
全力邁向閉環! DriveMLM:將LLM與自動駕駛行為規劃完美結合!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-01-05 09:50:191360瀏覽
寫在前面&筆者的個人理解
大型語言模型為智慧駕駛開闢了新的格局,賦予了他們類似人類的思維和認知能力。本文深入研究了大型語言模型(LLM)在自動駕駛(AD)中的潛力。進而提出了DriveMLM,這是一種基於LLM的AD框架,可在模擬環境中實現閉環自動駕駛。具體來說有以下幾點:
- (1)本文透過根據現成的運動規劃模組標準化決策狀態,彌合語言決策和車輛控制命令之間的差距;
- (2)使用多模態LLM(MLLM)對模組AD系統的行為規劃模組進行建模,該模組AD系統使用駕駛規則、使用者命令和來自各種感測器(如相機、雷射雷達)的輸入作為輸入,並做出駕駛決策並提供解釋;該模型可以插入現有的AD系統(如Apollo)用於閉環駕駛;
- (3)設計了一個有效的數據引擎來收集數據集,該數據集合包括決策狀態和相應的可解釋標註,用於模型訓練和評估。
最後我們對DriveMLM進行了廣泛的實驗,結果表明,DriveMLM在CARLA Town05 Long上獲得了76.1的駕駛分數,並在相同設定下超過阿波羅基線4.7分,證明了DriveMLM的有效性。我們希望這項工作可以作為LLM自動駕駛的基線。
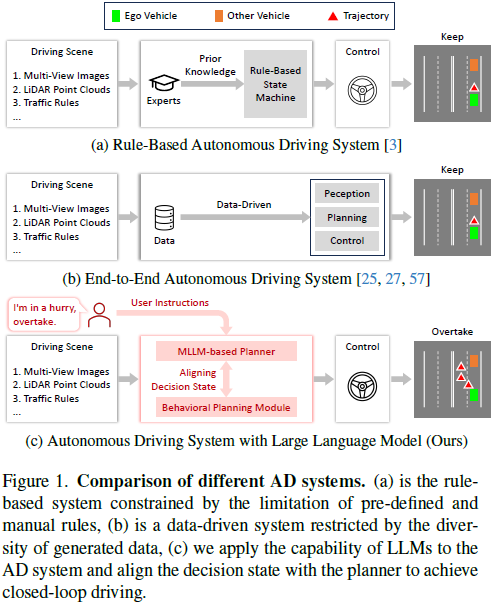
DriveMLM的相關介紹
#近年來,自動駕駛(AD)取得了重大進展,如圖1b所示從傳統的基於規則的系統發展到資料驅動的端對端系統,傳統的規則系統依賴由先驗知識提供的預定義規則集(見圖1a)。儘管這些系統取得了進步,但由於專家知識的限製或訓練資料的多樣性,它們還是遇到了限制。這使得他們很難處理角落情況,儘管人類駕駛員可能會發現處理這些情況很直觀。與這些傳統的基於規則或資料驅動的AD規劃者相比,使用網路規模的文字語料庫訓練的大型語言模型(LLM)具有廣泛的世界知識、穩健的邏輯推理和先進的認知能力。這些功能將他們定位為AD系統中的潛在規劃者,為自動駕駛提供了類似人類的方法。
最近的一些研究已將LLM整合到AD系統中,重點是針對駕駛場景產生基於語言的決策。然而,當涉及在真實世界環境或真實模擬中執行閉環駕駛時,這些方法具有局限性。這是因為LLM的輸出主要是語言和概念,不能用於車輛控制。在傳統的模組化AD系統中,高層次策略目標和低階控制行為之間的差距透過行為規劃模組連接,該模組的決策狀態可以透過後續運動規劃和控制輕鬆轉換為車輛控制訊號。這促使我們將LLM與行為規劃模組的決策狀態對齊,並透過使用對齊的LLM進行行為規劃,進一步設計一個基於LLM的閉環AD系統,該系統可以在真實世界的環境或現實的模擬環境上運行。
基於這一點,我們提出了DriveMLM,這是第一個基於LLM的AD框架,可以在現實模擬環境中實現閉環自動駕駛。為了實現這一點,我們有三個關鍵設計:(1)我們研究了Apollo系統的行為規劃模組的決策狀態,並將其轉化為LLM可以輕鬆處理的形式。 (2)開發了一種多模態LLM(MLLM)規劃器,該規劃器可以接受當前的多模態輸入,包括多視圖圖像、雷射雷達點雲、交通規則、系統訊息和用戶指令,並預測決策狀態;(3)為了獲得足夠的行為規劃-狀態對齊的訓練數據,我們在CARLA上手動收集280小時的駕駛數據,並透過高效的數據引擎將其轉換為決策狀態和相應的解釋註釋。透過這些設計,我們可以獲得一種MLLM planner,該規劃器可以根據駕駛場景和使用者需求進行決策,並且其決策可以輕鬆轉換為車輛控制訊號,用於閉環駕駛。
DriveMLM有以下優勢:(1)得益於一致的決策狀態,DriveMLM可以輕鬆地與現有的模組化AD系統(如Apollo)集成,以實現閉環駕駛,而無需任何重大更改或修改。 (2)透過將語言指令作為輸入,我們的模型可以處理使用者需求(例如,超越汽車)和高階系統訊息(例如,定義基本駕駛邏輯)。這使DriveMLM更加靈活,能夠適應不同的駕駛情況和彎道情況。 (3)它可以提供可解釋性並解釋不同的決策。這增強了我們模型的透明度和可信度,因為它可以向使用者解釋其行為和選擇。
