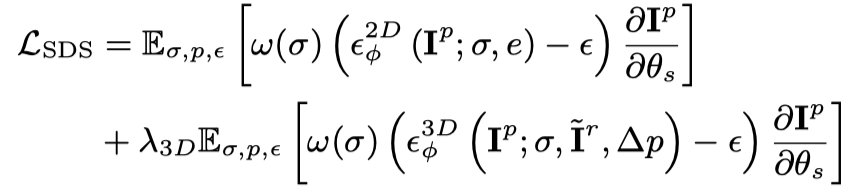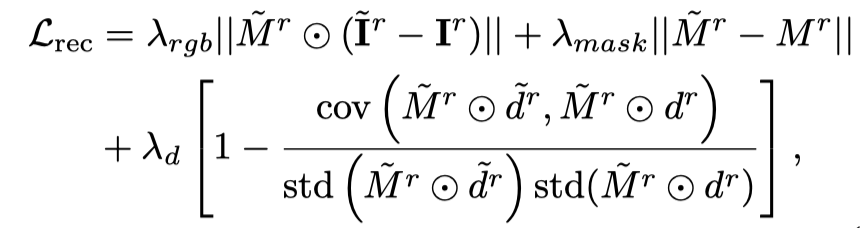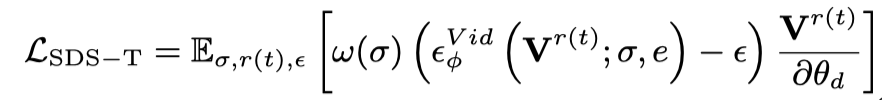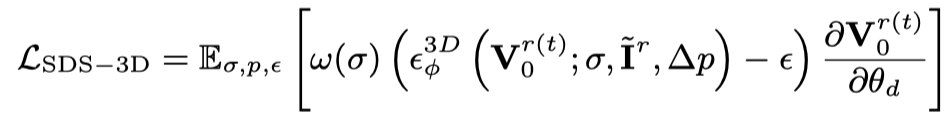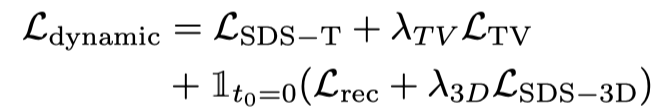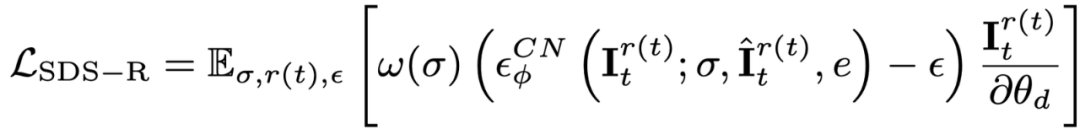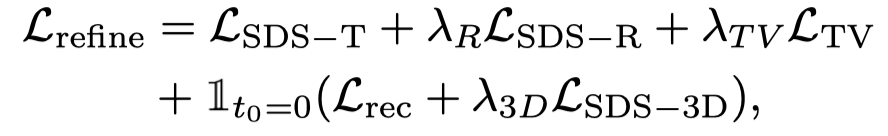近一年来,DreamFusion 引领了一个新潮流,即 3D 静态物体与场景的生成,这在生成技术领域引发了广泛关注。回顾过去一年,我们见证了 3D 静态生成技术在质量和控制性方面的显著进步。技术发展从基于文本的生成起步,逐渐融入单视角图像,进而发展到整合多种控制信号。与此相较,3D 动态场景生成仍处于起步阶段。2023 年初,Meta 推出了 MAV3D,标志着首次尝试基于文本生成 3D 视频。然而,受限于开源视频生成模型的缺乏,这一领域的进展相对缓慢。然而,现在,基于图文结合的 3D 视频生成技术已经问世!尽管基于文本的 3D 视频生成能够产生多样化的内容,但在控制物体的细节和姿态方面仍有局限。在 3D 静态生成领域,使用单张图片作为输入已经能够有效重建 3D 物体。由此受到启发,来自新加坡国立大学(NUS)和华为的研究团队提出了 Animate124 模型。该模型结合单张图片和相应的动作描述,实现了对 3D 视频生成的精准控制。
- 项目主页: https://animate124.github.io/
- 论文地址: https://arxiv.org/abs/2311.14603
- Code: https://github.com/HeliosZhao/Animate124
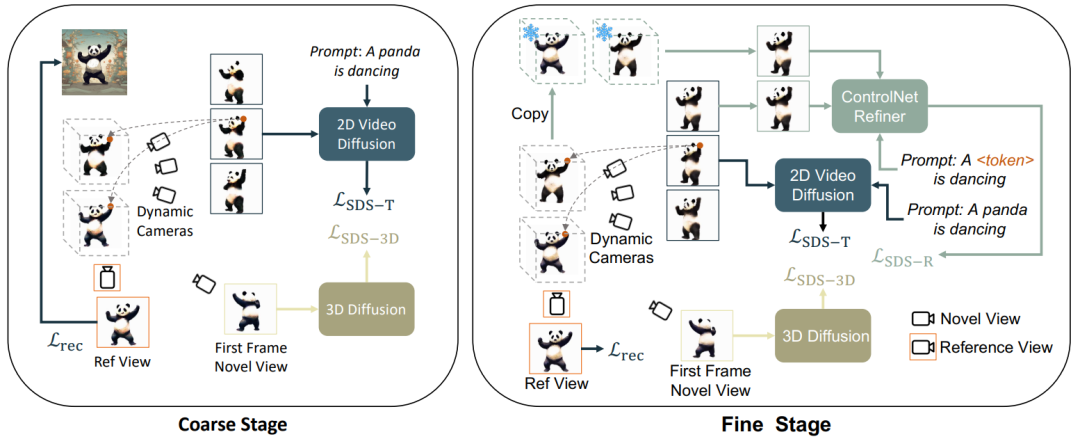
根据静态和动态,粗糙和精细优化,本文将 3D 视频生成分为了 3 个阶段:1)静态生成阶段:使用文生图和 3D 图生图扩散模型,从单张图像生成 3D 物体;2)动态粗糙生成阶段:使用文生视频模型,根据语言描述优化动作;3) 语义优化阶段:额外使用个性化微调的 ControlNet,对第二阶段语言描述对外观造成的偏移进行优化改善。
本文延续 Magic123 的方法,使用文生图(Stable Diffusion)和 3D 图生图(Zero-1-to-3)进行基于图片的静态物体生成:
对于条件图片所对应的视角,额外使用损失函数进行优化:
通过上述两个优化目标,得到多视角 3D 一致的静态物体(此阶段在框架图中省略)。此阶段主要使用文生视频扩散模型,将静态 3D 视为初始帧,根据语言描述生成动作。具体来说,动态 3D 模型(dynamic NeRF)渲染连续时间戳的多帧视频,并将此视频输入文生视频扩散模型,采用 SDS 蒸馏损失对动态 3D 模型进行优化:
