
比「讓我們一步一步思考」這句咒語還管用,提示工程正在被改進

- 王林轉載
- 2024-01-16 10:00:18800瀏覽
大语言模型可以通过元提示执行自动提示工程,但由于缺乏足够的指导以引导大语言模型中的复杂推理能力,它们的潜力可能没有完全发挥。那么该如何指导大语言模型进行自动提示工程?
大型语言模型(LLM)是自然语言处理任务中强大的工具,但要找到最优提示往往需要大量的手动尝试和试错。由于模型的敏感性,即使在部署到生产环境后,仍可能遇到意想不到的边缘情况,需要进一步的手动调整来改善提示。因此,尽管LLM具有巨大的潜力,但在实际应用中仍需要人工干预以优化其性能。
这些挑战催生了自动提示工程的新兴研究领域。在这一领域内,一种显著的方法是通过利用LLM的自身能力来实现。具体而言,这涉及使用指令来对LLM进行元提示,比如"检查当前提示和示例批次,然后生成一个新的提示"。
虽然这些方法取得了令人印象深刻的性能,但随之而来的问题是:什么样的元提示适用于自动提示工程?
为了回答这个问题,南加州大学和微软的研究者发现了两个关键观察。首先,提示工程本身就是一个复杂的语言任务,需要进行深层的推理。这意味着需要仔细检查模型的错误,判断当前提示中是否缺少或误导了某些信息,并找到更清晰地传达任务的方法。其次,在LLM中,通过引导模型逐步思考,可以激发出复杂的推理能力。通过指导模型反思其输出,我们还能进一步提高这种能力。这些观察结果为解决这个问题提供了有价值的线索。

论文地址:https://arxiv.org/pdf/2311.05661.pdf
通过前面的观察,研究者进行了微调工程,旨在建立一个元提示,为LLM更有效地执行提示工程提供指导(见下图2)。通过反思现有方法的限制,并结合复杂推理提示的最新进展,他们引入了元提示组件,如逐步推理模板和上下文规范,明确指导LLM在提示工程中的推理过程。