總結來說,DriveMLM的主要貢獻如下:
- 提出了一個基於LLM的AD框架,透過將LLM的輸出與行為規劃模組的決策狀態相一致,彌合LLM和閉環駕駛之間的差距。
- 為了實現這個框架,我們用LLM可以輕鬆處理的形式自訂了一組決策狀態,設計了一個用於決策預測的MLLM規劃器,並開發了一個資料引擎,該引擎可以有效地產生決策狀態和相應的解釋註釋,用於模型訓練和評估。
- 為了驗證DriveMLM的有效性,我們不僅根據閉環駕駛指標(包括駕駛分數(DS)和每次幹預里程(MPI))來評估我們的方法,還使用理解指標(包括準確性、決策狀態的F1指標、決策解釋的BLEU-4、CIDEr和METEOR)來評估模型的駕駛理解能力。值得注意的是,我們的方法在CARLA Town05 Long上獲得了76.1 DS、0.955 MPI結果,這是4.7分,是Apollo的1.25倍。此外,我們可以透過用語言指令描述特殊要求來改變MLLM規劃者的決策,如圖2所示,例如為救護車或交通規則讓路

DriveMLM方法詳細介紹
概覽
#DriveMLM框架將大型語言模型(LLM)的世界知識和推理能力整合到自動駕駛中( AD)系統中,在逼真的模擬環境中實現閉環駕駛。如圖3所示,該框架有三個關鍵設計:(1)行為規劃狀態對齊。這一部分將LLM的語言決策輸出與Apollo等成熟的模組化AD系統的行為規劃模組一致。這樣,LLM的輸出可以輕鬆地轉換為車輛控制訊號。 (2)MLLM 規劃器。它是多模態標記器和多模態LLM(MLLM)解碼器的組合。多模態標記器將不同的輸入(如多視圖影像、雷射雷達、流量規則和使用者需求)轉換為統一的標記,MLLM解碼器基於統一的標記進行決策。 (3)高效率的資料收集策略。它為基於LLM的自動駕駛引入了一種量身定制的數據收集方法,確保了一個全面的數據集,包括決策狀態、決策解釋和用戶命令。
在推理過程中,DriveMLM框架利用多模態資料來做駕駛決策。這些資料包括:環視圖像和點雲。系統訊息是任務定義、流量規則和決策狀態定義的集合。這些令牌被輸入到MLLM解碼器,MLLM解碼器產生決策狀態令牌以及相應的解釋。最後,決策狀態被輸入到運動規劃和控制模組。此模組計算車輛控制的最終軌跡。
Behavioral Planning States Alignment
將大型語言模型(LLM)的語言選擇轉換為可操作的控制訊號對於車輛控制至關重要。為了實現這一點,我們將LLM的輸出與流行的阿波羅系統中的行為規劃模組的決策階段一致。根據常見方式,我們將決策過程分為兩類:速度決策和路徑決策。具體而言,速度決策狀態包括(維持、加速、減速、停止),而路徑決策狀態包括(FOLLOW、LEFT CHANGE、RIGHT CHANGE,LEFT BORROW、RIGHT BORROW)。
為了使語言模型能夠在這些狀態之間做出精確的預測,我們在語言描述和決策狀態之間建立了全面的聯繫,如表1的系統資訊所示。此相關性用作系統訊息的一部分,並整合到MLLM計劃器中。因此,一旦LLM描述了某些情況,預測將在決策空間內收斂為清晰的決策。每次,一個速度決策和一個路徑決策被相互推論並傳送到運動規劃框架。在補充資料中可以找到決策狀態的更詳細定義。

MLLM Planner
#DriveMLM的MLLM規劃器由兩個元件組成:多模態標記器和MLLM解碼器。這兩個模組密切協作,處理各種輸入,以準確地確定駕駛決策並為這些決策提供解釋。
多模態標記器。此tokenizer設計用於有效處理各種形式的輸入:對於時序環視圖像:使用時間QFormer來處理從時間戳−T到0(當前時間戳記)的環視圖像。對於雷射雷達數據,我們首先輸入點雲作為稀疏金字塔Transformer(SPT)主幹的輸入,以提取雷射雷達特徵。對於系統訊息和使用者指令,我們只需將它們視為普通文字數據,並使用LLM的令牌嵌入層來提取它們的嵌入。
