
大模型應用探索-企業知識管家

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-01-08 08:49:431440瀏覽

一、傳統知識管理的背景與挑戰
1、企業知識管理的必要性
在現代企業中,知識管理是一個至關重要的環節。它可以幫助企業有效地組織和利用內部和外部的知識資源,從而提升企業的效率和競爭力。為了更好地進行知識管理,許多企業引進了知識管家的概念。知識管家是一種專門負責管理和傳播企業知識的角色或系統。透過知識管家,企業可以更好地收集、整
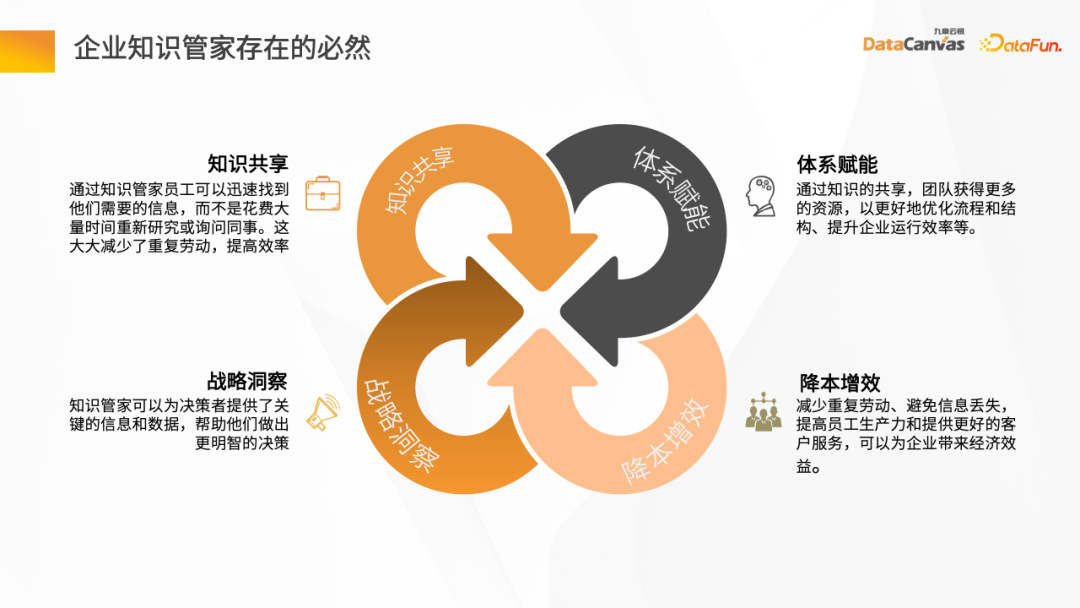
#隨著網路應用的快速發展和知識爆炸式增長,企業面臨一個共享知識的挑戰。如何實現企業內部知識的有效傳遞和分享已經成為一個重要議題。透過知識共享,企業不僅能提高工作效率,也能避免重複勞動。
另一種方式是透過採用知識共享的模式,建立一個能夠賦能企業的機制,以便更好地優化流程和結果,提高企業的運作效率。這種模式可以讓企業內部的員工分享他們的知識和經驗,讓團隊中的每個人都能從中受益。透過共享知識,企業可以避免重複勞動,減少錯誤和失誤,並且能夠更好地應對挑戰和變化。這
此外,身為知識管家,它還能夠為決策者提供關鍵的資訊和數據,以幫助他們做出更明智的決策。知識管家具備強大的資訊檢索和分析能力,能夠從大量的資料中提取出有用的信息,並進行整合和分析。這些資訊和數據可以包括市場趨勢、競爭對手分析、消費者洞察、技術發展等方面的
