
設定mongodb服務

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-01-03 21:41:541161瀏覽
| 導讀 | 容器正在徹底改變整個軟體生命週期:從最早的技術性實驗和概念證明,貫穿了開發、測試、部署和支援。 |
想在筆記型電腦上嘗試 MongoDB?只要執行一個指令,你就會有一個輕量級的、獨立的沙箱。完成後可以刪除你所做的所有痕跡。
想在多個環境中使用相同的程式堆疊application stack副本?建立你自己的容器鏡像,讓你的開發、測試、維運和支援團隊使用相同的環境克隆。
容器正在徹底改變整個軟體生命週期:從最早的技術性實驗和概念證明,貫穿了開發、測試、部署和支援。
編排工具用來管理如何建立、升級多個容器,並使之高可用。編排還控制容器如何連接,以從多個微服務容器建立複雜的應用程式。
豐富的功能、簡單的工具和強大的 API 使容器和編排功能成為 DevOps 團隊的首選,將其整合到連續整合(CI) 和連續交付 (CD) 的工作流程中。
這篇文章探討了在容器中執行和編排 MongoDB 時遇到的額外挑戰,並說明瞭如何克服這些挑戰。
MongoDB 的注意事項使用容器和編排來執行 MongoDB 有一些額外的注意事項:
