
高情商的NPC來了,剛伸出手,它就做好了要配合下一步動作的準備

- 王林轉載
- 2024-01-07 10:58:38563瀏覽
在虛擬實境、擴增實境、遊戲和人機互動等領域,經常需要讓虛擬人物和螢幕外的玩家互動。這種互動是即時的,要求虛擬人物根據操作者的動作進行動態調整。有些互動也涉及物體,例如和和虛擬人物一起搬動一張椅子,這需要特別注意操作者手部的精確動作。智慧、可互動的虛擬人物的出現,將大大提升人類玩家與虛擬人物的社交體驗,帶來全新的娛樂方式。
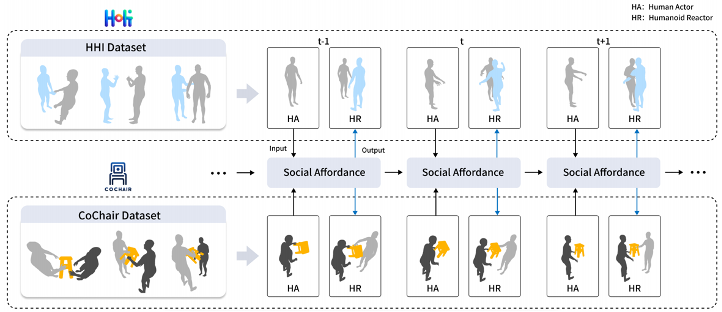
在該研究中,作者專注於人與虛擬人的互動任務,特別是涉及物體的互動任務,提出了一項名為在線全身動作反應合成的新任務。新任務將基於人類的動作產生虛擬人的反應。過去的研究主要關注人與人的互動,不考慮任務中的物體,生成的身體反應也沒有手部動作。此外,以往工作也沒有將任務視為線上的推理,在實際情況中虛擬人根據實施情況對下一步進行預判。
為了支持新任務,作者首先建立了兩個資料集,分別命名為 HHI 和 CoChair,並提出了一個統一的方法。具體來說,作者首先建立了社交可供性表示。為了做到這一點,他們選擇了一個社交可供性載體,再使用 SE (3) 等變神經網路為此載體學習局部座標系,最後將其社交可供性規範化。此外,作者還提出了一種社交可供性預測的方案,使虛擬人能夠基於預測進行決策。
研究結果表明,該方法在HHI和CoChair資料集上能夠有效產生高品質的反應動作,並且在一塊A100上能夠實現每秒25幀的即時推理速度。此外,作者也透過對現有的人類互動資料集Interhuman和Chi3D的驗證,證明了該方法的有效性。

#請參考以下論文地址以獲取更詳細的信息:[https://arxiv.org/pdf/2312.08983.pdf]。希望這對還在尋找解謎方法的玩家們有所幫助。
請造訪專案首頁https://yunzeliu.github.io/iHuman/,以取得更多關於解謎方法的資訊。
資料集建構
本文中,作者建立了兩個資料集來支援線上全身動作反應合成任務。其中一個是雙人互動的資料集HHI,另一個是雙人與物件互動的資料集CoChair。這兩個資料集為研究者提供了寶貴的資源,可用於進一步探索全身動作合成領域。 HHI資料集記錄了雙人之間的各種互動動作,而CoChair資料集則記錄了雙人與物件之間的互動動作。這些資料集的建立為研究者提供了更多的實驗
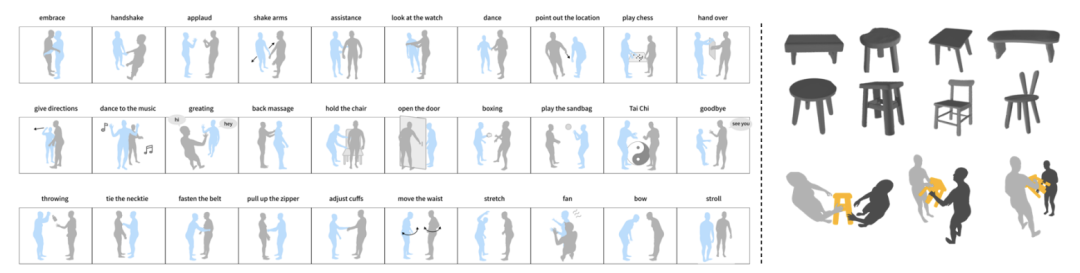