#另外,一個非常關鍵的因素是減少企業員工的工作負擔,防止資訊的遺失,並且提高員工的工作效率和客戶服務水平,從而實現降低成本、提高效率的目標。
2、企業知識管理挑戰
在沒有大模型之前,建構知識管家的邏輯是相當複雜的。通常情況下,我們會使用知識庫的概念,借助企業知識圖譜或企業內部的資料來建構知識庫。然而,在這個建構的過程中會面臨許多挑戰。 首先,知識庫的建構需要大量的人力和時間投入。收集、整理和歸納企業內部的知識和資訊是一項繁瑣而耗時的工作。需要專業的團隊來處理和管理這些數據,並確保其
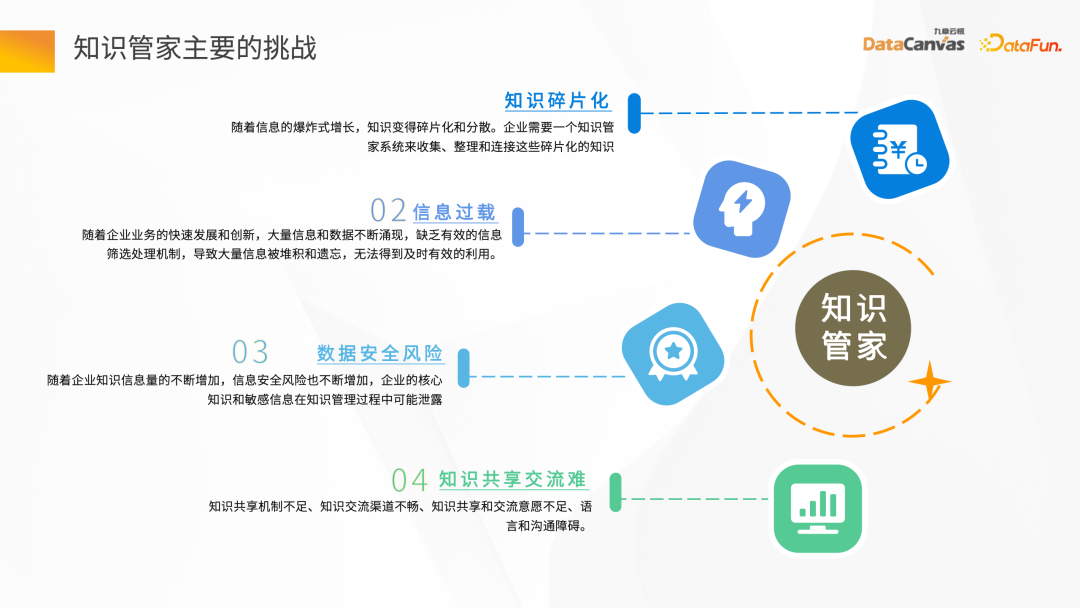
- 知識碎片化
知識片段化主要體現在兩個方面,一個面向是企業的資料非常分散,如OA 系統的資料有不同部門的、不同團隊的。另一方面,這些資料基本上都是以非結構化形式去提供的,例如 Word、PDF、圖片、影片等。在知識管家建設的過程中,如何把這些知識片段化的資訊快速集中,是面臨的第一個挑戰。
- 資訊過載
#在企業業務快速發展中,面臨大量資訊與數據在不斷湧現的情況下,如何在海量資料中建立篩選機制,確保資訊的準確、及時,也是一大挑戰。
- 資料安全風險
#企業一般不會把自己的私人資料共享給其他的機構或組織,一般都會比較重視企業私域資料的資料安全,因此也需要處理資料安全風險。
- 知識共享交流困難
#不同的公司有不同的組織結構,有些偏技術,有些偏業務,也有技術和業務混合型的,在業務和技術溝通的過程中,溝通不順暢是每個企業在知識共享中都會面臨的一個問題。