MongoDB 資料庫節點是有狀態的。如果容器發生故障並被重新編排,資料則會遺失(能夠從副本集的其他節點恢復,但這需要時間),這是不合需要的。為了解決這個問題,可以使用諸如 Kubernetes 中的資料卷volume 抽像等功能來將容器中臨時的 MongoDB 資料目錄對應到持久位置,以便資料在容器故障和重新編排過程中存留。
一個副本集中的 MongoDB 資料庫節點必須能夠相互通訊 - 包括重新編排後。副本集中的所有節點必須知道其所有對等節點的位址,但是當重新編排容器時,可能會使用不同的 IP 位址重新啟動。例如,Kubernetes Pod 中的所有容器共用一個 IP 位址,當重新編排 pod 時,IP 位址會變更。使用 Kubernetes,可以透過將 Kubernetes 服務與每個 MongoDB 節點相關聯來處理,該節點使用 Kubernetes DNS 服務提供“主機名稱”,以保持服務在重新編排中保持不變。
一旦每個單獨的 MongoDB 節點運行(每個都在自己的容器中),則必須初始化副本集,並將每個節點新增到其中。這可能需要在編排工具之外提供一些額外的處理。具體來說,必須使用目標副本集中的一個 MongoDB 節點來執行 rs.initiate 和 rs.add 指令。
如果編排框架提供了容器的自動化重新編排(如 Kubernetes),那麼這將增加 MongoDB 的彈性,因為這可以自動重新建立失敗的副本集成員,從而在沒有人為幹預的情況下恢復完全的冗餘等級。
