


写在最前:
本文主要描述在网站的不同的并发访问量级下,Mysql架构的演变。
可扩展性
架构的可扩展性往往和并发是息息相关,没有并发的增长,也就没有必要做高可扩展性的架构,这里对可扩展性进行简单介绍一下,常用的扩展手段有以下两种:
Scale-up : 纵向扩展,通过替换为更好的机器和资源来实现伸缩,提升服务能力。
Scale-out : 横向扩展, 通过加节点(机器)来实现伸缩,提升服务能力。
对于互联网的高并发应用来说,无疑Scale out才是出路,通过纵向的买更高端的机器一直是我们所避讳的问题,也不是长久之计,在scale out的理论下,可扩展性的理想状态是什么?
可扩展性的理想状态
一个服务,当面临更高的并发的时候,能够通过简单增加机器来提升服务支撑的并发度,且增加机器过程中对线上服务无影响(no down time),这就是可扩展性的理想状态!
架构的演变
V1.0 简单网站架构
一个简单的小型网站或者应用背后的架构可以非常简单, 数据存储只需要一个mysql instance就能满足数据读取和写入需求(这里忽略掉了数据备份的实例),处于这个时间段的网站,一般会把所有的信息存到一个database instance里面。

在这样的架构下,我们来看看数据存储的瓶颈是什么?
1.数据量的总大小 一个机器放不下时
2.数据的索引(B+ Tree)一个机器的内存放不下时
3.访问量(读写混合)一个实例不能承受
只有当以上3件事情任何一件或多件满足时,我们才需要考虑往下一级演变。 从此我们可以看出,事实上对于很多小公司小应用,这种架构已经足够满足他们的需求了,初期数据量的准确评估是杜绝过度设计很重要的一环,毕竟没有人愿意为不可能发生的事情而浪费自己的经历。
这里简单举个我的例子,对于用户信息这类表 (3个索引),16G内存能放下大概2000W行数据的索引,简单的读和写混合访问量3000/s左右没有问题,你的应用场景是否
V2.0 垂直拆分
一般当V1.0 遇到瓶颈时,首先最简便的拆分方法就是垂直拆分,何谓垂直?就是从业务角度来看,将关联性不强的数据拆分到不同的instance上,从而达到消除瓶颈的目标。以图中的为例,将用户信息数据,和业务数据拆分到不同的三个实例上。对于重复读类型比较多的场景,我们还可以加一层cache,来减少对DB的压力。

在这样的架构下,我们来看看数据存储的瓶颈是什么?
1.单实例单业务 依然存在V1.0所述瓶颈
遇到瓶颈时可以考虑往本文更高V版本升级, 若是读请求导致达到性能瓶颈可以考虑往V3.0升级, 其他瓶颈考虑往V4.0升级
V3.0 主从架构
此类架构主要解决V2.0架构下的读问题,通过给Instance挂数据实时备份的思路来迁移读取的压力,在Mysql的场景下就是通过主从结构,主库抗写压力,通过从库来分担读压力,对于写少读多的应用,V3.0主从架构完全能够胜任

在这样的架构下,我们来看看数据存储的瓶颈是什么?
1.写入量主库不能承受
V4.0 水平拆分
对于V2.0 V3.0方案遇到瓶颈时,都可以通过水平拆分来解决,水平拆分和垂直拆分有较大区别,垂直拆分拆完的结果,在一个实例上是拥有全量数据的,而水平拆分之后,任何实例都只有全量的1/n的数据,以下图Userinfo的拆分为例,将userinfo拆分为3个cluster,每个cluster持有总量的1/3数据,3个cluster数据的总和等于一份完整数据(注:这里不再叫单个实例 而是叫一个cluster 代表包含主从的一个小mysql集群)