#
二、知識管家解決方案
1、企業知識管家是什麼
企業知識管家,類似一個人的大腦,去輔助整個知識的存儲,並理解和創造知識。
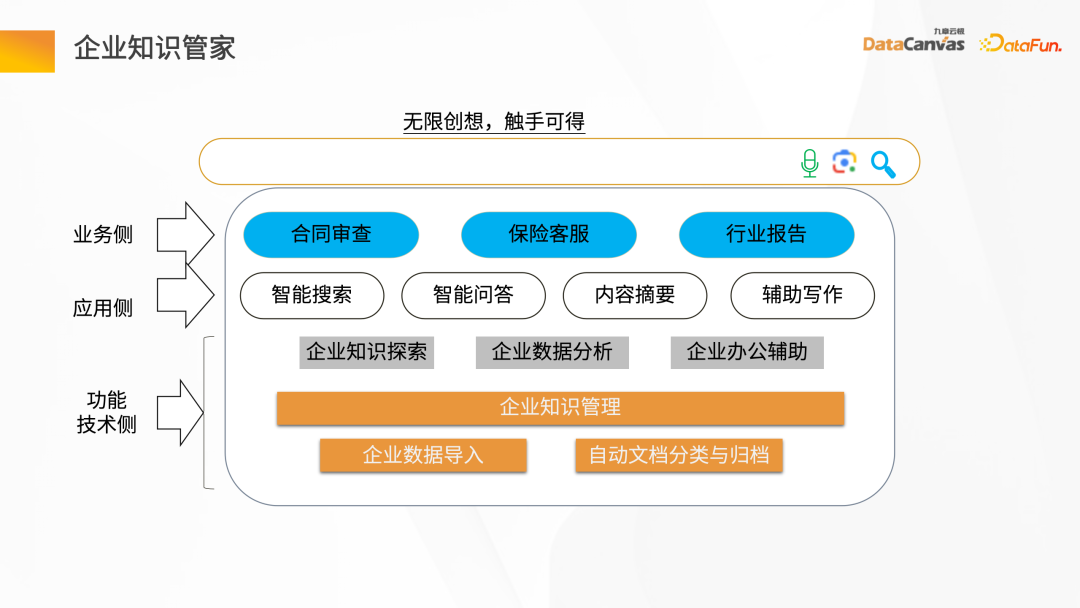
企業知識管家整體分為三個層次:第一層是功能技術面的需求,主要負責企業知識的管理,包括企業資料的導入、文件的自動分類與歸檔,以及其它一些基礎功能的需求;中間層是應用側的需求,包括提供一些智能問答、智能搜尋、摘要生成、輔助寫作等功能;上層是業務側的需求,包括合約的審查、保險的客服、行業報告的產生。
知識管家對外呈現的介面整體有三種模式:第一種介面類似文字方塊的方式,提供知識探索與分析;另一種是藉助於API 的Token,把不同應用場景所涉及的智慧Agent 發佈成API Token 的方式去和企業的業務系統整合;第三種方式是智慧Agent,透過對話模式去做知識的探索與分析。
2、企業知識管家解決方案
企業知識管家主要負責企業專屬的知識管理和創造,包括以下一些業務場景:

- 智慧問答
#結合企業自己的私域數據,經過向量化後,儲存在向量資料庫中,借助問答對模式去做智慧問答的場景,透過這些場景可以衍生出來很多更具化的業務需求。
- 自助文件分析
#透過文件去做一些探索和分析,例如對論文進行探索,可以提問這篇論文講的內容,還可以進行文件的自主分析,提供整個文件的分段預覽、上下文檢索、摘要總結等能力。
- 自訂角色場景