應該注意的是,雖然編排框架可能監控容器的狀態,但是不太可能監視容器內運行的應用程式或備份其資料。這意味著使用 MongoDB Enterprise Advanced 和 MongoDB Professional 中包含的 MongoDB Cloud Manager 等強大的監控和備份解決方案非常重要。可以考慮建立自己的鏡像,其中包含你首選的 MongoDB 版本和 MongoDB Automation Agent。
如上節所述,分散式資料庫(如 MongoDB)在使用編排框架(如 Kubernetes)進行部署時,需要稍加註意。本節將介紹詳細介紹如何實現。
我們首先在單一 Kubernetes 叢集中建立整個 MongoDB 副本集(通常在一個資料中心內,這顯然不能提供地理冗餘)。實際上,很少有必要改變成跨多個叢集運行,這些步驟將在後面描述。
副本集的每個成員將作為自己的 pod 運行,並提供一個公開 IP 位址和連接埠的服務。這個「固定」的 IP 位址非常重要,因為外部應用程式和其他副本集成員都可以依賴它在重新編排 pod 的情況下保持不變。
下圖說明了其中一個 pod 以及相關的複製控制器和服務。
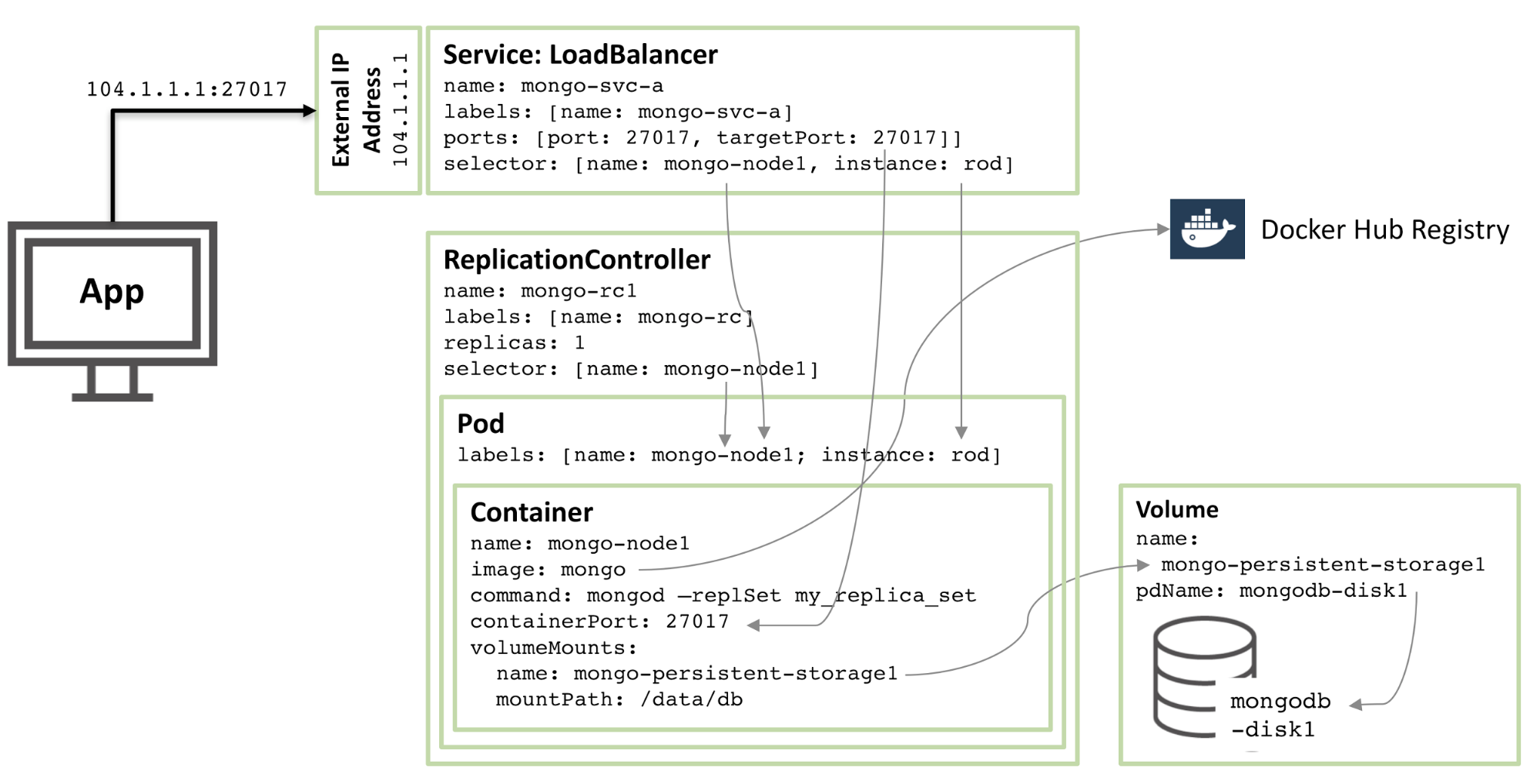
