
模型推理加速:CPU效能提升5倍,蘋果採用快閃記憶體進行大規模推理加速,Siri 2.0即將亮相?

- 王林轉載
- 2024-01-14 22:48:12568瀏覽
蘋果這項新工作將為未來 iPhone 加入大模型的能力帶來無限想像。
近年來,GPT-3、OPT和PaLM等大型語言模型(LLM)在廣泛的自然語言處理(NLP)任務中展現了強大的表現。然而,這些效能的實現需要大量的計算和記憶體推理,因為這些大型語言模型可能包含數千億甚至萬億個參數,這使得在資源有限的設備上高效加載和運行變得具有挑戰性
目前標準的應對方案是將整個模型載入到DRAM 中進行推理,然而這種做法嚴重限制了可以運行的最大模型尺寸。舉個例子,70 億參數的模型需要 14GB 以上的記憶體才能載入半精度浮點格式的參數,這超出了大多數邊緣設備的能力。
為了解決這個局限性,蘋果的研究者提出在快閃記憶體中儲存模型參數,至少比 DRAM 大了一個數量級。接著在推理中,他們直接並巧妙地進行快閃記憶體載入所需參數,不再需要將整個模型擬合到 DRAM 中。
這種方法是基於最近的工作構建,這些工作表明 LLM 在前饋網路(FFN)層中表現出高度稀疏性,其中 OPT、Falcon 等模型的稀疏性更是超過 90%。因此,研究者利用這種稀疏性, 選擇性地僅從快閃記憶體載入具有非零輸入或預測具有非零輸出的參數。

論文地址:https://arxiv.org/pdf/2312.11514.pdf
具體來講,研究者討論了一種受硬體啟發的成本模型,其中包括快閃記憶體、DRAM 和運算核心(CPU 或GPU)。接著引入兩種互補技術來最小化資料傳輸、最大化快閃記憶體吞吐量:
」視窗:只載入前幾個標記的參數,並重複使用最近計算的標記的啟動。這種滑動視窗方法減少了載入權重的IO 請求數量;
行列捆綁:儲存上投影和下投影層的串聯行和列,以讀取快閃記憶體的更大連續塊。這將透過讀取更大的區塊來增加吞吐量。