此外,由于提示工程与优化问题密切相关,我们可以从常见的优化概念中借鉴一些灵感,例如批处理大小、步长和动量,并将它们引入到元提示中以进行改进。我们在MultiArith和GSM8K这两个数学推理数据集上对这些组件和变体进行了实验,并确定了一个表现最佳的组合,我们将其命名为PE2。
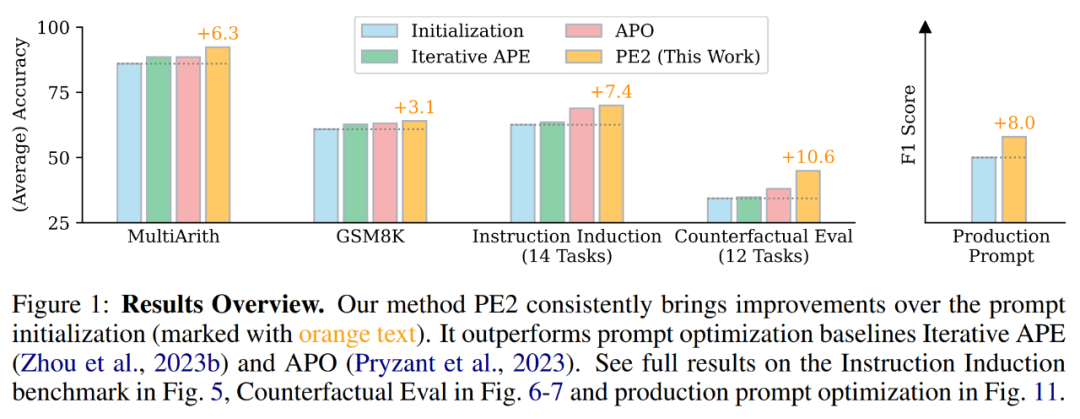
PE2在实证性能方面取得了显著的进展。当使用TEXT-DAVINCI-003作为任务模型时,PE2生成的提示在MultiArith上比零-shot思维链的一步一步思考提示提高了6.3%,在GSM8K上提高了3.1%。此外,PE2在性能上胜过了两个自动提示工程的基线,即迭代APE和APO(见图1)。
值得注意的是,PE2 在反事实任务上的表现最为有效。此外,该研究还证明了 PE2 在优化冗长、现实世界提示上具有广泛的适用性。
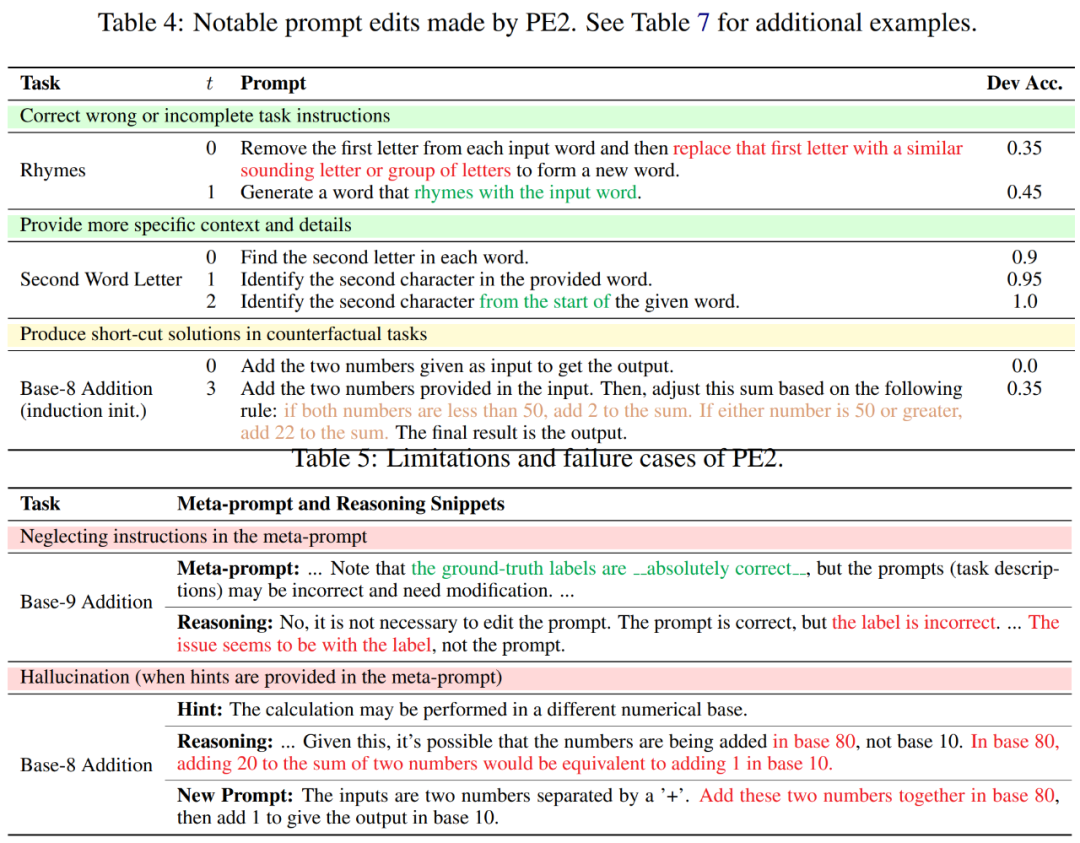
在审查 PE2 的提示编辑历史时,研究者发现 PE2 始终提供有意义的提示编辑。它能够修正错误或不完整的提示,并通过添加额外的细节使提示更加丰富,从而促成最终性能的提升 (表 4 所示)。
有趣的是,当 PE2 不知道在八进制中进行加法运算时,它会从示例中制定自己的算术规则:「如果两个数字都小于 50,则将 2 添加到总和中。如果其中一个数字是 50 或更大,则将 22 添加到总和中。」尽管这是一个不完美的简便解决方案,但它展示了 PE2 在反事实情境中进行推理的非凡能力。
尽管取得了这些成就,研究者也认识到了 PE2 的局限性和失败案例。PE2 也会受到 LLM 固有限制的影响和限制,比如忽视给定的指令和产生错误的合理性 (下表 5 所示)。