数据如何路由?
1.Range拆分
sharding key按连续区间段路由,一般用在有严格自增ID需求的场景上,如Userid, Userid Range的小例子:以userid 3000W 为Range进行拆分 1号cluster userid 1-3000W 2号cluster userid 3001W-6000W
2.List拆分
List拆分与Range拆分思路一样,都是通过给不同的sharding key来路由到不同的cluster,但是具体方法有些不同,List主要用来做sharding key不是连续区间的序列落到一个cluster的情况,如以下场景:
假定有20个音像店,分布在4个有经销权的地区,如下表所示:
|
地区 |
商店ID 号 |
|
北区 |
3, 5, 6, 9, 17 |
|
东区 |
1, 2, 10, 11, 19, 20 |
|
西区 |
4, 12, 13, 14, 18 |
|
中心区 |
7, 8, 15, 16 |
业务希望能够把一个地区的所有数据组织到一起来搜索,这种场景List拆分可以轻松搞定
3.Hash拆分
通过对sharding key 进行哈希的方式来进行拆分,常用的哈希方法有除余,字符串哈希等等,除余如按userid%n 的值来决定数据读写哪个cluster,其他哈希类算法这里就不细展开讲了。
数据拆分后引入的问题:
数据水平拆分引入的问题主要是只能通过sharding key来读写操作,例如以userid为sharding key的切分例子,读userid的详细信息时,一定需要先知道userid,这样才能推算出再哪个cluster进而进行查询,假设我需要按username进行检索用户信息,需要引入额外的反向索引机制(类似HBASE二级索引),如在redis上存储username->userid的映射,以username查询的例子变成了先通过查询username->userid,再通过userid查询相应的信息。
实际上这个做法很简单,但是我们不要忽略了一个额外的隐患,那就是数据不一致的隐患。存储在redis里的username->userid和存储在mysql里的userid->username必须需要是一致的,这个保证起来很多时候是一件比较困难的事情,举个例子来说,对于修改用户名这个场景,你需要同时修改redis和mysql,这两个东西是很难做到事务保证的,如mysql操作成功 但是redis却操作失败了(分布式事务引入成本较高),对于互联网应用来说,可用性是最重要的,一致性是其次,所以能够容忍小量的不一致出现. 毕竟从占比来说,这类的不一致的比例可以微乎其微到忽略不计(一般写更新也会采用mq来保证直到成功为止才停止重试操作)
在这样的架构下,我们来看看数据存储的瓶颈是什么?
在这个拆分理念上搭建起来的架构,理论上不存在瓶颈(sharding key能确保各cluster流量相对均衡的前提下),不过确有一件恶心的事情,那就是cluster扩容的时候重做数据的成本,如我原来有3个cluster,但是现在我的数据增长比较快,我需要6个cluster,那么我们需要将每个cluster 一拆为二,一般的做法是
1.摘下一个slave,停同步,
2.对写记录增量log(实现上可以业务方对写操作 多一次写持久化mq 或者mysql主创建trigger记录写 等等方式)
3.开始对静态slave做数据, 一拆为二
4.回放增量写入,直到追上的所有增量,与原cluster基本保持同步
5.写入切换,由原3 cluster 切换为6cluster
有没有类似飞机空中加油的感觉,这是一个脏活,累活,容易出问题的活,为了避免这个,我们一般在最开始的时候,设计足够多的sharding cluster来防止可能的cluster扩容这件事情

