
無需SA依賴,高效實現像素級推理的位元組多模態大模型PixelLM

- WBOY轉載
- 2024-01-10 21:46:36614瀏覽
多模態大模型爆發,準備好進入影像編輯、自動駕駛和機器人技術等細粒度任務中實際應用了嗎?
目前大多數模型的能力還是局限於產生對整體圖像或特定區域的文字描述,在像素級理解方面的能力(例如物體分割)相對有限。
針對這個問題,一些工作開始探索借助多模態大模型來處理使用者的分割指令(例如,「請分割出圖片中富含維生素C的水果」)。
然而,市面上的方法都有兩個主要缺點:
1) 無法處理涉及多個目標物件的任務,而這在現實世界場景中是不可或缺的;
2) 依賴像SAM這樣的預訓練影像分割模型,而SAM的一次前向傳播所需的運算量已經足夠Llama-7B產生500多個token了。
為了解決這個問題,位元組跳動智能創作團隊聯合北京交通大學、北京科技大學的研究人員提出了首個無需依賴SAM的高效像素級推理大模型PixelLM。
在具體介紹它之前,先來體驗幾組PixelLM實際分割的效果:
#比較之前的工作,PixelLM的優勢在於:
- ##能夠熟練處理任意數量的開放域目標和多樣化的複雜推理分割任務。
- 避免了額外的、成本高昂的分割模型,提升了效率和對不同應用的遷移能力。


 圖片
圖片
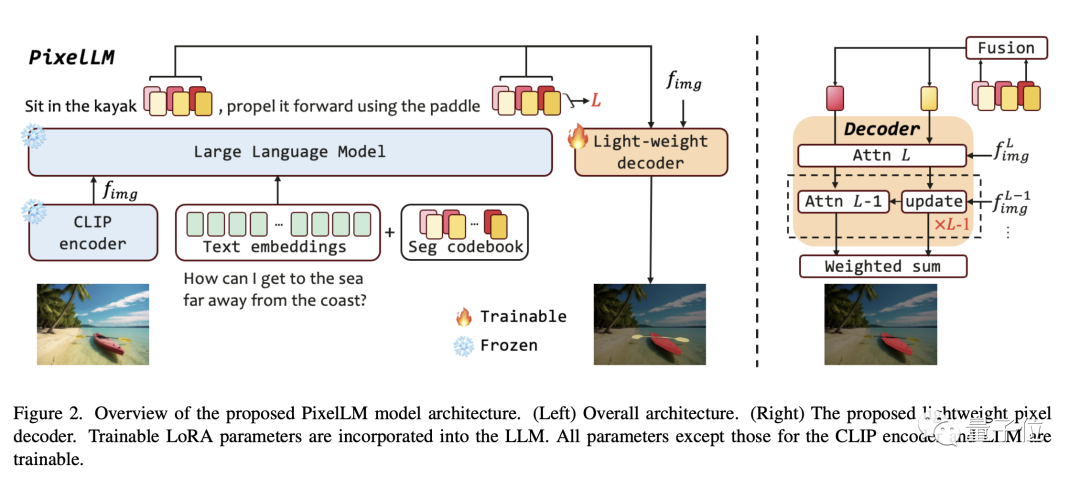
- 預先訓練的CLIP-ViT視覺編碼器
- 大語言模型
- 輕量級像素解碼器
- 分割碼表Seg Codebook
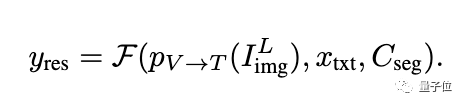 圖片
圖片
 圖片
圖片
下圖展示了每組內多個token時的效果。注意力圖是每個token經過解碼器處理後的樣子,這個可視化結果表明,多個token提供了獨特且互補的信息,從而實現了更有效的分割輸出。