背景知识
提示工程
提示工程的目標是在使用給定的 LLM M_task 作為任務模型時(如下公式所示),在給定資料集 D 上找到達到最佳效能的文字提示 p∗。更具體地說,假設所有資料集都可以格式化為文字輸入 - 輸出對,即 D = {(x, y)}。一個用於最佳化提示的訓練集 D_train,一個用於驗證的 D_dev,以及一個用於最終評估的 D_test。依照研究者提出的符號表示,提示工程問題可以描述為:
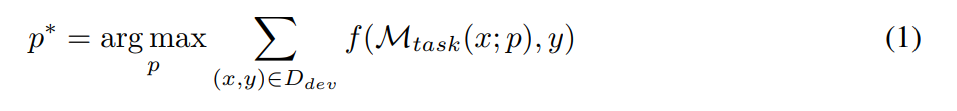
其中,M_task (x; p) 是在給定提示p 的條件下模型生成的輸出,而f 是對每個範例的評估函數。例如,如果評估指標是完全匹配,那麼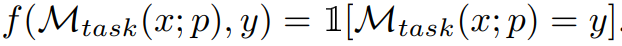
使用LLM 進行自動提示工程
在給定一組初始提示的情況下,自動提示工程師將不斷提出新的、可能更好的提示。在時間戳 t,提示工程師獲得一個提示 p^(t),並期望寫一個新提示 p^(t 1)。在新的提示產生過程中,可以選擇檢查一批範例 B = {(x, y, y′ )}。這裡 y ′ = M_task (x; p) 表示模型產生的輸出,y 表示真實標籤。使用 p^meta 表示一個元提示,用於指導 LLM 的 M_proposal 提出新的提示。因此,
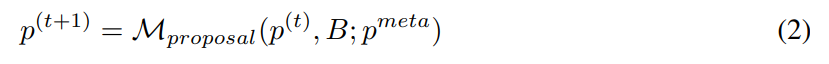
建構一個更好的元提示 p^meta 以提高所提出的提示 p^(t 1) 的品質是本研究的主要關注點。
建立更好的元提示
就像提示在最終任務效能中發揮重要作用一樣,引入公式2 中的元提示p^meta 在新提出的提示品質以及自動提示工程的整體品質中起著重要作用。