#圖 1:MongoDB 副本集成員被配置為 Kubernetes Pod 並作為服務公開
圖 1:MongoDB 副本集成員被配置為 Kubernetes Pod 並作為服務公開
逐步介紹該配置中所述的資源:
從核心開始,有一個名為 mongo-node1 的容器。 mongo-node1 包含一個名為 mongo 的映像,這是一個在 Docker Hub 上託管的一個公開可用的 MongoDB 容器映像。容器在叢集中暴露連接埠 27107。
Kubernetes 的資料磁碟區功能用於將連接器中的/data/db 目錄對應到名為mongo-persistent-storage1 的永久儲存上,這又被對應到在Google Cloud 中建立的名為mongodb-disk1 的磁碟中。這是 MongoDB 儲存其資料的地方,這樣它可以在容器重新編排後保留。
容器保存在一個 pod 中,該 pod 中有標籤命名為 mongo-node,並提供一個名為 rod 的(任意)範例。
配置 mongo-node1 複製控制器以確保 mongo-node1 pod 的單一實例始終運作。
名為 mongo-svc-a 的 負載平衡 服務給外部開放了一個 IP 位址以及 27017 端口,它被映射到容器相同的端口號。此服務使用選擇器來匹配 pod 標籤來確定正確的 pod。外部 IP 位址和連接埠將用於應用程式以及副本集成員之間的通訊。每個容器也有本機 IP 位址,但是當容器移動或重新啟動時,這些 IP 位址會變化,因此不會用於副本集。