#HHI 資料集是一個大規模的全身動作反應資料集,包含30 個互動類別、10 對人體骨骼類型和總共5000 個互動序列。
HHI 資料集有三個特點。第一個特點是包含多人全身互動,包括身體和手部互動。作者認為在多人互動中,手部的互動無法忽視,在握手、擁抱和交接過程中,都透過手部傳遞豐富的訊息。第二個特點是 HHI 資料集可以區分明確的行為發起者和反應者。例如,在握手、指向方向、問候、交接等情況下,HHI 資料集可以確定動作的發起者,這有助於研究者更好地定義和評估這個問題。第三個特點是 HHI 資料集包含的互動和反應的類型更豐富多樣,不僅包括兩個人之間 30 種類型互動,還提供了針對同一行動者的多個合理反應。例如,當有人向你打招呼時,你可以點頭回應,用一隻手回應,或雙手回應。這也是一種自然的特徵,但以前的資料集很少關注到這一點並進行討論。
CoChair 是一個大規模的多人和物件互動資料集,其中包括 8 個不同的椅子,5 種互動模式和 10 對不同的骨架,總共 3000 個序列。 CoChair 有兩個重要的特點:其一,CoChair 在協作過程中存在資訊不對稱。每一個行動都有一個(知道攜帶物的目的地的)執行者 / 發起者和一個(不知道目的地的)反應者。其二,它具有多樣的攜帶模式。資料集包括五種攜帶模式:單手固定攜帶、單手移動攜帶、雙手固定攜帶、雙手移動攜帶和雙手靈活攜帶。
方法
#社交可供性載體指編碼社交可供性訊息的物件或人。當人類與虛擬人互動時,人類通常直接或間接地與虛擬人接觸。而當涉及物體時,人類通常會接觸物體。
為了模擬互動中的直接或潛在接觸訊息,需要選擇一個載體來同時表徵人類、載體本身以及它們之間的關係。在該研究中,載體指人類可能接觸的物體或虛擬人類模板。
基於此,作者定義了以載體為中心的社交可供性表示。具體而言,給定一個載體,研究者對人類行為進行編碼,以獲得密集的人 - 載體聯合表示。基於這一表示,作者提出了一種社交可供性表示,其中包含人類行為的動作、載體的動態幾何特徵以及每個時間步驟中的人 - 載體關係。
需要注意的是,社交可供性表示指的是從開始時刻到特定時間步驟的資料流,而不是單幀的表示。這種方法的優點在於將載體的局部區域與人類的行為運動密切關聯了起來,形成了便於網路學習的表示。
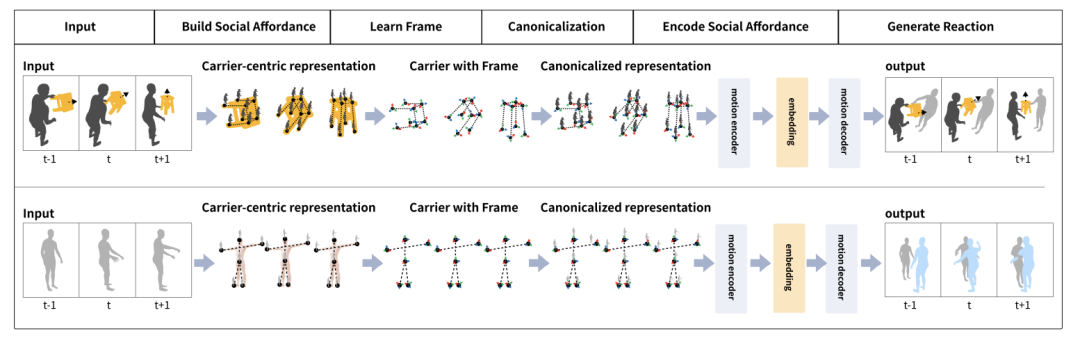