#結合企業內部不同角色的私域數據,再加上提示詞的模式,提供一些自訂場景的設計,如文件的輔助寫作、智慧會議紀要等。
- 合約審核
#採用人機對話的模式,對企業的各種合約做一些關鍵條款資訊的審查,查看對應資訊是否準確。
企業知識管家產品的主要功能包括:
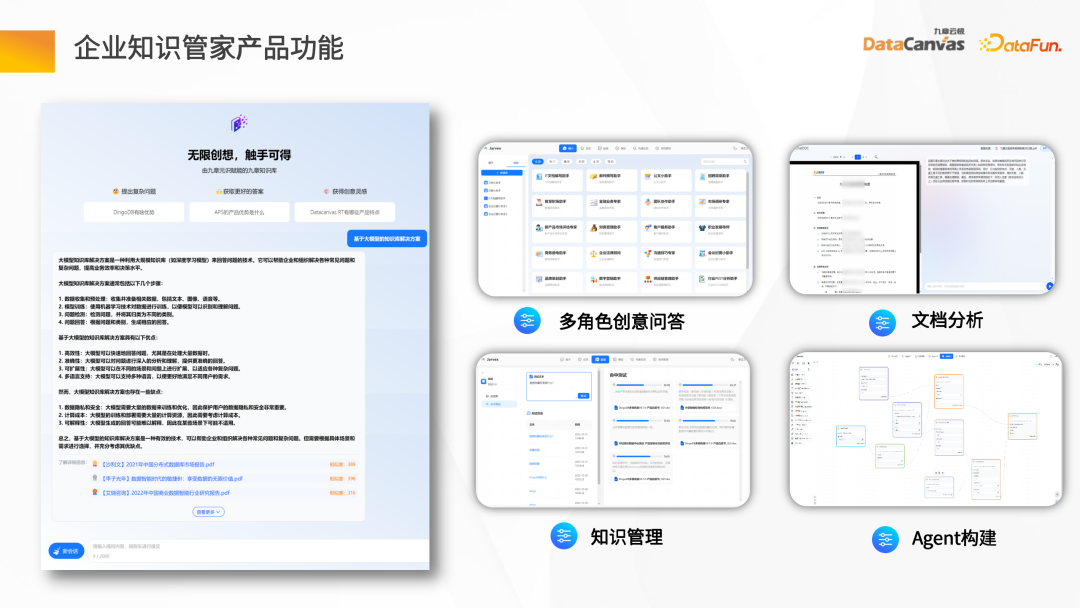
- 智慧問答:結合具體問題,透過檢索上下文得到一個有源可依的答案。
- 多角色創意問答:透過提示字與企業的私密資料來建立智慧應用場景。
- 文檔分析:匯入整個文檔,進行總結或探索分析。
- 知識管理:企業資料透過知識管家,進行全自動的管理,整個流程採用非常簡潔的模式。
- Agent 建置:開發平台,即大模型 IDE 功能。
知識管家的功能架構:
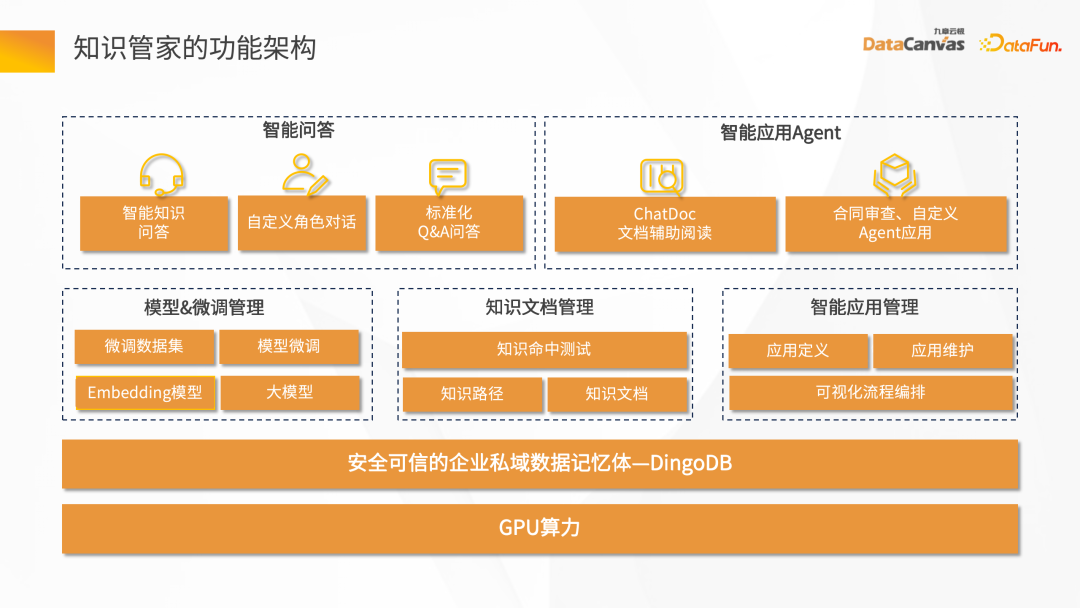
最下面是GPU 算力,包含兩類,一類是推理的算力,另一類是微調的算力。中間這一層是安全可信賴的企業私域資料記憶體-DingoDB多模向量資料庫。
再上一層整個技術層的功能點,包括模型微調的管理、知識文件管理、智慧應用管理。
最上面是偏業務場景類的需求,智慧問答裡可以自訂角色的一些對話、標準的QA 問答,還有智慧應用的Agent,基於文件的輔助閱讀、合約的審查、保險的個人助理。
三、知識管家核心技術探索
1、知識管家建構過程
接下來透過智慧問答場景來介紹整個知識管家的建置流程。
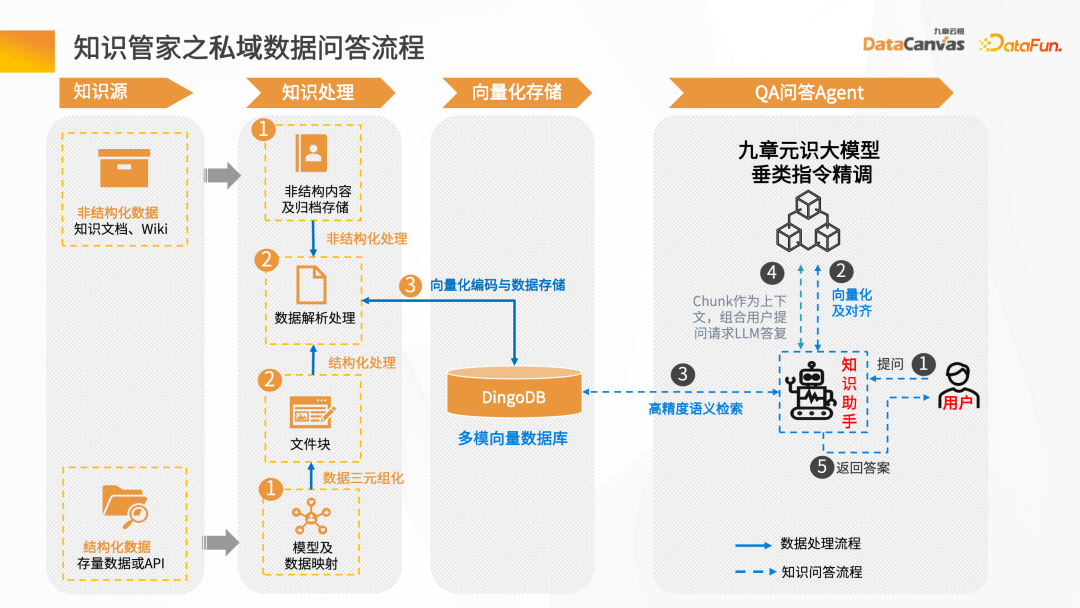