 深度学习架构的对比分析May 17, 2023 pm 04:34 PM
深度学习架构的对比分析May 17, 2023 pm 04:34 PM深度学习的概念源于人工神经网络的研究,含有多个隐藏层的多层感知器是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示,以表征数据的类别或特征。它能够发现数据的分布式特征表示。深度学习是机器学习的一种,而机器学习是实现人工智能的必经之路。那么,各种深度学习的系统架构之间有哪些差别呢?1.全连接网络(FCN)完全连接网络(FCN)由一系列完全连接的层组成,每个层中的每个神经元都连接到另一层中的每个神经元。其主要优点是“结构不可知”,即不需要对输入做出特殊的假设。虽然这种结构不可知使得完
 此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处Jun 14, 2023 pm 01:43 PM
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处Jun 14, 2023 pm 01:43 PM前段时间,一条指出谷歌大脑团队论文《AttentionIsAllYouNeed》中Transformer构架图与代码不一致的推文引发了大量的讨论。对于Sebastian的这一发现,有人认为属于无心之过,但同时也会令人感到奇怪。毕竟,考虑到Transformer论文的流行程度,这个不一致问题早就应该被提及1000次。SebastianRaschka在回答网友评论时说,「最最原始」的代码确实与架构图一致,但2017年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
 多路径多领域通吃!谷歌AI发布多领域学习通用模型MDLMay 28, 2023 pm 02:12 PM
多路径多领域通吃!谷歌AI发布多领域学习通用模型MDLMay 28, 2023 pm 02:12 PM面向视觉任务(如图像分类)的深度学习模型,通常用来自单一视觉域(如自然图像或计算机生成的图像)的数据进行端到端的训练。一般情况下,一个为多个领域完成视觉任务的应用程序需要为每个单独的领域建立多个模型,分别独立训练,不同领域之间不共享数据,在推理时,每个模型将处理特定领域的输入数据。即使是面向不同领域,这些模型之间的早期层的有些特征都是相似的,所以,对这些模型进行联合训练的效率更高。这能减少延迟和功耗,降低存储每个模型参数的内存成本,这种方法被称为多领域学习(MDL)。此外,MDL模型也可以优于单
 机器学习系统架构的十个要素Apr 13, 2023 pm 11:37 PM
机器学习系统架构的十个要素Apr 13, 2023 pm 11:37 PM这是一个AI赋能的时代,而机器学习则是实现AI的一种重要技术手段。那么,是否存在一个通用的通用的机器学习系统架构呢?在老码农的认知范围内,Anything is nothing,对系统架构而言尤其如此。但是,如果适用于大多数机器学习驱动的系统或用例,构建一个可扩展的、可靠的机器学习系统架构还是可能的。从机器学习生命周期的角度来看,这个所谓的通用架构涵盖了关键的机器学习阶段,从开发机器学习模型,到部署训练系统和服务系统到生产环境。我们可以尝试从10个要素的维度来描述这样的一个机器学习系统架构。1.