下一個圖顯示了副本集的第二個成員的配置。
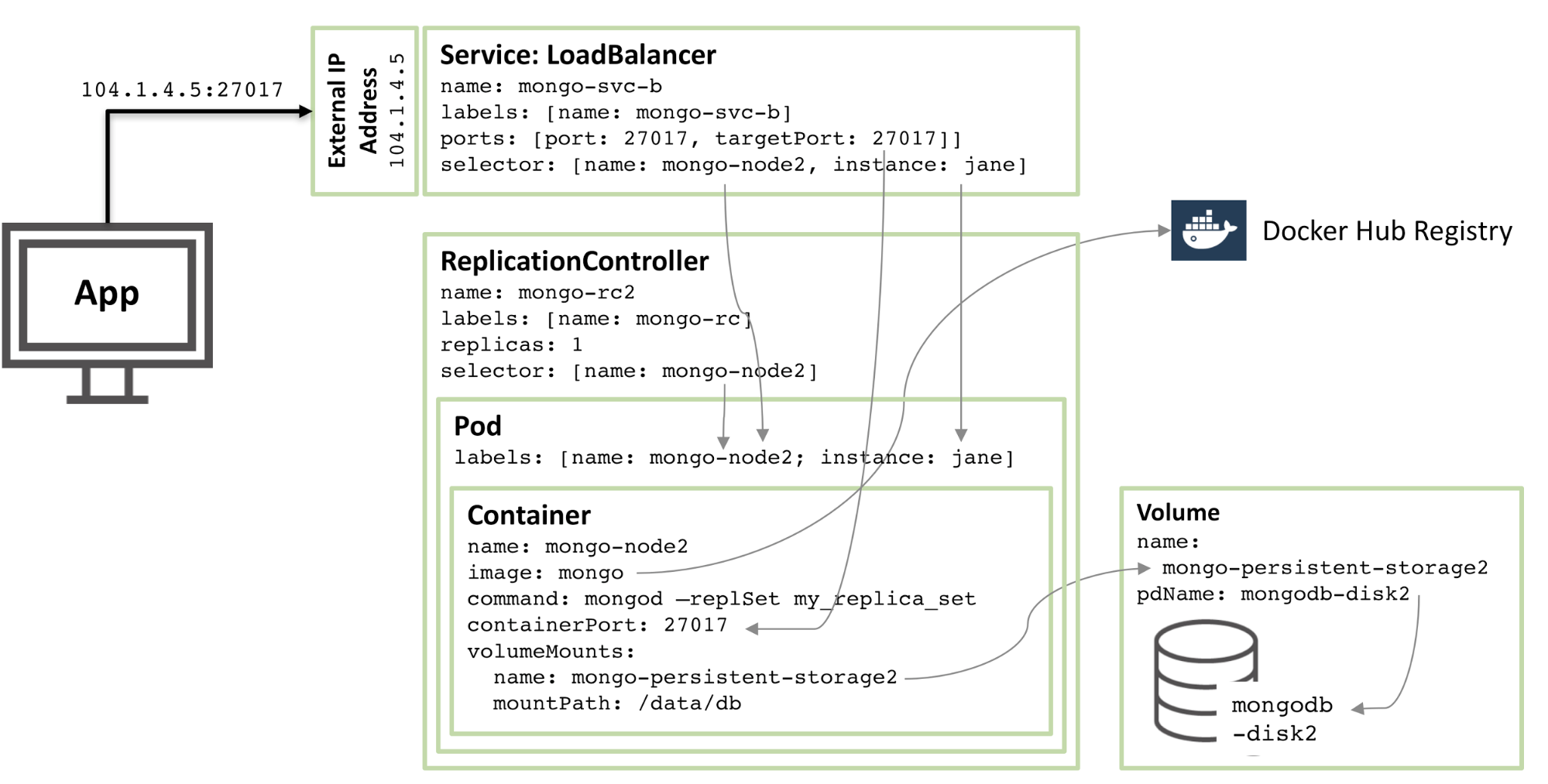
#圖 2:第二個 MongoDB 副本集成員配置為 Kubernetes Pod
圖 2:第二個 MongoDB 副本集成員配置為 Kubernetes Pod
#
90% 的配置是一樣的,只有這些變化:
磁碟和磁碟區名稱必須是唯一的,因此使用的是 mongodb-disk2 和 mongo-persistent-storage2
Pod 被指派了一個 instance: jane 和 name: mongo-node2 的標籤,以便新的服務可以使用選擇器與圖 1 所示的 rod Pod 相區分。
複製控制器命名為 mongo-rc2
該服務名為mongo-svc-b,並獲得了一個唯一的外部 IP 位址(在這種情況下,Kubernetes 分配了 104.1.4.5)
第三個副本成員的配置遵循相同的模式,下圖展示了完整的副本集:
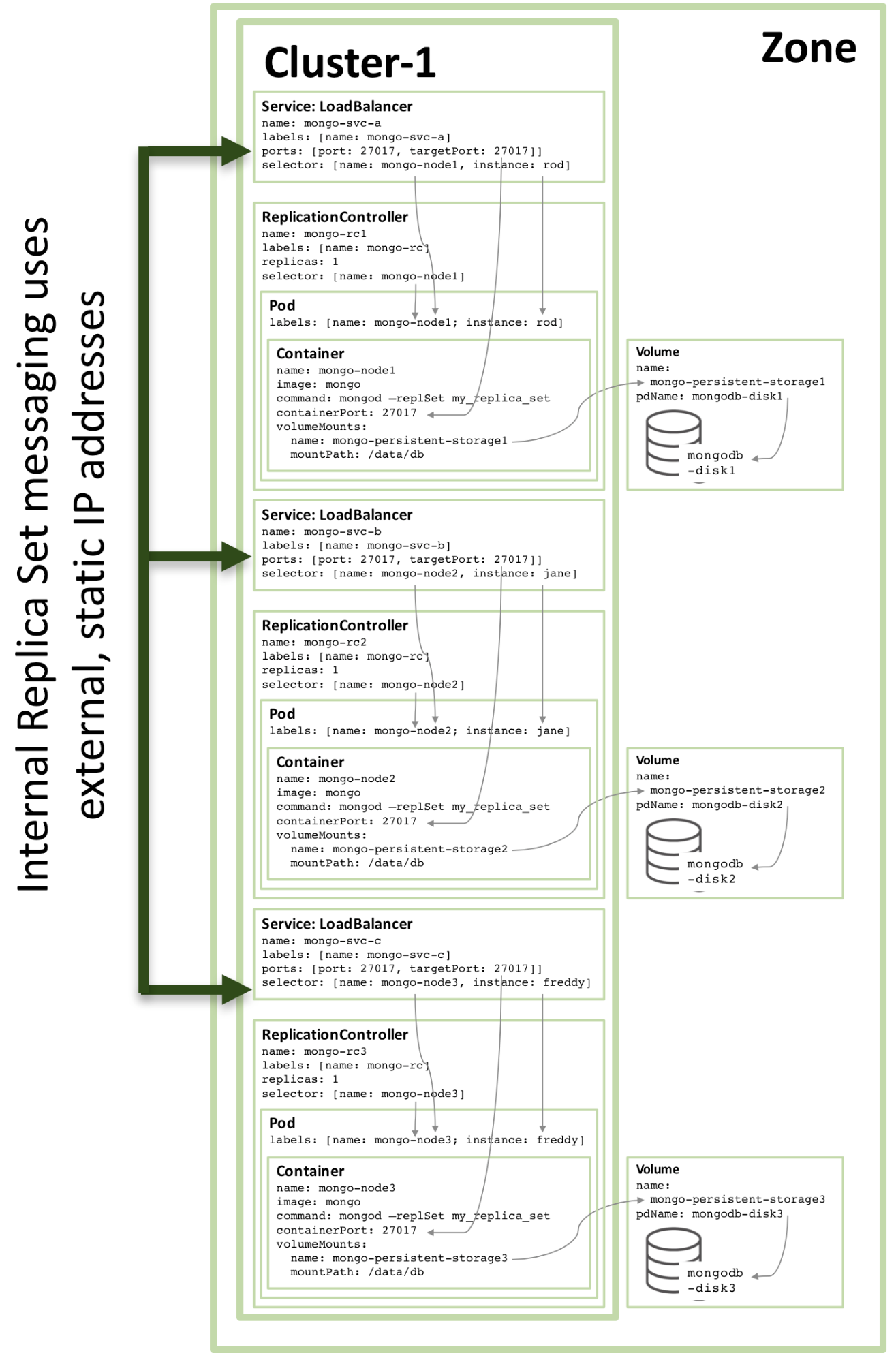
#圖 3:配置為 Kubernetes 服務的完整副本集成員