首先需要有資料來源,可能會有結構和非結構化數據,通常來說,知識庫的建構以非結構化數據為主,如Word、PDF、Excel,還有企業系統、Jira、知識管理平台等。
這些資料經過知識處理環節,轉換成向量存到資料庫。需要先把文檔加載進去,然後給予文檔的 Layout 信息或結構信息,做文檔向量解析生成文件塊,然後基於文件塊調用對應的 Embedding 模型轉換成向量,對向量進行存儲。
智慧問答互動的過程:在使用者提出問題後,首先借助智慧助理把問題向量化,再去資料庫做語意的檢索,得到關聯這個語意相近的文章上下文,透過上下文結合提示詞,經過大模型的推理,最後得到答案的回報。
整體流程是一個不斷迭代和回饋優化的過程,只有這樣才能得到基於企業私域資料上的專屬智慧專家角色。
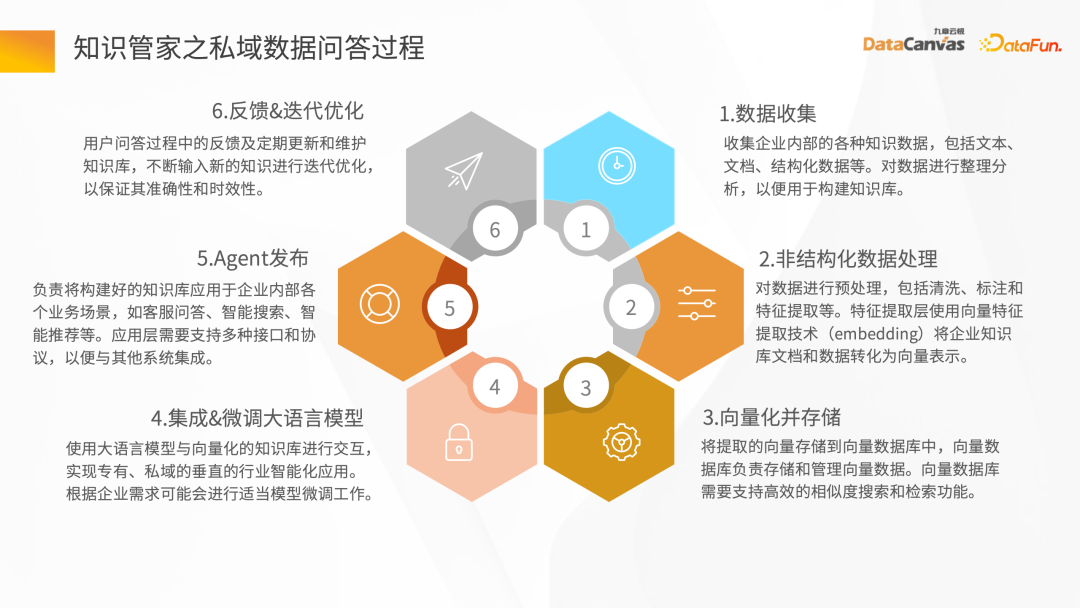
2、知識管家建構核心技術探索
- #非結構化資料處理
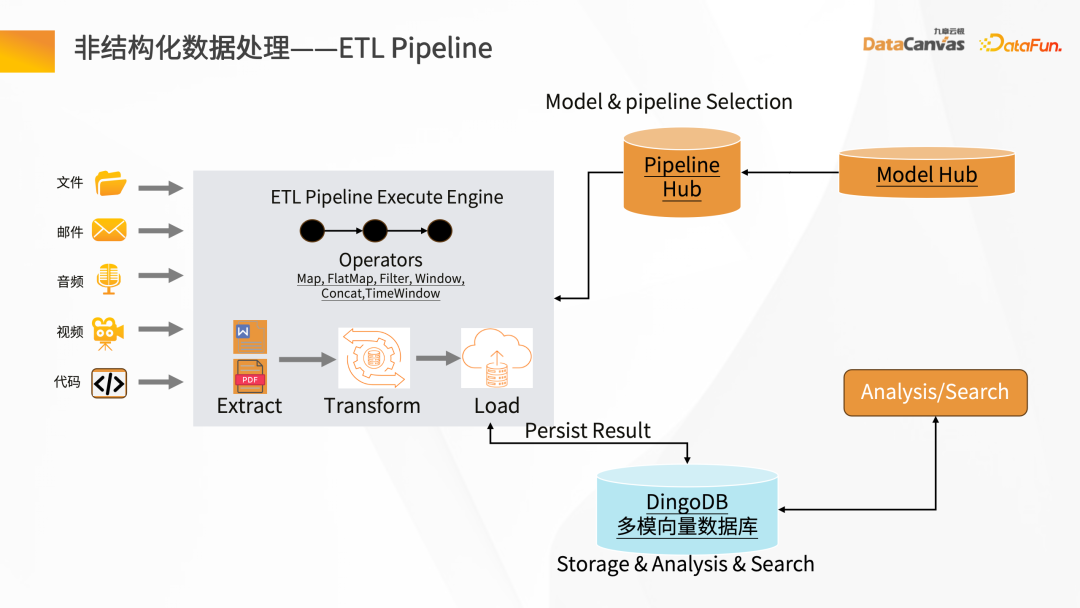
#非結構化資料ETL 處理過程,需要使用一些工具。知識管家從技術模式上提供了一些特殊的算子,這些算子可以清洗整個 Map、Filter、基於 Window的變化,透過整個 ETL 的 Pipeline 可以進行資料轉換。
透過各種檔案的解析器(如PDF 的解析器)進行解析,然後經過中間層對應的不同應用場景Hub 的Operator,可以快速建構Pipeline 的Hub,再經過資料的清洗和轉換後進行Embedding 化,最後存到向量資料庫。