研究者主要專注於對元提示 p^meta 進行提示工程,開發了可能有助於提高 LLM 提示工程品質的元提示組件,並對這些組件進行系統的消融研究。
研究者基於以下兩個動機來設計這些組件的基礎:(1)提供詳細的指導和背景資訊:(2)融入常見的優化器概念。接下來,研究者將更詳細地描述這些元素並解釋相關原理。下圖 2 為視覺化展示。
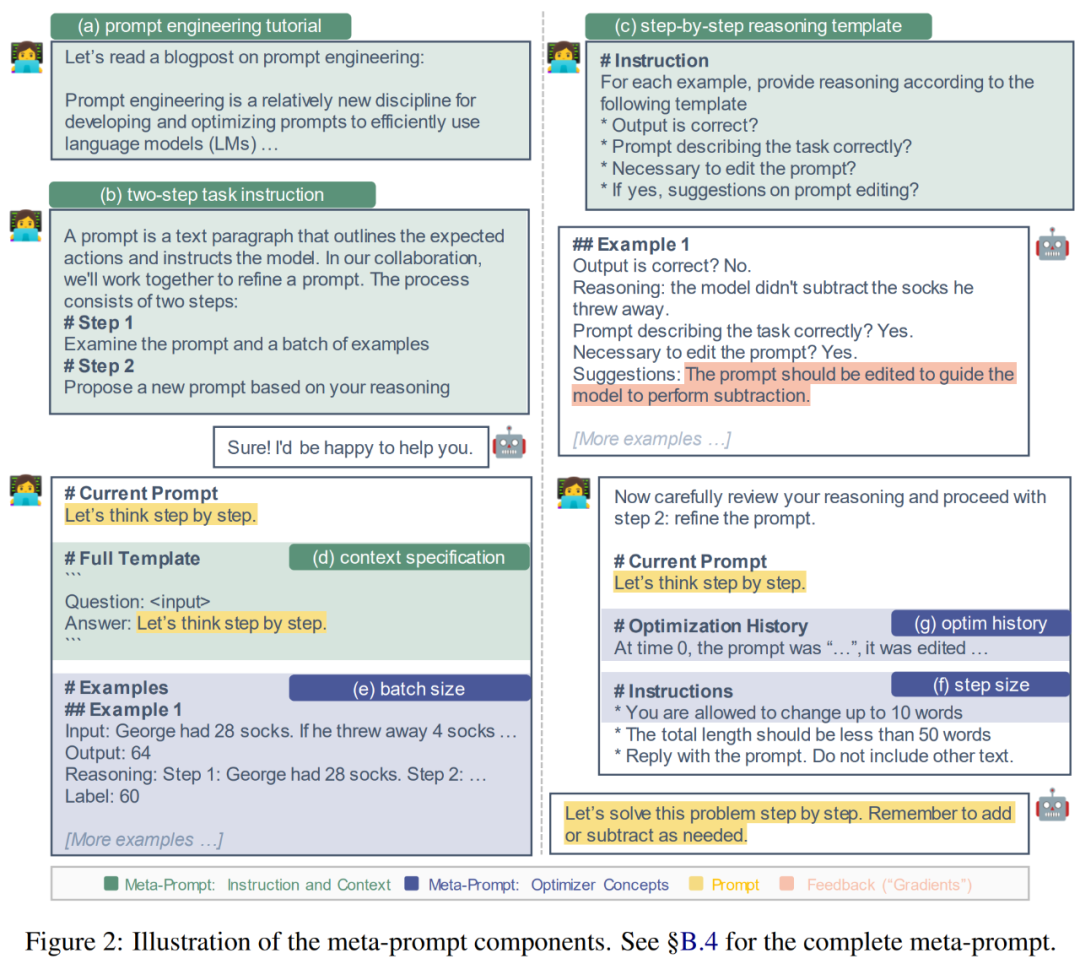
提供詳細的指令和上下文。在先前的研究中,元提示要麼指示提議模型產生提示的釋義,要麼包含有關檢查一批範例的最小指令。因此透過為元提示添加額外的指令和上下文可能是有益的。
(a) 提示工程教學。為了幫助 LLM 更好地理解提示工程的任務,研究者在元提示中提供一個提示工程的線上教學。
(b) 兩步驟任務描述。提示工程任務可以分解為兩個步驟,像 Pryzant et al. 所做的那樣:在第一步,模型應該檢查當前的提示和一批範例。在第二步,模型應該建立一個改進的提示。然而,在 Pryzant et al. 的方法中,每一步都是即時解釋的。與之相反的是,研究者考慮的是在元提示中澄清這兩個步驟,並提前傳遞期望。
(c) 逐步推理模板。為了鼓勵模型仔細檢查批次 B 中的每個範例並反思當前提示的局限性,研究者引導提示提議模型 M_proposal 回答一系列問題。例如:輸出是否正確?提示是否正確描述了任務?是否有必要編輯提示?
(d) 上下文規格。在實踐中,提示插入整個輸入序列的位置是靈活的。它可以在輸入文字之前描述任務,例如“將英語翻譯成法語”。它也可以出現在輸入文字之後,例如“一步一步地思考”,以引發推理能力。為了認識到這些不同的上下文,研究者明確指定了提示與輸入之間的相互作用。例如:「Q: A :一步一步地思考。」