仅使用文生视频的蒸馏损失会导致 3D 模型遗忘图片的内容,并且随机采样会导致视频的初始和结束阶段训练不充分。因此,本文的研究者们对开始和结束的时间戳进行过采样。并且,在采样初始帧时,额外使用静态函数进行优化(3D 图生图的 SDS 蒸馏损失):
即使採用了初始幀過採樣並且對其額外監督,在使用文生視訊擴散模型的最佳化過程中,物體的外觀仍然會受到文字的影響,從而偏移參考圖片。因此,本文提出了語意最佳化階段,透過個人化模型對語意偏移進行改善。 由於只有單張圖片,無法對文生視訊模型進行個人化訓練,本文引入了基於圖文的擴散模型,並對此擴散模型進行個性化微調。此擴散模型應不改變原有影片的內容和動作,僅對外觀進行調整。因此,本文採用 ControlNet-Tile 圖文模型,以上一階段產生的影片影格作為條件,依照語言進行最佳化。 ControlNet 是基於 Stable Diffusion 模型,只需要對 Stable Diffusion 進行個人化微調(Textual Inversion),即可擷取參考影像中的語意資訊。個人化微調之後,將影片視為多幀影像,使用ControlNet 對單一影像進行監督:
#另外,因為ControlNet 使用粗糙的圖片作為條件,classifier-free guidance (CFG) 可以使用正常範圍(10 左右),而不用與文生圖以及文生視訊模型一樣使用極大的數值(通常是100)。過大的 CFG 會導致影像過飽和,因此,使用 ControlNet 擴散模型可以緩解過飽和現象,實現更優的生成結果。此階段的監督由動態階段的損失和ControlNet 監督結合而成:
作為第一個基於圖文的3D 視訊生成模型,本文與兩個baseline 模型和MAV3D 進行了比較。與其他方法相比,Animate124 有更好的效果。
#E2.Animate124 與兩個baseline 比較
圖3.1. Animate124 與MAV3D 文生3D 影片比較
#圖3.1. Animate124 與MAV3D 圖生3D 影片比較本文使用CLIP 和人工評價產生的質量,CLIP 指標包括與文字的相似度和檢索準確率,與圖片的相似度,以及時域一致性。人工評價指標包括與文字的相似度,與圖片的相似度,影片品質,動作真實程度以及動作幅度。人工評價表現為單一模型與 Animate124 在對應指標上所選擇的比例。 與兩個 baseline 模型相比,Animate124 在 CLIP 和人工評價上均取得更好的效果。
表1. Animate124 與兩個baseline 量化比較Animate124 是第一個根據文字描述,將任一圖片變成3D 影片的方法。其採用多種擴散模型進行監督和引導,優化 4D 動態表徵網絡,從而產生高品質 3D 視訊。 以上是只需一張圖片、一句動作指令,Animate124輕鬆生成3D視頻的詳細內容。更多資訊請關注PHP中文網其他相關文章!