- 精確度與完整性資料保證-無損耗資料解析
要得到一個好的模型調試效果,要確保精確和完整的數據,具備良好的數據處理的品質。
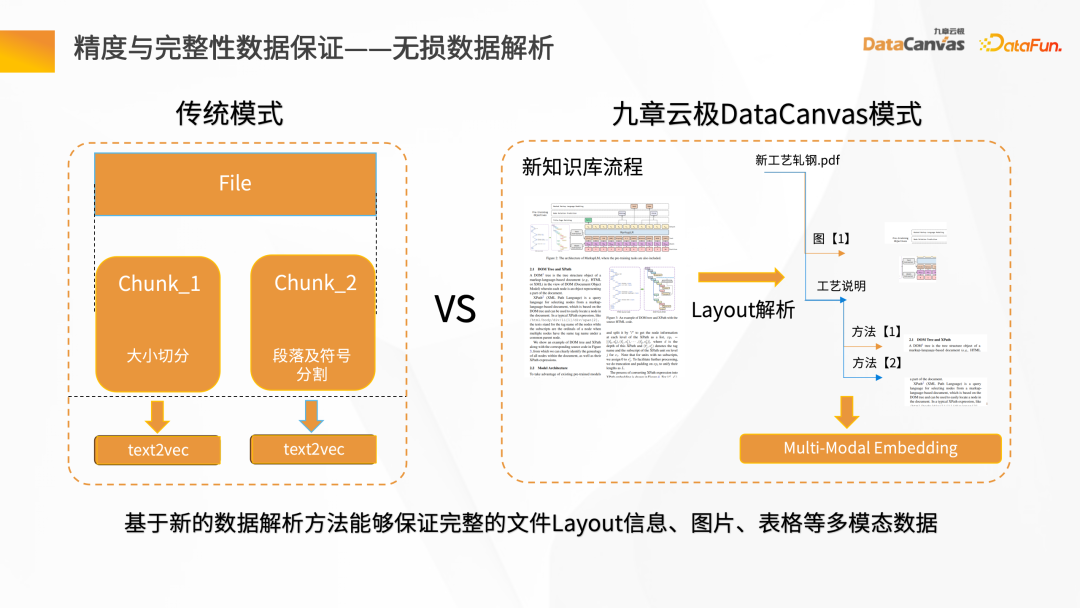
建立一個傳統的資料檢索非常簡單,但實際的知識比較複雜,除了文字本身的資訊外,還有圖片、表格數據、段落資訊等。對此,九章雲極DataCanvas提供了 Layout 的解析模式,可以實現 Layout 資訊、表格、圖片等多模態資料的全量存儲,全面提升了資料解析過程的品質。
- 強相關性檢索-Reranking 二次篩選
在文件經過向量化,存到DingoDB多模向量資料庫後,透過Query 進行檢索,在檢索結果中會包含檢索內容本身的結果,也會包含相關性的結果,這時候需要在檢索召回的Chunk 做Reranking 的二次篩選。
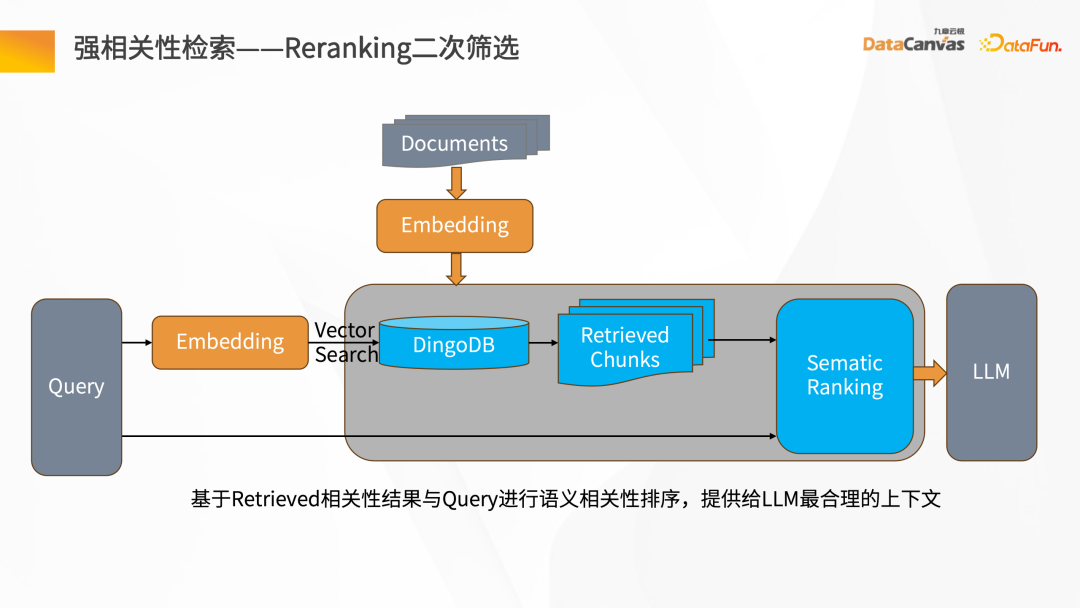
在Reranking 二次篩選時,要將Retrieval 的Chunk 和對應的Query 做相關性語義分析,包括找到語意最接近的匹配,然後把二次篩選後的檢索Chunk 重新推給大語言模型。
- 安全可信任的答案產生-多指令微調
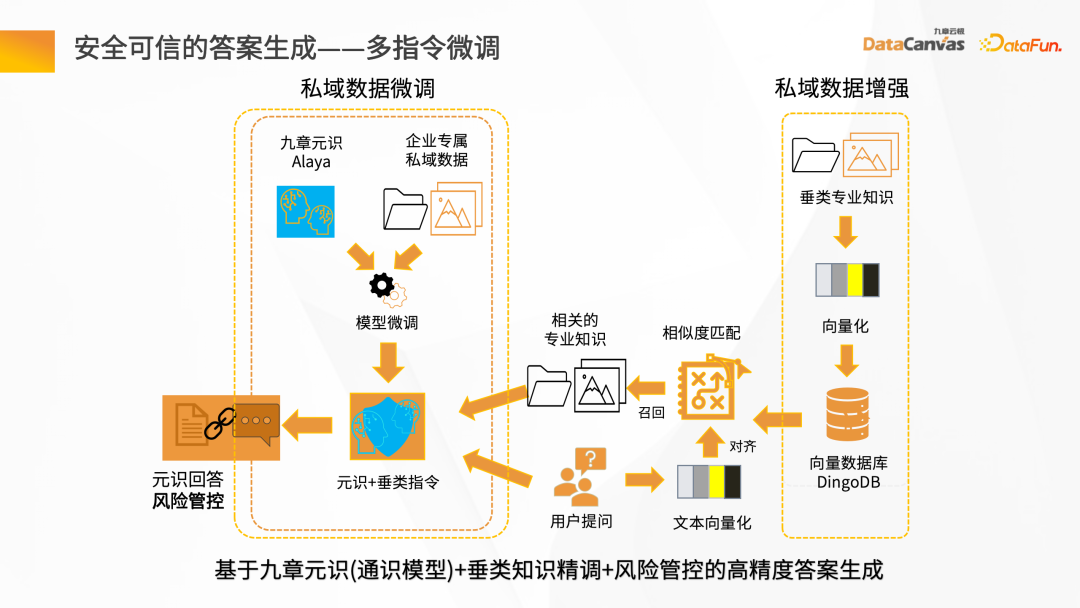
#為了確保答案產生過程的安全可信,九章雲極DataCanvas基於通用的大語音模型,對召回的數據做提示詞的限定,並結合企業的私域數據對大模型進行垂類知識的微調,再加上風向管控機制,從而確保答案生成的高精度。