 圖片
圖片
此外,為了增強模型區分多個目標的能力,PixelLM也額外設計了一個Target Refinement Loss。
MUSE資料集
儘管已經提出了上述解決方案,但為了充分發揮模型的能力,模型仍然需要適當的訓練資料。回顧目前可用的公開資料集,發現現有的資料有以下主要限制:
1) 對物件細節的描述不夠充足;
2) 缺乏具有複雜推理和多種目標數量的問題-答案對。
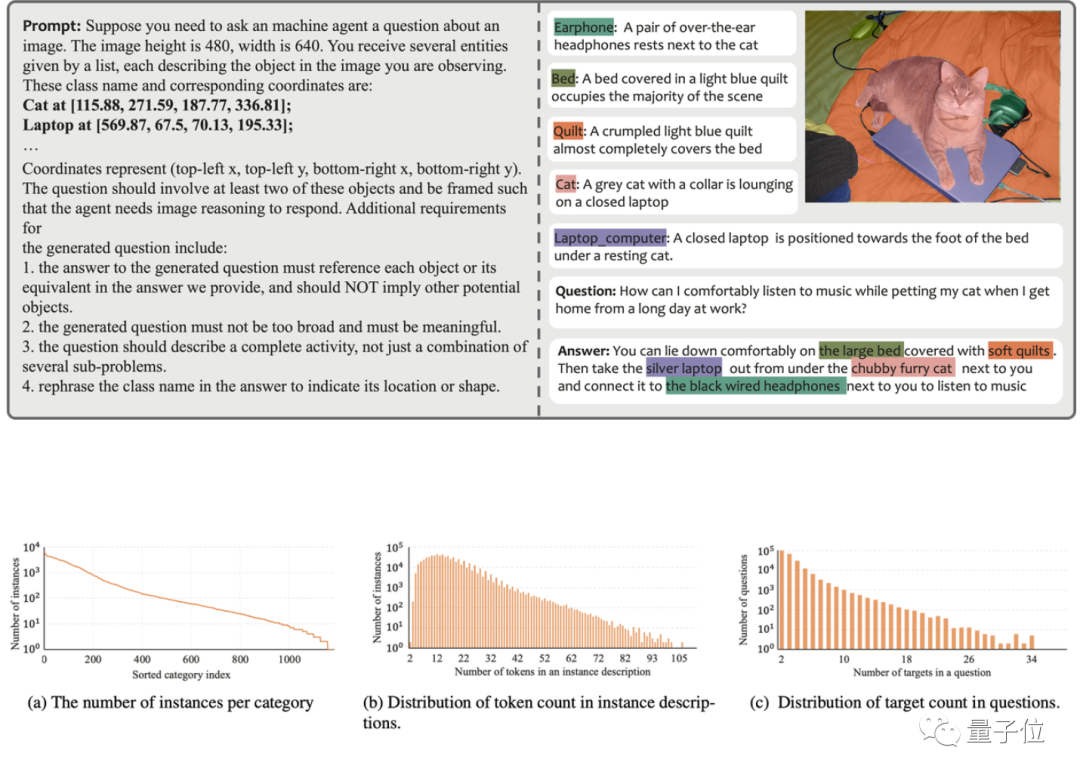
為了解決這些問題,研究團隊借助GPT-4V建立了一個自動化的資料標註管線,並由此產生了MUSE資料集。下圖展示了MUSE產生時所用到的Prompt及產生的資料範例。
 圖片
圖片
在MUSE中,所有實例遮罩都來自LVIS資料集,並且額外添加了根據圖像內容生成的詳細文字描述。 MUSE包含了24.6萬個問題-答案對,每個問題-答案對平均涉及3.7個目標物體。此外,研究團隊對資料集進行了詳盡的統計分析:
類別統計:MUSE中有來自原始LVIS資料集的1000多個類別,以及90萬個具有獨特描述的實例,這些描述基於問題-答案對的上下文而改變。圖(a)顯示了所有問題-答案對中每個類別的實例數量。
Token數目統計:圖(b)展示了實例描述的token數目分佈,其中有的實例描述包含了超過100個tokens。這些描述不僅限於簡單的類別名稱;相反,它們透過基於GPT-4V的資料生成流程,大量豐富了每個實例的詳細信息,涵蓋了外觀、屬性和與其他物件等的關係。資料集中資訊的深度和多樣性增強了訓練模型的泛化能力,使其能夠有效地解決開放域問題。
目標數目統計:圖(c)展示了每個問題-答案對中目標數量的統計數據。平均目標數為3.7,最大目標數可達34個。這個數字可以覆蓋單一影像的大多數目標推理場景。
演算法測評