為了進一步減少從快閃記憶體傳輸到DRAM的權重數量,研究人員嘗試預測FFN的稀疏性並避免載入歸零參數。透過結合使用視窗和稀疏性預測,每個推理查詢僅需載入2%的快閃FFN層。他們還提出了靜態記憶體預分配,以最大程度地減少DRAM內的傳輸並減少推理延遲
本文的快閃記憶體載入成本模型在載入更好資料與讀取更大區塊之間取得了平衡。與CPU 和GPU 中的naive 實作相比,優化此成本模型並選擇性地按需載入參數的快閃記憶體策略可以運行兩倍於DRAM 容量的模型,並將推理速度分別提升4-5 倍和20-25倍。
有人評價稱,這項工作會讓 iOS 開發更加有趣。
快閃記憶體和LLM 推理
頻寬和能量限制
雖然現代NAND 快閃記憶體提供了高頻寬和低延遲,但仍達不到DRAM 的效能水準,尤其是在記憶體受限的系統中。下圖 2a 說明了這些差異。
依賴 NAND 快閃記憶體的 naive 推理實作可能需要為每個前向傳遞重新載入整個模型,這一過程非常耗時,即使是壓縮模型也需要幾秒鐘。此外將資料從 DRAM 傳輸到 CPU 或 GPU 記憶體需要耗費更多能量。
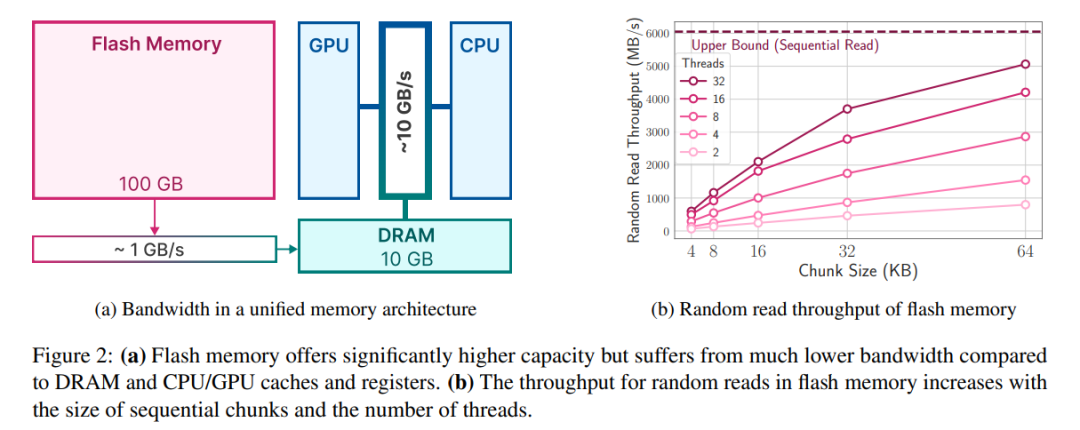
在 DRAM 充足的場景中,載入資料的成本有所降低,這時模型可以駐留在 DRAM 中。不過,模型的初始載入仍然耗能,尤其是在第一個 token 需要快速回應時間的情況下。本文的方法利用 LLM 中的活化稀疏性,透過選擇性地讀取模型權重來解決這些挑戰,從而減少了時間和耗能成本。
重新表達為:取得資料傳輸速率
在大量連續讀取的情況下,快閃記憶體系統表現最佳。舉例來說,蘋果MacBook Pro M2配備了2TB的閃存,在基準測試中,未快取檔案進行1GiB的線性讀取速度超過了6GiB/s。然而,由於這些讀取具有多階段性質,包括作業系統、驅動程式、中階處理器和快閃記憶體控制器,較小的隨機讀取無法達到如此高的頻寬。每個階段都會帶來延遲,對較小的讀取速度造成較大的影響