MLLM解碼器。解碼器是將標記化輸入轉換為決策狀態和決策解釋的核心。為此,我們為基於LLM的AD設計了一個系統訊息模板,如表1所示。可以看到,系統訊息包含AD任務的描述、流量規則、決策狀態的定義,以及指示每個模態資訊合併位置的佔位符。這種方法確保了來自各種模態和來源的投入無縫整合。
輸出被格式化以提供決策狀態(見表1的Q2)和決策解釋(見表一的Q3),從而在決策過程中提供透明度和清晰度。關於監督方法,我們的框架遵循常見做法,在下一個令牌預測中使用交叉熵損失。透過這種方式,MLLM規劃者可以對來自不同感測器和來源的數據進行詳細的理解和處理,並將其轉化為適當的決策和解釋。
Efficient Data Engine
我們提出了一個資料產生範式,可以在CARLA模擬器中從各種場景建立決策狀態和解釋註解。該管道可以解決現有駕駛數據的局限性,這些數據缺乏訓練基於LLM的AD系統的決策狀態和詳細解釋。我們的管道由兩個主要組件組成:資料收集和資料註釋。
資料收集旨在提高決策的多樣性,同時保持現實。首先,在模擬環境中建構各種具有挑戰性的場景。安全駕駛需要複雜的駕駛行為。然後,專家,無論是經驗豐富的人類司機還是特工,都被要求安全地駕駛通過這些場景,這些場景是在其眾多可通行的地點之一觸發的。值得注意的是,當專家隨機提出駕駛需求並相應地駕駛時,會產生互動數據。一旦專家安全地開車到達目的地,就會記錄資料。
資料標註主要著重於決策和解釋。首先,透過使用手工製定的規則,根據專家的駕駛軌跡自動註釋速度和路徑決策狀態。其次,解釋標註首先基於場景生成,由附近的當前元素動態定義。第三,生成的解釋標註由人工標註進行細化,並透過GPT-3.5擴展其多樣性。此外,互動內容也由人工註釋器進行細化,包括執行或拒絕人工請求的情況。透過這種方式,我們避免了昂貴的逐幀決策狀態標註,以及昂貴的從頭開始手動編寫解釋標註,大大加快了我們的資料標註過程。
實驗
資料分析
#我們收集了280小時的駕駛資料進行訓練。這些數據包括50公里的路線,在CARLA的8張地圖(Town01、Town02、Town03、Town04、Town06、Town07、Town10HD、Town12)上收集了30種不同天氣和照明條件的駕駛場景。平均而言,每個場景在每個地圖上有大約200個觸發點要隨機觸發。每種情況都是駕駛中常見或罕見的安全關鍵情況。這些場景的詳細資訊請參閱補充說明。對於每一幀,我們收集來自前、後、左、右四個攝影機的影像,以及來自添加在ego車輛中心的雷射雷達感測器的點雲。我們收集的所有數據都有相應的解釋和準確的決策,這些解釋和決策成功地推動了場景的發展。
表2展示了與先前為使用自然語言進行駕駛理解而設計的資料集的比較。我們的數據有兩個獨特的特點。第一個是行為規劃狀態的一致性。這使我們能夠將MLLM規劃器的輸出轉換為控制訊號,以便我們的框架能夠在閉環駕駛中控制車輛。二是人際互動標註。它的特點是人類給予的自然語言指令以及相應的決定和解釋。目標是提高理解人類指令並做出相應反應的能力。
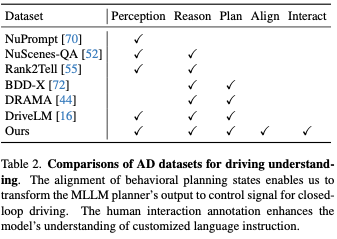
閉環自動駕駛評測
#我們在CARLA評估閉環駕駛,CARLA是公開可用的最廣泛使用和最現實的模擬基準。包括能夠在CARLA中執行閉環驅動的現有技術方法,用於性能比較。開源Apollo也在CARLA中作為基線進行了評估。除了我們的方法外,沒有其他基於LLM的方法顯示部署和評估的準備狀態。所有方法均在Town05長期基準上進行評估。
表4列出了駕駛分數、路線完成和違規分數。請注意,儘管Apollo是一種基於規則的方法,但它的性能幾乎與最近的端到端方法不相上下。 DriveMLM在駕駛分數上大大超過了所有其他方法。這表明DriveMLM更適合處理狀態轉換,以安全地通過硬碟。表4中的最後一列顯示了MPI評估的結果。此指標顯示了更全面的駕駛性能,因為需要代理人完成所有路線。換言之,所有路線上的所有情況都會被測試的代理商遇到。 Thinktwice實現了比Interfuser更好的DS,但由於經常越過停止線,MPI更低。然而,CARLA對這種行為的處罰卻微乎其微。相較之下,MPI將每一次違反交通規則的行為視為一次接管。 DriveMLM還實現了所有其他方法中最高的MPI,這表明它能夠避免更多情況,從而獲得更安全的駕駛體驗。