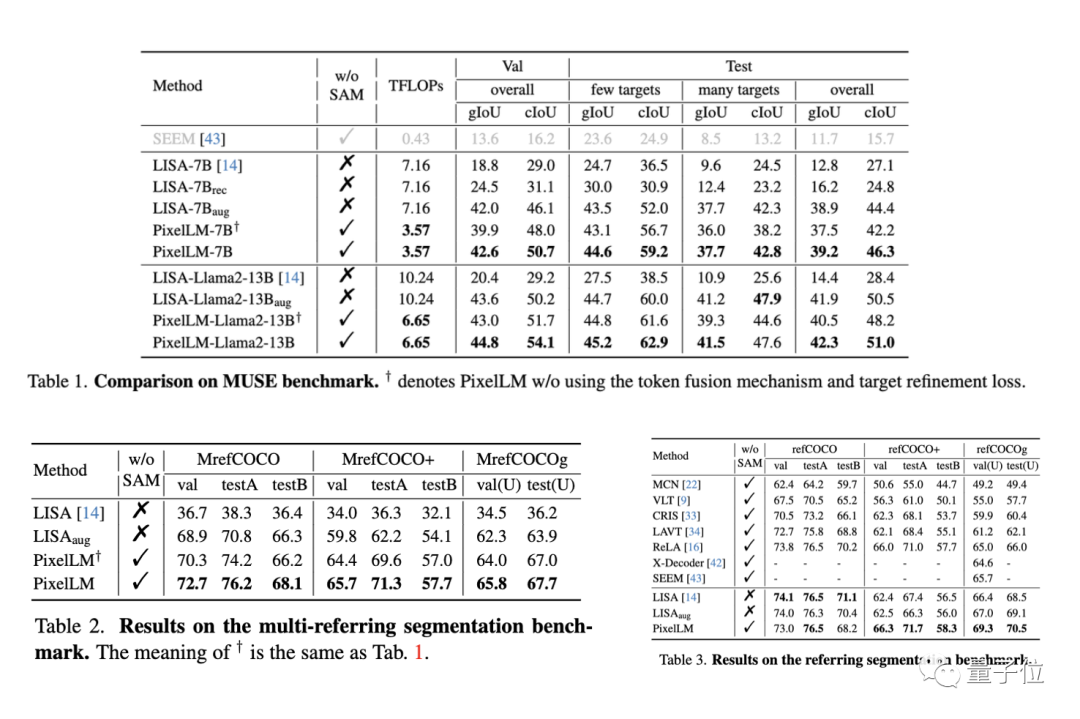
研究團隊在三個benchmark上評測了PixelLM的性能,包括MUSE benchmark, referring segmentation benchmark,以及multi-referring segmentation benchmark. 在multi-referring segmentation benchmark中,研究團隊要求模型在一個問題中連續分割出referring segmentation benchmark中每個影像所包含的多個目標。
同時,由於PixelLM是首個處理涉及多目標複雜像素推理任務的模型,研究團隊建立了四個baseline以對模型進行比較分析。
其中三個baseline是基於與PixelLM最相關工作LISA,包括:
1)原始的LISA;
2)LISA_rec: 先將問題輸入LLAVA-13B以得到目標的文字回复,再用LISA分割這些文字;
3)LISA_aug:直接將MUSE加入LISA的訓練資料。
4) 另外一個則是不使用LLM的通用分割模型SEEM。
 圖片
圖片
在三個benchmark的絕大多數指標上,PixelLM的效能都優於其他方法,且由於PixelLM不依賴SAM,其TFLOPs遠低於同尺寸的模型。
有興趣的小夥伴可以先關註一波,坐等程式碼開源了~
參考連結:
[1]https://www.php.cn/ link/9271858951e6fe9504d1f05ae8576001
[2]https://www.php.cn/link/f1686b4badcf28d33ed632036c7#0b8
以上是無需SA依賴,高效實現像素級推理的位元組多模態大模型PixelLM的詳細內容。更多資訊請關注PHP中文網其他相關文章!