為了規避這些限制,研究者提倡兩種主要策略,它們可以同時使用。
第一种策略是读取较大的数据块。虽然吞吐量的增长不是线性的(较大的数据块需要较长的传输时间),但初始字节的延迟在总请求时间中所占的比例较小,从而提高了数据读取的效率。图 2b 描述了这一原理。一个与直觉相反但却有趣的观察结果是,在某些情况下,读取比需要更多的数据(但数据块较大)然后丢弃,比只读取需要的部分但数据块较小更快。
第二种策略是利用存储堆栈和闪存控制器固有的并行性来实现并行读取。研究结果表明,在标准硬件上使用多线程 32KiB 或更大的随机读取,可以实现适合稀疏 LLM 推理的吞吐量。
最大化吞吐量的关键在于权重的存储方式,因为提高平均块长度的布局可以显著提高带宽。在某些情况下,读取并随后丢弃多余的数据,而不是将数据分割成更小的、效率更低的数据块,可能是有益的。
进行闪存加载
受上述挑战的启发,研究者提出了优化数据传输量和提高重新表达为:获取数据传输速率的方法,以显著提高推理速度。本节将讨论在可用计算内存远远小于模型大小的设备上进行推理所面临的挑战。
分析该挑战,需要在闪存中存储完整的模型权重。研究者评估各种闪存加载策略的主要指标是延迟,延迟分为三个不同部分:进行闪存加载的 I/O 成本、管理新加载数据的内存开销以及推理操作的计算成本。
苹果将在内存限制条件下减少延迟的解决方案分为三个战略领域,每个领域都针对延迟的特定方面:
1、减少数据负载:旨在通过加载更少的数据来减少与闪存 I/O 操作相关的延迟。
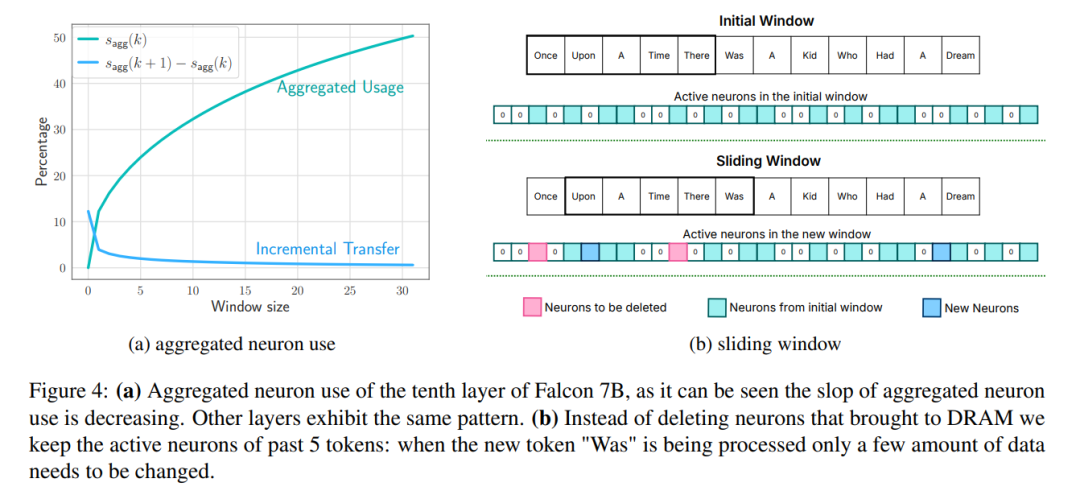
2、优化数据块大小:通过增加加载数据块的大小来提高闪存吞吐量,从而减少延迟。
以下是研究者为提高闪存读取效率而增加数据块大小所采用的策略:
捆绑列和行