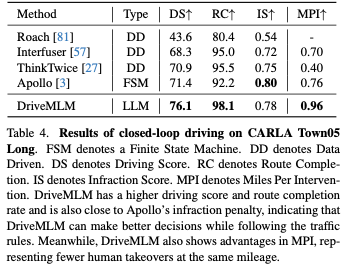
駕駛知識評測
我們採用開環評估來評估駕駛知識,包括決策預測和解釋預測任務。表3顯示了預測決策對的準確性、決策預測的每種決策類型的F1分數,以及預測解釋的BLEU-4、CIDEr和METEOR。對於Apollo,Town05上手動收集的場景將作為表3中模型的輸入進行回放。回放的每個時間戳處的相應模型狀態和輸出被保存為用於度量計算的預測。對於其他方法,我們給他們相應的圖像作為輸入和適當的提示。透過將模型預測與我們手動收集的地面實況進行比較,準確性揭示了決策的正確性和與人類行為的相似性,F1分數展示了每種路徑和速度決策的決策能力。 DriveMLM整體達到了最高的準確率,以40.97%的準確率超過了LLaVA。與Apollo基準相比,DriveMLM的F1得分更高,這表明它在解決各種道路情況時更有效地超越了基於規則的狀態機。 LLaVA、InstructionBLIP和我們提出的DriveMLM可以以問答的形式輸出決策解釋。在BLEU-4、CIDEr和METEOR方面,DriveMLM可以實現最高的效能,顯示DriveMLM能夠對決策做出最合理的解釋。
消融實驗
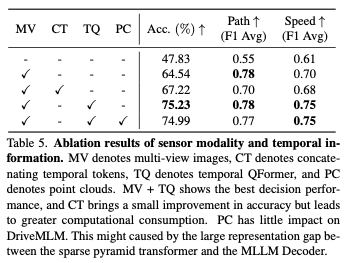
感測器模數:表5展示了輸入感測器模態對DriveMLM的不同影響的結果。多視圖(MV)影像在路徑和速度F1得分方面都帶來了顯著的效能改進,準確率提高了18.19%。與直接連接時間代幣相比,時間QFormer在確保多模態決策能力的同時,實現了7.4%的更大改進,從而使速度決策的平均F1得分提高了0.05。點雲不會顯示出增強效能的能力。
Case Study和視覺化
人機互動:圖4提供如何透過人工指令實現車輛控制的範例。控制過程包括分析道路狀況、做出決策選擇和提供解釋性陳述。當給予相同的「超車」指令時,DriveMLM會根據對目前交通狀況的分析顯示出不同的反應。在右側車道被佔用而左側車道可用的情況下,系統選擇從左側超車。然而,在給定指令可能構成危險的情況下,例如當所有車道都被佔用時,DriveMLM會選擇不執行超車動作,並做出適當反應。在這種情況下,DriveMLM是人車互動的接口,它根據交通動態評估指令的合理性,並確保其在最終選擇行動方案之前符合預先定義的規則。

真實場景中的效能:我們在nuScenes資料集上應用DriveMLM來測試開發的駕駛系統的零樣本效能。我們在驗證集上註釋了6019個幀,決策準確度的零樣本效能為0.395。圖5顯示了兩個真實駕駛場景的結果,顯示了DriveMLM的通用性。

結論
在這項工作中,我們提出了DriveMLM,這是一個利用大型語言模型(LLM)進行自動駕駛(AD)的新框架。 DriveMLM可以透過使用多模態LLM(MLLM)對模組化AD系統的行為規劃模組進行建模,在現實模擬環境中實現閉迴路AD。 DriveMLM還可以為其駕駛決策產生自然的語言解釋,這可以提高AD系統的透明度和可信度。我們已經證明,DriveMLM在CARLA Town05 Long基準上的表現優於Apollo基準。我們相信,我們的工作可以激發更多關於LLM和AD整合的研究。
開源連結:https://github.com/OpenGVLab/DriveMLM

原文連結: https://mp.weixin.qq.com/s/tQeERCbpD9H8oY8EvpZsDA
以上是全力邁向閉環! DriveMLM:將LLM與自動駕駛行為規劃完美結合!的詳細內容。更多資訊請關注PHP中文網其他相關文章!