- 儲存與檢索能力- DingoDB多模向量資料庫
DingoDB可以提供多樣化化的API 支援透過SQL 和Python 工具包去做資料查詢,也提供一體化的方式,實現結構化和非結構化的聯合查詢。針對即時性的場景,DingoDB提供了即時寫入即可查詢的能力,可以邊導入資料邊進行即時檢索。
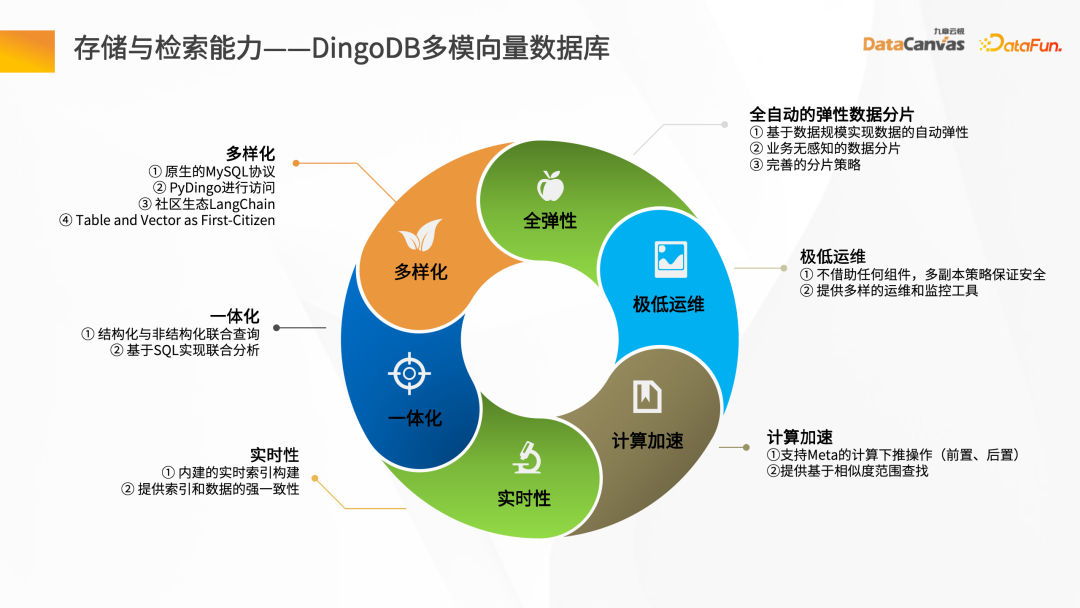
DingoDB也提供了運算加速的能力,支援Meta 的前置、後置的篩選篩選,以及基於相似度的範圍查找。 DingoDB也提供了多副本的工具,可以做部分的遷移和資料的遷移,同時提供多樣化的維運和監控工具,降低了維運成本。 DingoDB還能提供自動彈性分片的能力,可以把資料動態地平衡到不同機器上,實現各個節點的負載平衡。
- 安全可信任的專屬 LLM-微調 Pipeline
在企業私人資料上,針對通用的場景需要微調,以建構某個場景裡企業專屬的大語言模型。知識管家裡總結了整個微調過程中的痛點,在產品裡提供工具化的方式,上傳文件就可以得到所有問題的資料。有了數據後,直接在介面上透過配置參數就可以微調,同時產品也提供了一些微調數據指標,可以對微調的結果進行評估。

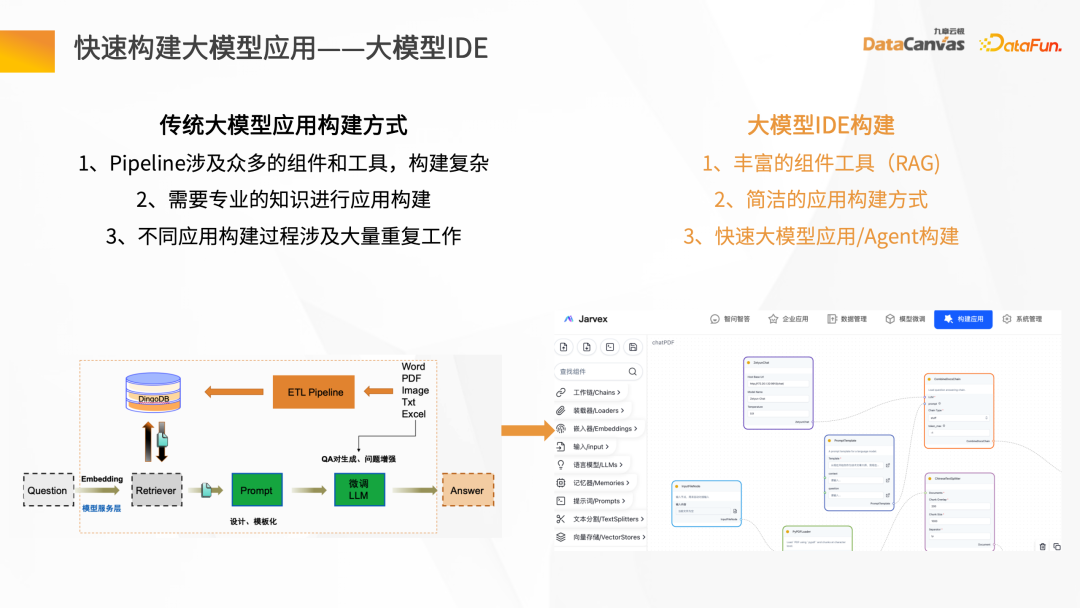
- 快速建立大模型應用-大模型 IDE
