



只需一句话描述,就能在一大段视频中定位到对应片段!
比如描述“一个人一边下楼梯一边喝水”,通过视频画面和脚步声的匹配,新方法一下子就能揪出对应起止时间戳:

就连“大笑”这种语义难理解型的,也能准确定位:

方法名为自适应双分支促进网络(ADPN),由清华大学研究团队提出。
具体来说,ADPN是用来完成一个叫做视频片段定位(Temporal Sentence Grounding,TSG)的视觉-语言跨模态任务,也就是根据查询文本从视频中定位到相关片段。
ADPN的特点在于能够高效利用视频中视觉和音频模态的一致性与互补性来增强视频片段定位性能。
相较其他利用音频的TSG工作PMI-LOC、UMT,ADPN方法从音频模态获取了更显著地性能提升,多项测试拿下新SOTA。
目前该工作已经被ACM Multimedia 2023接收,且已完全开源。

一起来看看ADPN究竟是个啥~
一句话定位视频片段
视频片段定位(Temporal Sentence Grounding,TSG)是一项重要的视觉-语言跨模态任务。
它的目的是根据自然语言查询,在一个未剪辑的视频中找到与之语义匹配的片段的起止时间戳,它要求方法具备较强的时序跨模态推理能力。
然而,大多数现有的TSG方法只考虑了视频中的视觉信息,如RGB、光流(optical flows)、深度(depth)等,而忽略了视频中天然伴随的音频信息。
音频信息往往包含丰富的语义,并且与视觉信息存在一致性和互补性,如下图所示,这些性质会有助于TSG任务。
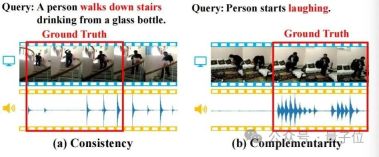
△图1
(a)一致性:视频画面和脚步声一致地匹配了查询中的“走下楼梯”的语义;(b)互补性:视频画面难以识别出特定行为来定位查询中的“笑”的语义,但是笑声的出现提供了强有力的互补定位线索。
因此研究人员深入研究了音频增强的视频片段定位任务(Audio-enhanced Temporal Sentence Grounding,ATSG),旨在更优地从视觉与音频两种模态中捕获定位线索,然而音频模态的引入也带来了如下挑战:
- 音频和视觉模态的一致性和互补性是与查询文本相关联的,因此捕获视听一致性与互补性需要建模文本-视觉-音频三模态的交互。
- 音频和视觉间存在显著的模态差异,两者的信息密度和噪声强度不同,这会影响视听学习的性能。
为了解决上述挑战,研究人员提出了一种新颖的ATSG方法“自适应双分支促进网络”(Adaptive Dual-branch Prompted Network,ADPN)。
通过一种双分支的模型结构设计,该方法能够自适应地建模音频和视觉之间的一致性和互补性,并利用一种基于课程学习的去噪优化策略进一步消除音频模态噪声的干扰,揭示了音频信号对于视频检索的重要性。
ADPN的总体结构如下图所示:
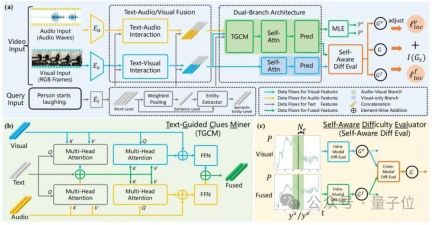
△图2:自适应双分支促进网络(ADPN)总体示意图
它主要包含三个设计:
1、双分支网络结构设计
考虑到音频的噪声更加明显,且对于TSG任务而言,音频通常存在更多冗余信息,因此音频和视觉模态的学习过程需要赋予不同的重要性,因此本文涉及了一个双分支的网络结构,在利用音频和视觉进行多模态学习的同时,对视觉信息进行强化。
具體地,請參見圖2(a),ADPN同時訓練一個只使用視覺訊息的分支(視覺分支)和一個同時使用視覺訊息和音訊訊息的分支(聯合分支)。
兩個分支擁有相似的結構,其中聯合分支增加了一個文字引導的線索挖掘單元(TGCM)建模文字-視覺-音訊模態互動。訓練過程兩個分支同時更新參數,推理階段使用聯合分支的結果作為模型預測結果。
2、文字引導的線索挖掘單元(Text-Guided Clues Miner,TGCM)
考慮到音訊與視覺模態的一致性與互補性是以給定的文本查詢作為條件的,因此研究人員設計了TGCM單元建模文本-視覺-音頻三模態間的交互。
參考圖2(b),TGCM分為」提取「和」傳播「兩個步驟。
首先以文字作為查詢條件,從視覺和音訊兩種模態中提取關聯的資訊並整合;然後再以視覺與音訊各自模態作為查詢條件,將整合的資訊透過注意力傳播到視覺與音頻各自的模態,最終再透過FFN進行特徵融合。
3、課程學習最佳化策略
研究人員觀察到音訊中含有噪聲,這會影響多模態學習的效果,於是他們將噪音的強度作為樣本難度的參考,引入課程學習(Curriculum Learning,CL)對優化過程進行去噪,參考圖2(c)。
他們根據兩個分支的預測輸出差異來評估樣本的難度,認為過於難的樣本大概率表示其音頻含有過多的噪聲而不適於TSG任務,於是根據樣本難度的評估分數對訓練過程的損失函數項進行重加權,旨在丟棄音訊的雜訊所造成的不良梯度。
(其餘的模型結構與訓練細節請參考原文。)
多項測試新SOTA
研究人員在TSG任務的benchmark數據集Charades-STA和ActivityNet Captions上進行實驗評估,與baseline方法的比較如表1所示。
ADPN方法能夠取得SOTA性能;特別地,相較其他利用音頻的TSG工作PMI-LOC、UMT,ADPN方法從音頻模態獲取了更顯著地性能提升,說明了ADPN方法利用音頻模態促進TSG的優越性。