透過社交可供性表示,作者進一步採用社交可供性規範化來簡化表達空間。第一步是學習載體的局部框架。透過 SE (3) 等變網絡,學習得到載體的局部座標系。具體來說,首先將人類的動作轉化為每個局部座標系的動作。接下來,作者從每個點的視角對人類角色的動作進行密集編碼,以獲得一個密集的以載體為中心的動作表示。這可以被視為將一個 「觀察者」 綁定到載體上的每個局部點上,每個 「觀察者」 都從第一人稱視角對人類的動作進行編碼。這種方法的優點在於對人類,虛擬人以及物體之間的接觸產生的資訊進行建模的同時,社交可供性規範化簡化了社交可供性的分佈,並促進了網路學習。
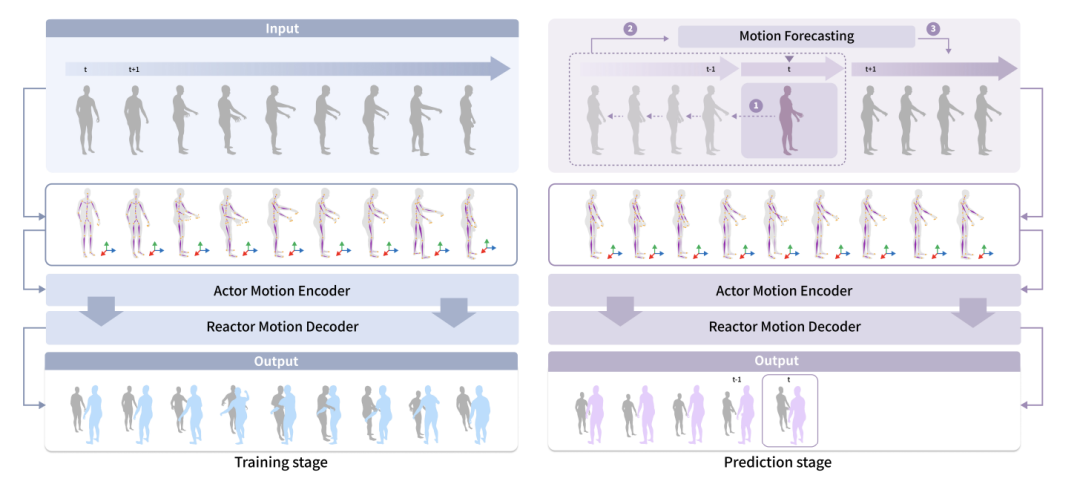
為了預測和虛擬人互動的人類的行為,作者提出了社交可供性預測模組。在真實情況下,虛擬人只能觀察到人類行為的歷史動態。而作者認為虛擬人應該具備預測人類行為的能力,以便更好地規劃自己的動作。例如,當有人抬手並向你走過來時,你可能會認為他們要與你握手,並做好迎接握手的準備。
在訓練階段,虛擬人可以觀察到人類的所有動作。在真實世界的預測階段,虛擬人只能觀察到人類行為的過去動態。而提出的預測模組可以預測人類將要採取的動作,以提高虛擬人的感知能力。作者使用一個運動預測模組來預測人類行為者的動作和物體的動作。雙人互動中,作者使用了 HumanMAC 作為預測模組。在雙人與物體互動中,作者基於 InterDiff 建立了運動預測模組,並添加了一個先驗條件,即人 - 物接觸是穩定的,以簡化對物體運動的預測難度。
實驗
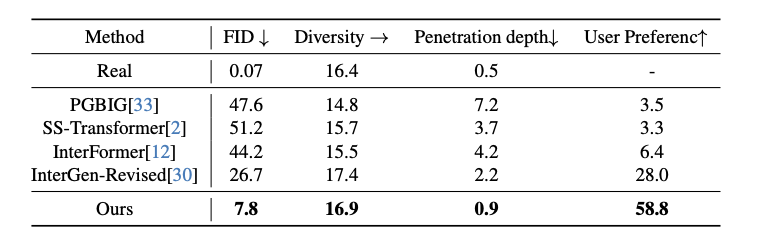
定量测试可以看出该研究的方法在所有度量指标上都优于现有方法。为了验证方法中每个设计的有效性,作者在 HHI 数据集上进行了消融实验。可以看出,没有社交可供性规范化时,该方法的表现显著下降。这表明使用社交可供性规范化来简化特征空间复杂性是必要的。没有社交可供性预测,文中的方法失去了预测人类行为者动作的能力,导致了性能下降。为了验证使用局部坐标系的必要性,作者还比较了使用全局坐标系的效果,可以看出局部坐标系显著更好。这也表明使用局部坐标系描述局部几何和潜在接触是有价值的。
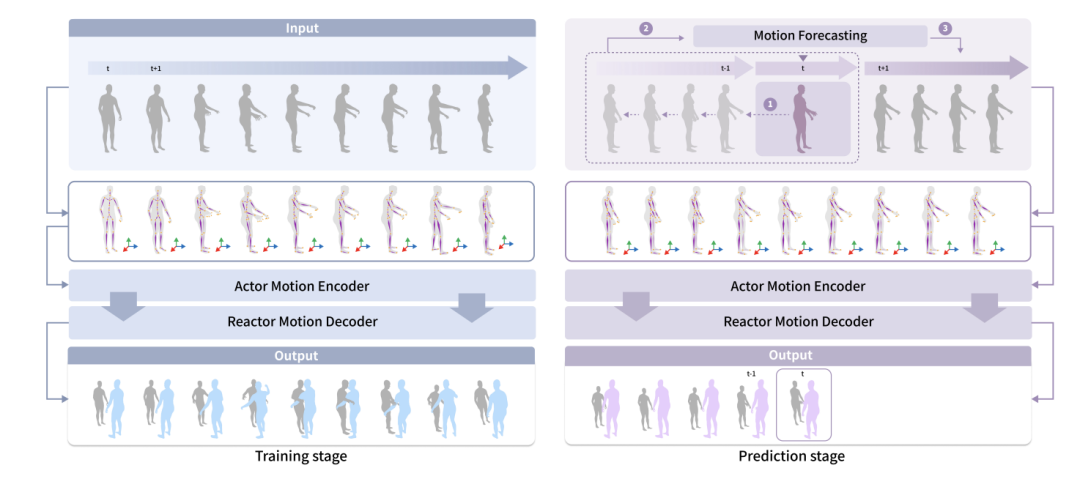
从可视化结果可以看到,与以往相比,使用文中方法训练过的虚拟人物的反应更快,并且能够更好地捕捉到局部的手势,在协作中生成更逼真和自然的抓取动作。
更多研究细节,可参见原论文。
以上是高情商的NPC來了,剛伸出手,它就做好了要配合下一步動作的準備的詳細內容。更多資訊請關注PHP中文網其他相關文章!