基于 Co-activation 的捆绑
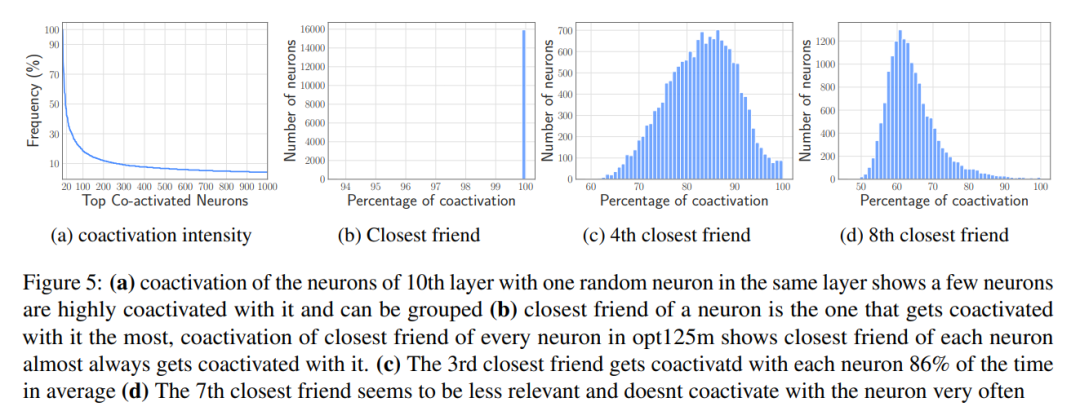
3、有效管理加载的数据:简化数据加载到内存后的管理,最大限度地减少开销。
虽然与访问闪存相比,在 DRAM 中传输数据的效率更高,但会产生不可忽略的成本。在为新神经元引入数据时,由于需要重写 DRAM 中的现有神经元数据,重新分配矩阵和添加新矩阵可能会导致巨大的开销。当 DRAM 中的前馈网络(FFN)有很大一部分(约 25%)需要重写时,这种代价尤其高昂。
为了解决这个问题,研究者采用了另一种内存管理策略。这种策略包括预先分配所有必要的内存,并建立相应的数据结构来进行有效的管理。如图 6 所示,该数据结构包括指针、矩阵、偏移、已使用数和 last_k_active 等元素
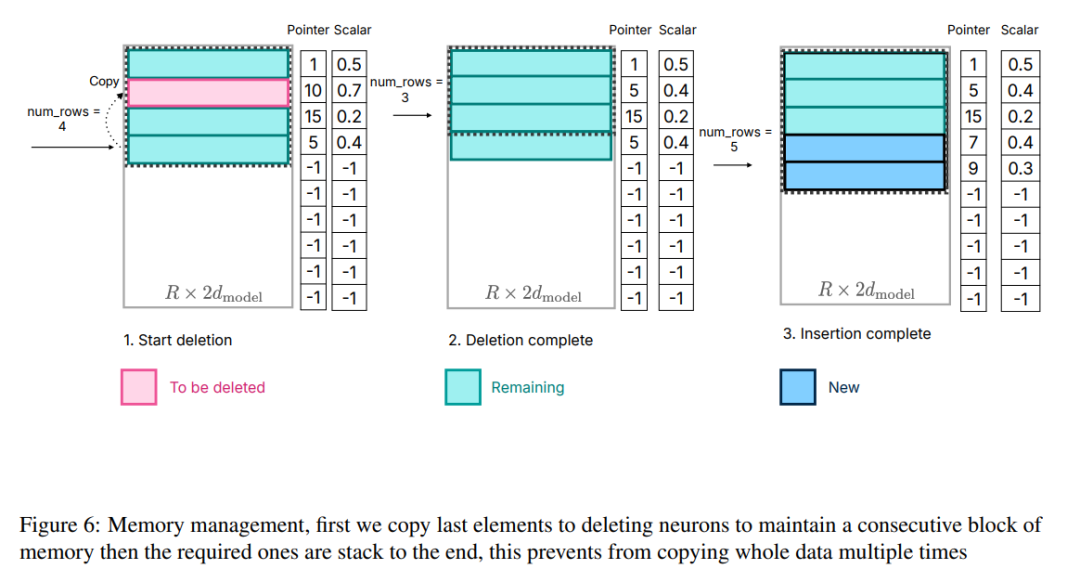
图 6:内存管理,首先将最后一个元素复制到删除神经元,以保持内存块的连续性,然后将所需元素堆栈到最后,这样可以避免多次复制整个数据。
需要注意的是,重点并不在于计算过程,因为这与本文的核心工作无关。这种划分使得研究者能够专注于优化闪存交互和内存管理,从而在内存有限的设备上实现高效的推理
需要进行实验结果的重写
OPT 6.7B 模型的结果
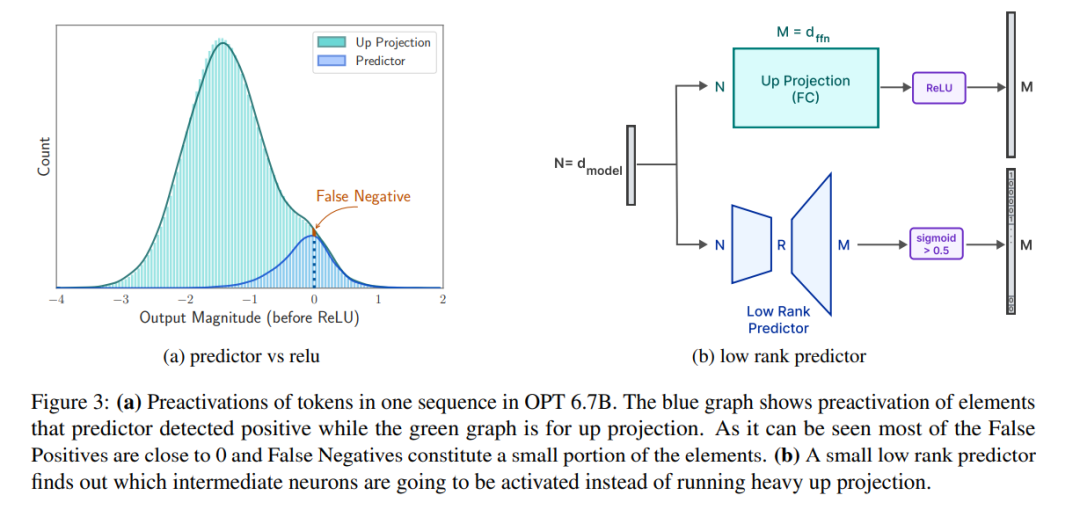
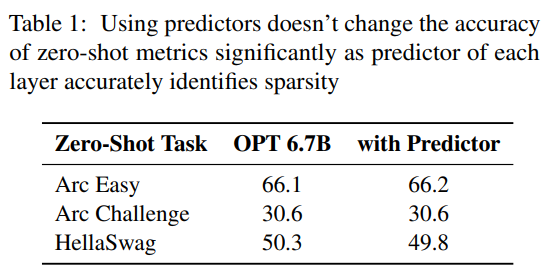
预测器。如图 3a 所示,本文的预测器能准确识别大多数激活的神经元,但偶尔也会误识数值接近于零的非激活神经元。值得注意的是,这些接近零值的假负类神经元被排除后,并不会明显改变最终输出结果。此外,如表 1 所示,这样的预测准确度水平并不会对模型在零样本任务中的表现产生不利影响。
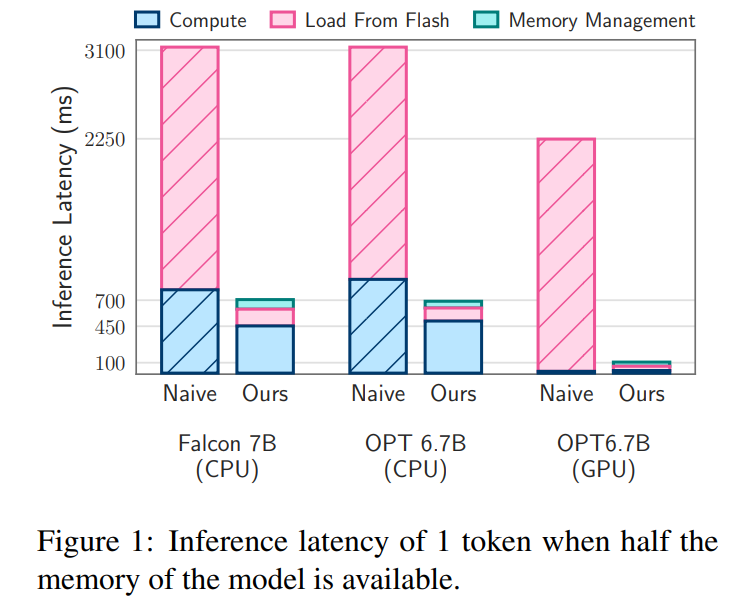