△表1:Charades-STA與ActivityNet Captions上實驗結果
研究人員進一步透過消融實驗展示了ADPN中不同的設計單元的有效性,如表2所示。

△表2:Charades-STA上消融實驗
研究人員選取了一些樣本的預測結果進行了可視化,並且繪製了TGCM中”擷取「步驟中的」文字to 視覺「(T→V)和」文字to 音訊「(T→A)注意力權重分佈,如圖3所示。
可以觀察到音訊模態的引入改善了預測結果。從「Person laughs at it」的案例中,可以看到T→A的注意力權重分佈更接近Ground Truth,修正了T→V的權重分佈對模型預測的錯誤引導。

△圖3:案例展示
總的來說,本文研究人員提出了一種新穎的自適應雙分支促進網路 (ADPN)來解決音訊增強的視訊片段定位(ATSG)問題。
他們設計了一個雙分支的模型結構,結合訓練視覺分支和視聽聯合分支,以解決音訊和視覺模態之間的資訊差異。
他們也提出了一個文字引導的線索挖掘單元(TGCM),用文字語意作為指導來建模文字-音訊-視覺互動。
最後,研究人員設計了一種基於課程學習的最佳化策略來進一步消除音訊噪音,以自感知的方式評估樣本難度作為噪音強度的度量,並自適應地調整優化過程。
他們首先在ATSG中深入研究了音訊的特性,並更好地提升了音訊模態對效能的提升作用。
未來,他們希望為ATSG建立更合適的評估基準,以鼓勵在這一領域進行更深入的研究。
論文連結:https://dl.acm.org/doi/pdf/10.1145/3581783.3612504
##庫倉庫連結:https://github.com/hlchen23 /ADPN-MM
以上是清華大學新方法成功定位精確影片片段! SOTA被超越且已開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 一個提示可以繞過每個主要LLM的保障措施Apr 25, 2025 am 11:16 AM
一個提示可以繞過每個主要LLM的保障措施Apr 25, 2025 am 11:16 AM隱藏者的開創性研究暴露了領先的大語言模型(LLM)的關鍵脆弱性。 他們的發現揭示了一種普遍的旁路技術,稱為“政策木偶”,能夠規避幾乎所有主要LLMS
 5個錯誤,大多數企業今年將犯有可持續性Apr 25, 2025 am 11:15 AM
5個錯誤,大多數企業今年將犯有可持續性Apr 25, 2025 am 11:15 AM對環境責任和減少廢物的推動正在從根本上改變企業的運作方式。 這種轉變會影響產品開發,製造過程,客戶關係,合作夥伴選擇以及採用新的
 H20芯片禁令震撼中國人工智能公司,但長期以來一直在為影響Apr 25, 2025 am 11:12 AM
H20芯片禁令震撼中國人工智能公司,但長期以來一直在為影響Apr 25, 2025 am 11:12 AM最近對先進AI硬件的限制突出了AI優勢的地緣政治競爭不斷升級,從而揭示了中國對外國半導體技術的依賴。 2024年,中國進口了價值3850億美元的半導體
 如果Openai購買Chrome,AI可能會統治瀏覽器戰爭Apr 25, 2025 am 11:11 AM
如果Openai購買Chrome,AI可能會統治瀏覽器戰爭Apr 25, 2025 am 11:11 AM從Google的Chrome剝奪了潛在的剝離,引發了科技行業中的激烈辯論。 OpenAI收購領先的瀏覽器,擁有65%的全球市場份額的前景提出了有關TH的未來的重大疑問
 AI如何解決零售媒體的痛苦Apr 25, 2025 am 11:10 AM
AI如何解決零售媒體的痛苦Apr 25, 2025 am 11:10 AM儘管總體廣告增長超過了零售媒體的增長,但仍在放緩。 這個成熟階段提出了挑戰,包括生態系統破碎,成本上升,測量問題和整合複雜性。 但是,人工智能
 'AI是我們,比我們更多'Apr 25, 2025 am 11:09 AM
'AI是我們,比我們更多'Apr 25, 2025 am 11:09 AM在一系列閃爍和惰性屏幕中,一個古老的無線電裂縫帶有靜態的裂紋。這堆易於破壞穩定的電子產品構成了“電子廢物之地”的核心,這是沉浸式展覽中的六個裝置之一,&qu&qu
 Google Cloud在下一個2025年對基礎架構變得更加認真Apr 25, 2025 am 11:08 AM
Google Cloud在下一個2025年對基礎架構變得更加認真Apr 25, 2025 am 11:08 AMGoogle Cloud的下一個2025:關注基礎架構,連通性和AI Google Cloud的下一個2025會議展示了許多進步,太多了,無法在此處詳細介紹。 有關特定公告的深入分析,請參閱我的文章
 IR的秘密支持者透露,Arcana的550萬美元的AI電影管道說話,Arcana的AI Meme,Ai Meme的550萬美元。Apr 25, 2025 am 11:07 AM
IR的秘密支持者透露,Arcana的550萬美元的AI電影管道說話,Arcana的AI Meme,Ai Meme的550萬美元。Apr 25, 2025 am 11:07 AM本週在AI和XR中:一波AI驅動的創造力正在通過從音樂發電到電影製作的媒體和娛樂中席捲。 讓我們潛入頭條新聞。 AI生成的內容的增長影響:技術顧問Shelly Palme


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

記事本++7.3.1
好用且免費的程式碼編輯器

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