圖 3:配置為 Kubernetes 服務的完整副本集成員
請注意,即使在三個或更多節點的 Kubernetes 叢集上執行圖 3 所示的配置,Kubernetes 可能(並且經常會)在同一主機上編排兩個或多個 MongoDB 副本集成員。這是因為 Kubernetes 將三個 pod 視為屬於三個獨立的服務。
為了在區域內增加冗餘,可以建立一個附加的 headless 服務。新服務不會提供外界任何功能(甚至不會有 IP 位址),但它可以讓 Kubernetes 通知三個 MongoDB pod 形成一個服務,所以 Kubernetes 會嘗試在不同的節點上編排它們。
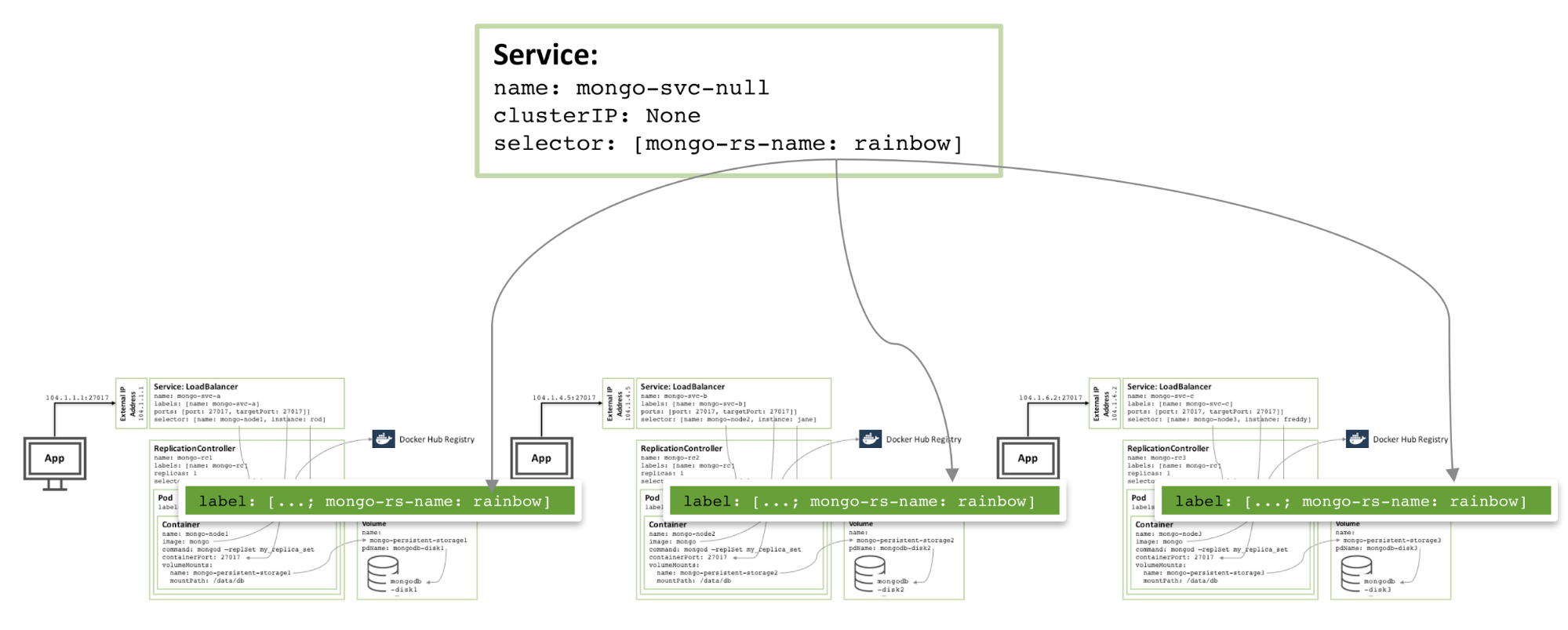
#圖 4:避免相同 MongoDB 副本集成員的 Headless 服務
圖 4:避免同一 MongoDB 副本集成員的 Headless 服務
設定和啟動 MongoDB 副本集所需的實際設定檔和指令可以在白皮書《啟用微服務:闡述容器與編排》中找到。特別是,需要一些本文中描述的特殊步驟來將三個 MongoDB 實例組合成具備功能的、健壯的副本集。
上面建立的副本集存在風險,因為所有內容都在相同的 GCE 叢集中運行,因此都在相同的可用區availability zone中。如果有一個重大事件使可用區離線,那麼 MongoDB 副本集將不可用。如果需要地理冗餘,則三個 pod 應該在三個不同的可用區或地區中運行。