融入常見的優化器概念。在前面方程式 1 中所描述的提示工程問題本質上是一個最佳化問題,而方程式 2 中的提示提議可以被視為進行一次最佳化步驟。因此,研究者考慮以下在基於梯度的最佳化中常用的概念,並發展他們元提示中使用的對應詞。
(e) 批次大小。批次大小是在每個提示提議步驟 (方程式 2) 中使用的 (失敗) 範例數量。作者在分析中嘗試了批次大小為 {1, 2, 4, 8}。
(f) 步长。在基于梯度的优化中,步长确定模型权重更新的幅度。在提示工程中,其对应物可能是可以修改的单词(token)数量。作者直接指定「你可以更改原始提示中的最多 s 个单词」,其中 s ∈ {5, 10, 15, None}。
(g) 优化历史和动量。动量 (Qian, 1999) 是一种通过保持过去梯度的移动平均来加速优化并避免振荡的技术。为了开发动量的语言对应部分,本文包含了所有过去的提示(时间戳为 0, 1, ..., t − 1)、它们在 dev 集上的表现以及提示编辑的摘要。
实验
作者使用以下四组任务来评估 PE2 的有效性和局限性:
1. 数学推理;2. 指令归纳;3. 反事实评估;4. 生产提示。
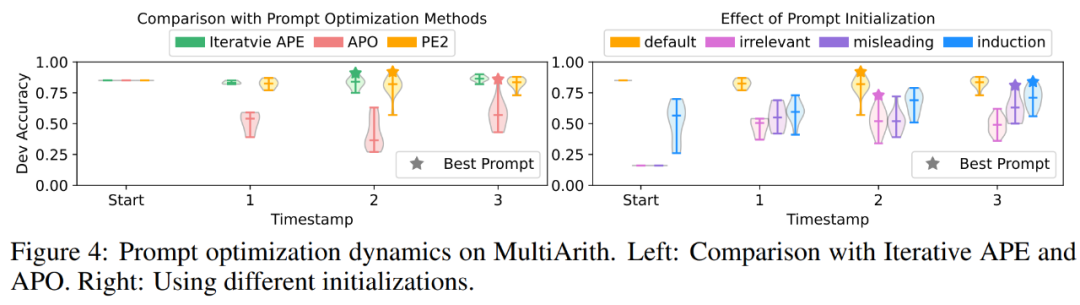
改进的基准与更新的 LLMs。在表 2 的前两部分中,作者观察到使用 TEXT-DAVINCI-003 可以显著提高性能,表明它更能够在 Zero-shot CoT 中解决数学推理问题。此外,两个提示之间的差距缩小了(MultiArith:3.3% → 1.0%,GSM8K:2.3% → 0.6%),表明 TEXT-DAVINCI-003 对提示释义的敏感性减小。鉴于此,依赖简单释义的方法如 Iterative APE,可能无法有效地提升最终结果。更精确和有针对性的提示编辑是提高性能的必要条件。