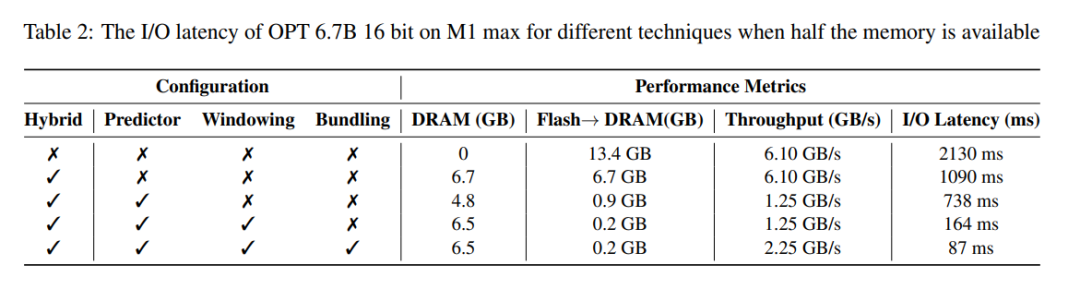
延遲分析。當視窗大小為 5 ,每個 token 需要存取 2.4% 的前饋網路(FFN)神經元。對於 32 位元模型,每次讀取的資料塊大小為 2dmodel × 4 位元組 = 32 KiB,因為它涉及行和列的連接。在 M1 Max 上,進行快閃記憶體載入每個 token 的延遲為 125 毫秒,記憶體管理(包括神經元的刪除和新增)的延遲為 65 毫秒。因此,與記憶體相關的總延遲不到每個 token 190 毫秒(請參閱圖 1)。相較之下,基準方法需要以 6.1GB/s 的速度載入 13.4GB 的數據,導致每個 token 的延遲約為 2330 毫秒。因此,與基線方法相比,本文的方法有了很大改進。
對於 GPU 機器上的 16 位元模型,快閃記憶體載入時間縮短至 40.5 毫秒,記憶體管理時間為 40 毫秒,由於從 CPU 向 GPU 傳輸資料的額外開銷,時間略有增加。儘管如此,基線方法的 I/O 時間仍然超過 2000 毫秒。
表 2 提供了每種方法對效能影響的詳細比較。
Falcon 7B 模型的結果
延遲分析。在本文的模型中使用大小為 4 的窗口,每個 token 需要存取 3.1% 的前饋網路(FFN)神經元。在 32 位元模型中,這相當於每次讀取的資料塊大小為 35.5 KiB(以 2dmodel ×4 位元組計算)。在 M1 Max 裝置上,進行快閃記憶體載入這些資料所需的時間約為 161 毫秒,記憶體管理過程又增加了 90 毫秒,因此每個 token 的總延遲時間為 250 毫秒。相較之下,基線延遲時間約為 2330 毫秒,本文的方法大約快 9 到 10 倍。
以上是模型推理加速:CPU效能提升5倍,蘋果採用快閃記憶體進行大規模推理加速,Siri 2.0即將亮相?的詳細內容。更多資訊請關注PHP中文網其他相關文章!