傳統大模型應用往往構建複雜,知識管家基於九章雲極DataCanvas自己的FS 能力,構建了自己的大模型IDE,能夠提供豐富的組件和工具,通過簡潔的應用構建方式,把構建的模版發布成智慧應用的Agent。
#四、總結與展望
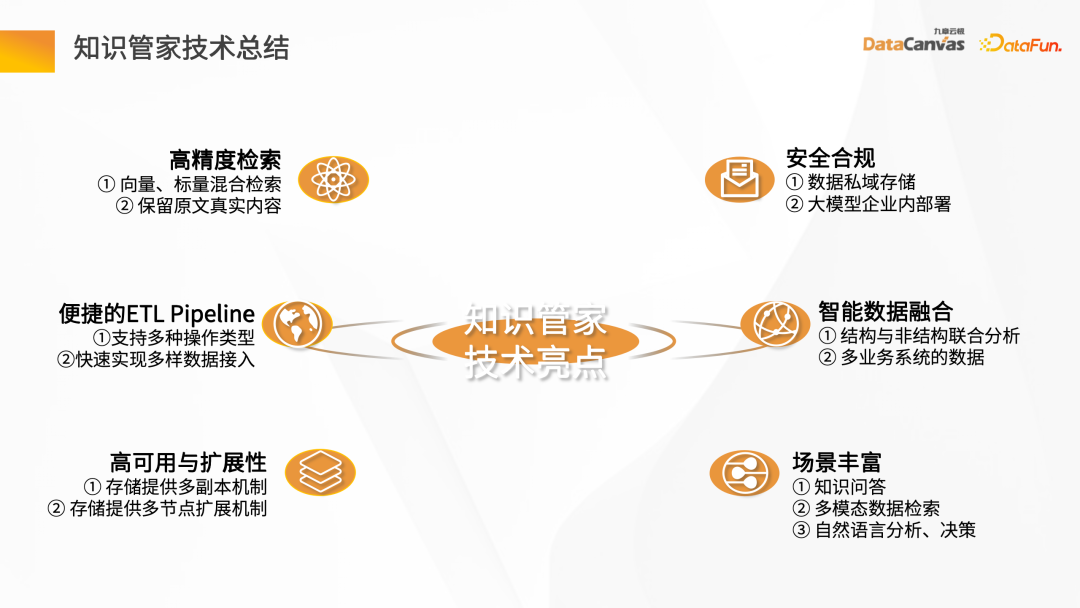
1、知識管家方案總結
知識管家的技術亮點主要有以下六大面向:高精度檢索、便捷的ETL Pipeline、高可用與擴展性、安全合規、智慧數據融合以及豐富的場景。
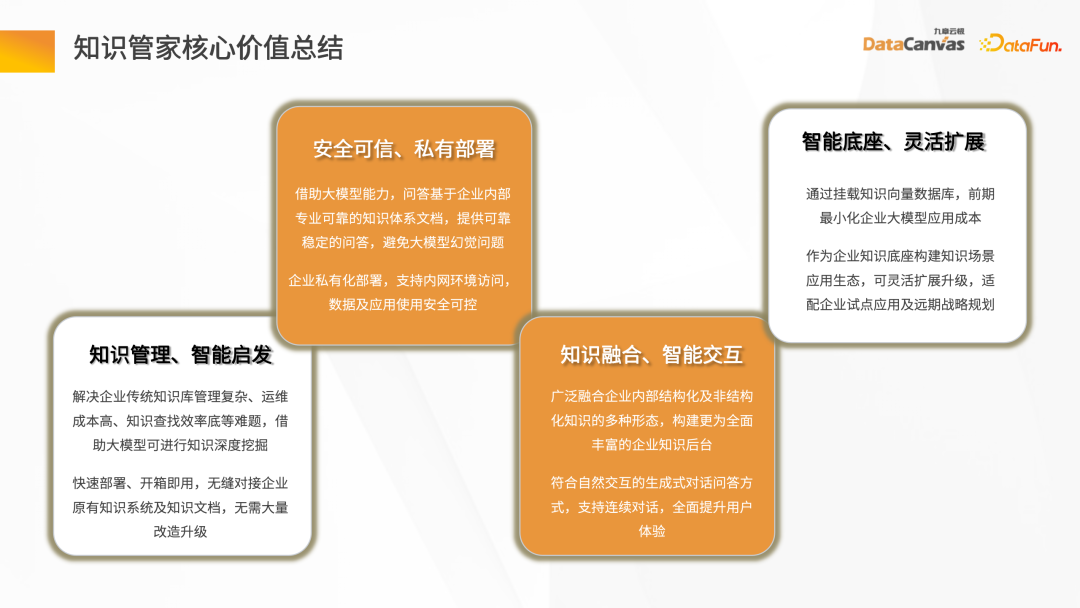
知識管家的核心價值包括:提供了知識管理和智慧啟發的基礎能力,並且提供了一個安全可信的應用私有化部署方式,包含企業的所有數據,可實現知識的整合和智慧互動。作為智慧底座,提供靈活擴展的能力,可以在知識管家上基於大模型做新的 Agent 開發。
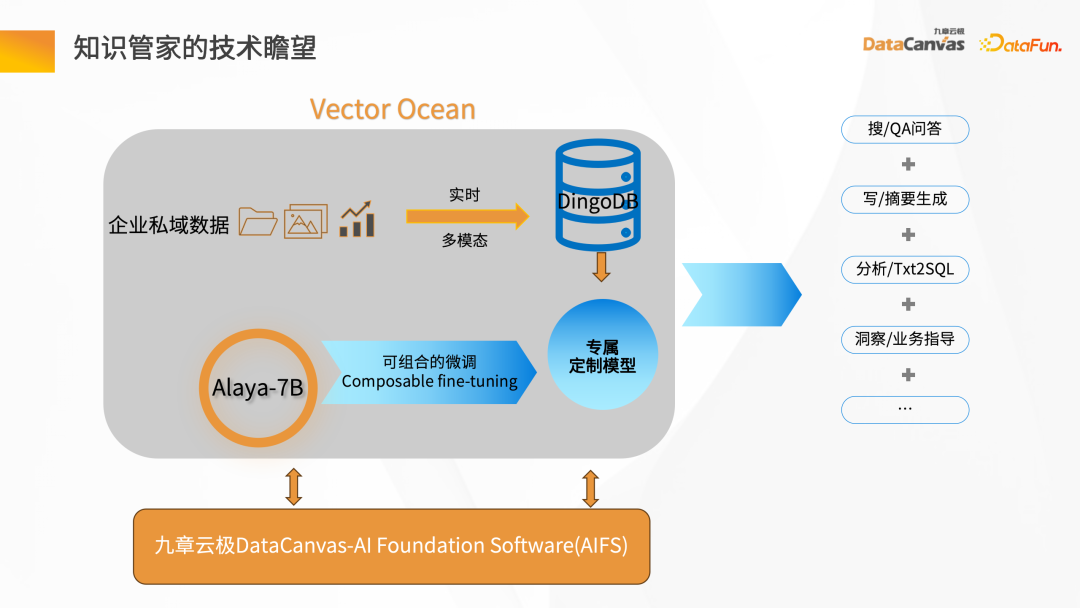
2、未來展望
知識管家是基於九章雲極DataCanvas的AIFS,提供從裸金屬到上面的GPU 算力以及模型的調度,並實現模型微調的一整套Pipeline 模式。它藉助通識的大語言模型,加上企業的私域數據,進行組合微調,形成企業自己專屬的大語言模型。基於大語言模型的擴展能力,結合 DingoDB多模向量資料庫,可以實現企業裡面的搜尋問答、摘要產生等應用,進行企業的知識管理。
以上是大模型應用探索-企業知識管家的詳細內容。更多資訊請關注PHP中文網其他相關文章!