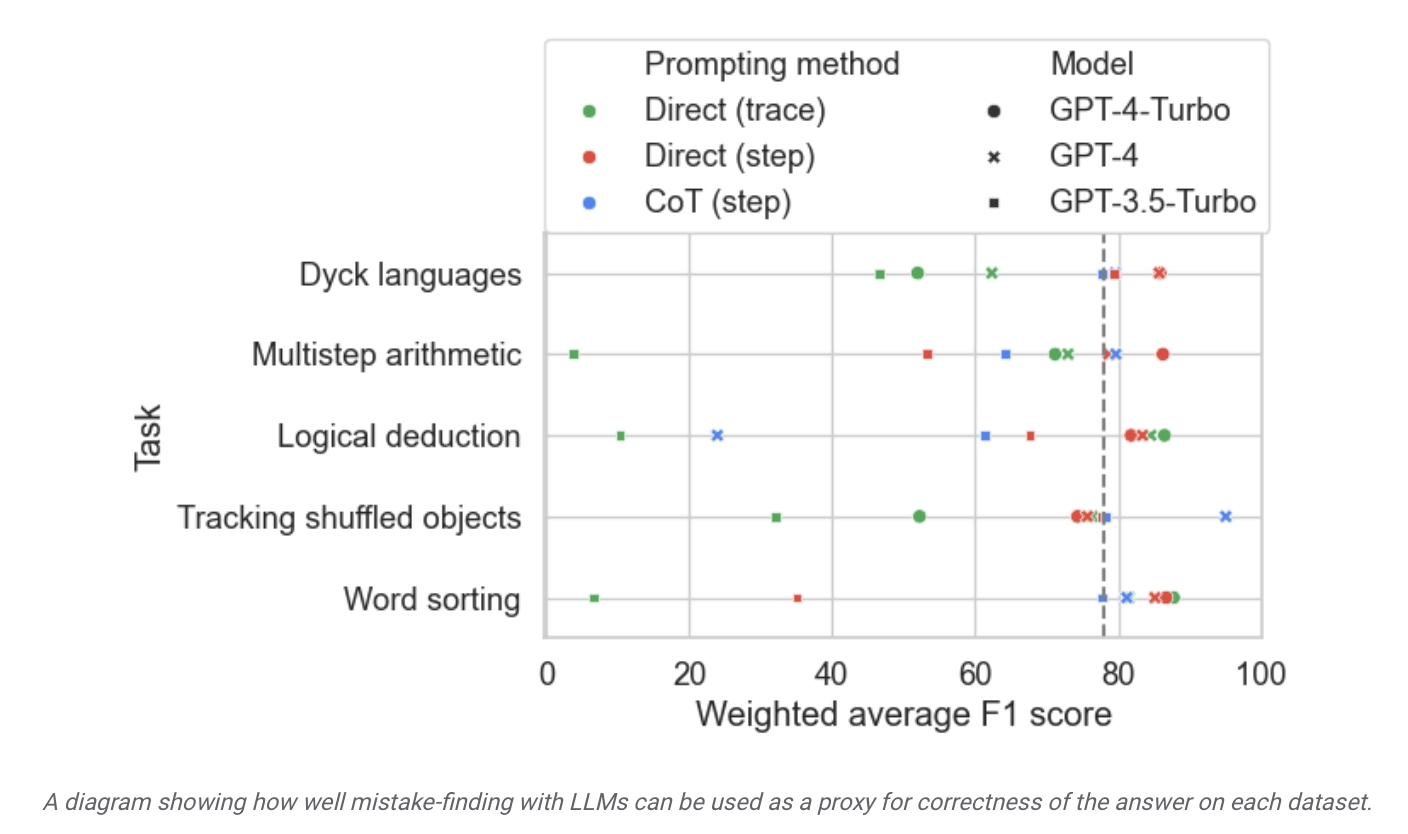
▲ 圖源Google研究院新聞稿
本站從報告中發現,Google聲稱「目前最先進的大語言模型」自我糾錯能力也相對有限,在相關測驗結果中成績發揮最好的模型,也只找出了52.9% 的邏輯錯誤。

Google研究人員同時聲稱,這一BIG-Bench Mistake 資料集有利於改善模型自我糾錯能力,經過相關測試任務微調後的模型,「即使是小型模型表現也通常比零樣本提示的大模型更好」。
據此,Google認為在模型糾錯方面,可以使用專有小型模型“監督”大型模型,相對於讓大語言模型學會“糾正自我錯誤”,部署專用於監督大模型的小型專用模型有利於改善效率、降低相關 AI 部署成本,並更方便微調。
以上是谷歌發布 BIG-Bench Mistake 資料集以幫助 AI 語言模型提升自我糾錯能力的詳細內容。更多資訊請關注PHP中文網其他相關文章!