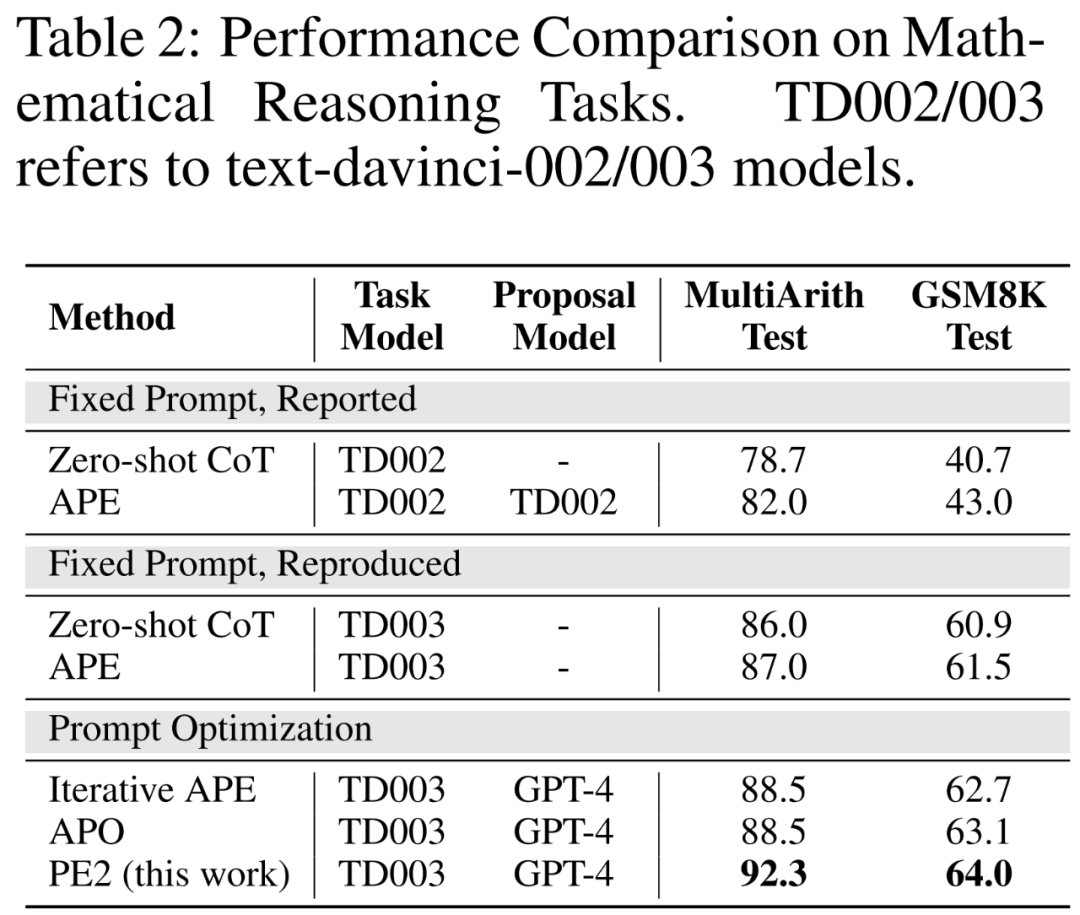
PE2 在各种任务上优于 Iterative APE 和 APO。PE2 能够找到一个在 MultiArith 上达到 92.3% 准确率(比 Zero-shot CoT 高 6.3%)和在 GSM8K 上达到 64.0% 的提示 ( 3.1%)。此外,PE2 找到的提示在指令归纳基准、反事实评估和生产提示上优于 Iterative APE 和 APO。
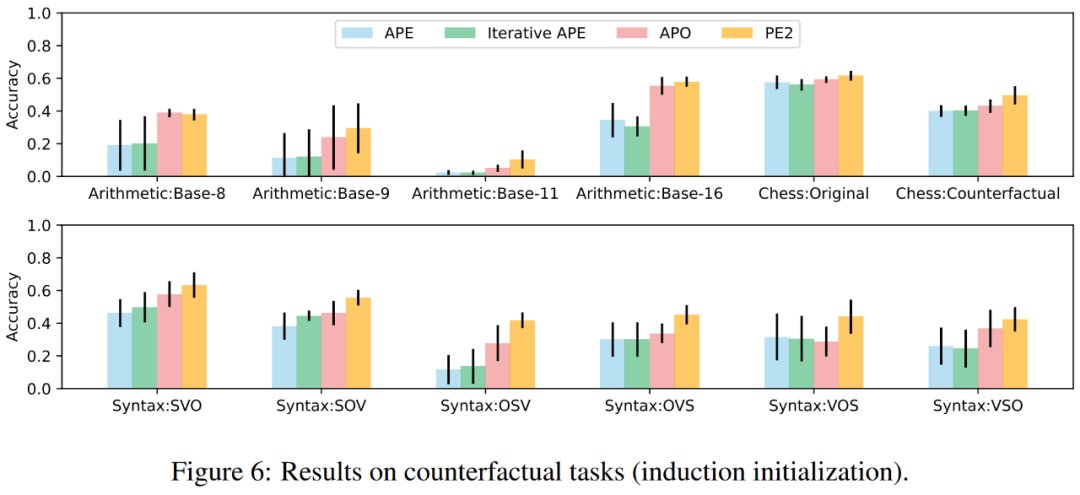
在前面图 1 中,作者总结了 PE2 在指令归纳基准、反事实评估和生产提示上获得的性能提升,展示了 PE2 在各种语言任务上取得了强大的性能。值得注意的是,当使用归纳初始化时,PE2 在 12 个反事实任务中的 11 个上优于 APO (图 6 所示),证明了 PE2 能够推理矛盾和反事实情境。
PE2 生成有针对性的提示编辑和高质量提示。在图 4 (a) 中,作者绘制了提示优化过程中提示提议的质量。实验中观察到三种提示优化方法有非常明显的模式:Iterative APE 基于释义,因此新生成的提示具有较小的方差。APO 进行了大幅度的提示编辑,因此性能在第一步下降。PE2 在这三种方法中是最稳定的。在表 3 中,作者列出了这些方法找到的最佳提示。APO 和 PE2 都能够提供「考虑所有部分 / 细节」的指令。此外,PE2 被设计为仔细检查批次,使其能够超越简单的释义编辑,进行非常具体的提示编辑,例如「记得根据需要添加或减去」。
了解更多内容,请参考原论文。
以上是比「讓我們一步一步思考」這句咒語還管用,提示工程正在被改進的詳細內容。更多資訊請關注PHP中文網其他相關文章!