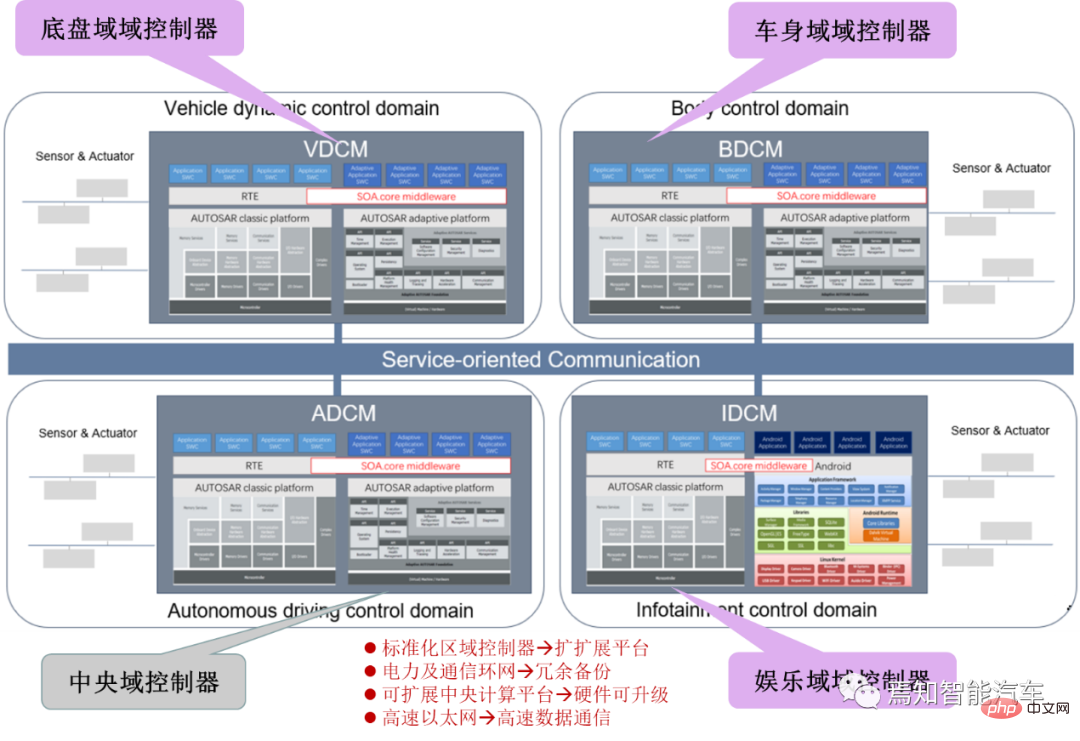 SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM
SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM对于下一代集中式电子电器架构而言,采用central+zonal 中央计算单元与区域控制器布局已经成为各主机厂或者tier1玩家的必争选项,关于中央计算单元的架构方式,有三种方式:分离SOC、硬件隔离、软件虚拟化。集中式中央计算单元将整合自动驾驶,智能座舱和车辆控制三大域的核心业务功能,标准化的区域控制器主要有三个职责:电力分配、数据服务、区域网关。因此,中央计算单元将会集成一个高吞吐量的以太网交换机。随着整车集成化的程度越来越高,越来越多ECU的功能将会慢慢的被吸收到区域控制器当中。而平台化
 2023年值得了解的几个前端格式化工具【总结】Sep 30, 2022 pm 02:17 PM
2023年值得了解的几个前端格式化工具【总结】Sep 30, 2022 pm 02:17 PMeslint 使用eslint的生态链来规范开发者对js/ts基本语法的规范。防止团队的成员乱写. 这里主要使用到的eslint的包有以下几个: 使用的以下语句来按照依赖: 接下来需要对eslint的
 AI基础设施:IT和数据科学团队协作的重要性May 18, 2023 pm 11:08 PM
AI基础设施:IT和数据科学团队协作的重要性May 18, 2023 pm 11:08 PM人工智能(AI)已经改变了许多行业的游戏规则,使企业能够提高效率、决策制定和客户体验。随着人工智能的不断发展和变得越来越复杂,企业投资于合适的基础设施来支持其开发和部署至关重要。该基础设施的一个关键方面是IT和数据科学团队之间的协作,因为两者在确保人工智能计划的成功方面都发挥着关键作用。人工智能的快速发展导致对计算能力、存储和网络能力的需求不断增加。这种需求给传统IT基础架构带来了压力,而传统IT基础架构并非旨在处理AI所需的复杂和资源密集型工作负载。因此,企业现在正在寻求构建能够支持AI工作负
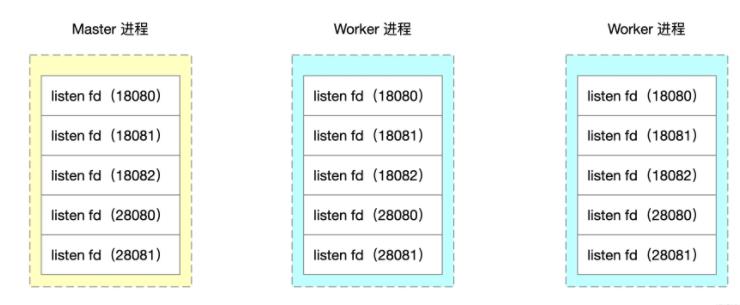 深析如何通过Nginx源码来实现worker进程隔离Nov 06, 2022 pm 04:41 PM
深析如何通过Nginx源码来实现worker进程隔离Nov 06, 2022 pm 04:41 PM本文给大家介绍如何通过修改Nginx源码实现基于端口号的 Nginx worker进程隔离方案。看看到底怎么修改Nginx源码,还有Nginx事件循环、Nginx 进程模型、fork资源共享相关的知识。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Dreamweaver CS6
視覺化網頁開發工具

禪工作室 13.0.1
強大的PHP整合開發環境

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

Atom編輯器mac版下載
最受歡迎的的開源編輯器