令人驚訝的是,為了創建在三個區域之間分割的類似的副本集(需要三個群集),幾乎不需要改變。每個叢集都需要自己的 Kubernetes YAML 文件,該文件僅為該副本集中的一個成員定義了 pod、複製控制器和服務。那麼為每個區域建立一個集群,永久儲存和 MongoDB 節點是一件很簡單的事情。
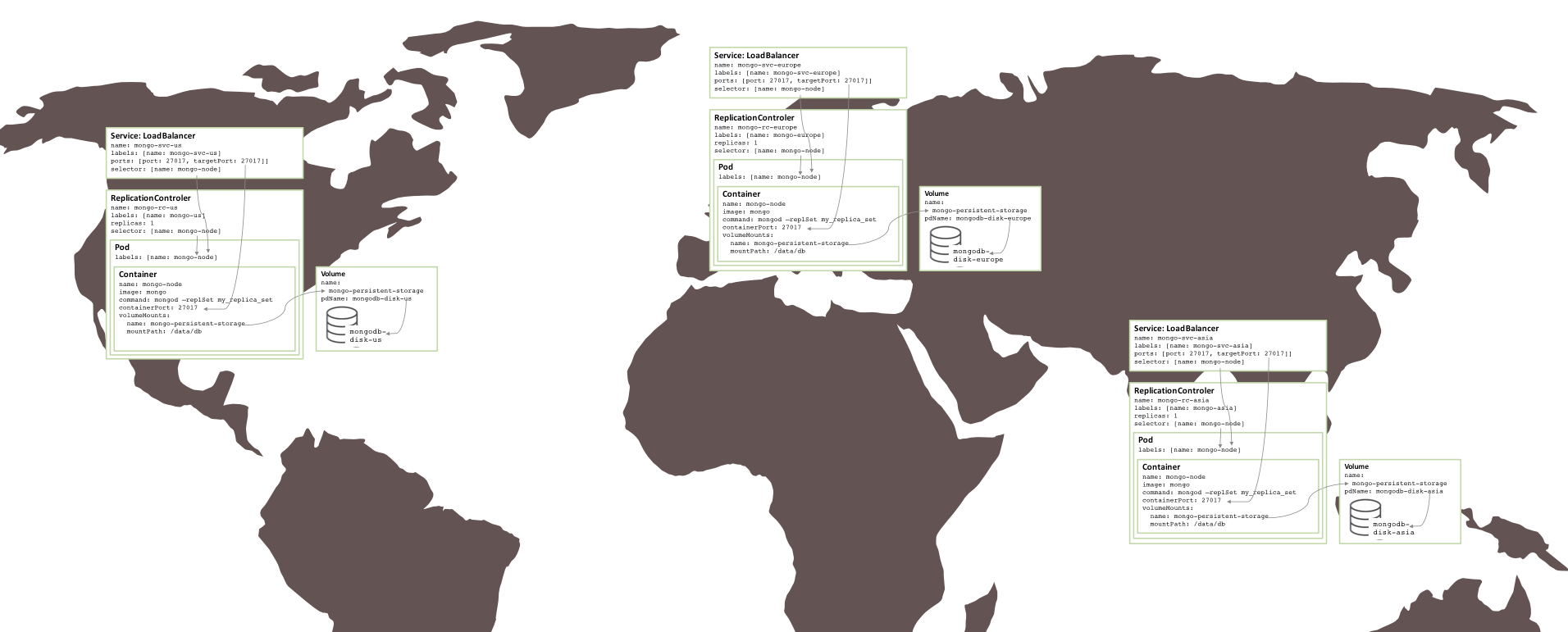
#圖 5:在多個可用區域上執行的副本集
圖 5:在多個可用區域上執行的副本集
下一步
要了解更多關於容器和編排的資訊 - 所涉及的技術和所提供的業務優勢 - 請閱讀白皮書《啟用微服務:闡述容器和編排》。該文件提供了本文中描述的副本集,並在 Google Container Engine 中的 Docker 和 Kubernetes 上運行的完整的說明。
作者簡介:
Andrew 是 MongoDB 的產品行銷總經理。他在去年夏天離開 Oracle 加入 MongoDB,在 Oracle 他花了 6 年多的時間在產品管理上,專注於高可用性。他可以透過 @andrewmorgan 或在他的部落格(clusterdb.com)評論聯繫他。
以上是設定mongodb服務的詳細內容。更多資訊請關注PHP中文網其他相關文章!