
4090生成器:與A100平台相比,token生成速度僅低於18%,上交推理引擎贏得熱議

- 王林轉載
- 2023-12-21 15:25:412001瀏覽
PowerInfer 提高了在消費級硬體上運行AI 的效率
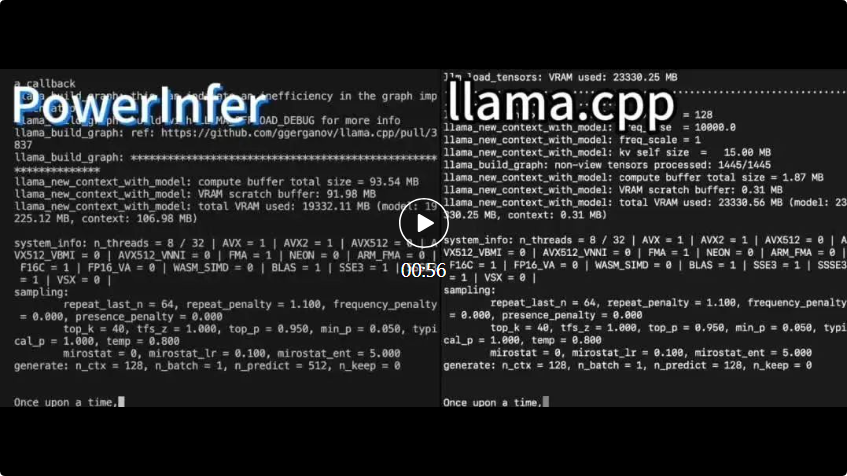 PowerInfer 與 llama.cpp 上運作相同的硬體上運作並為 RTX 上運作的硬體上。
PowerInfer 與 llama.cpp 上運作相同的硬體上運作並為 RTX 上運作的硬體上。 PowerInfer 與本地的先進的LLM推理框架llama.cpp相比,在單一RTX 4090(24G)上執行Falcon(ReLU)-40B-FP16模型,不僅實現了超過11倍的加速,而且還能保持模型的準確性
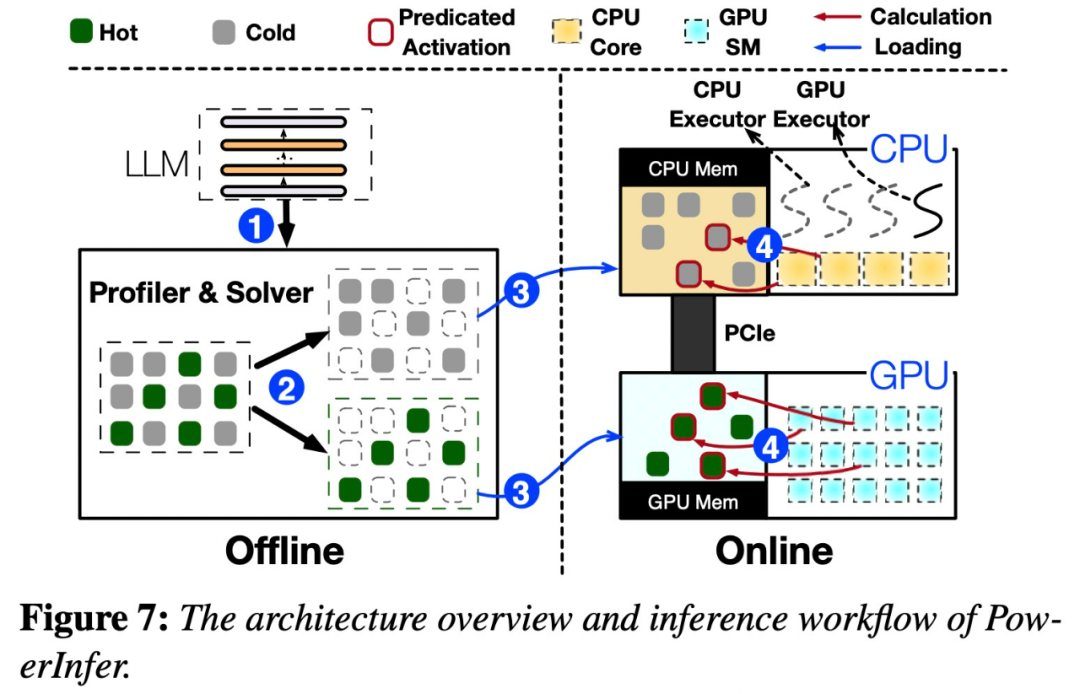
PowerInfer是一個專門用於本地部署LLM的高速推理引擎。與多專家系統(MoE)不同,PowerInfer巧妙地設計了一款GPU-CPU混合推理引擎,充分利用了LLM推理的高度局部性
將頻繁激活的神經元(即熱激活)預加載到GPU上以便快速訪問,而不經常激活的神經元(即冷激活)則在CPU上進行計算。這是它的工作原理
這種方法能夠顯著降低GPU記憶體的需求與CPU與GPU之間的資料傳輸量

-
專案連結:https://github.com/SJTU-IPADS/PowerInfer
#論文連結:https://ipads.se.sjtu.edu.cn/_media/ publications/powerinfer-20231219.pdf
PowerInfer 可以在配備單一消費級GPU 的PC 上高速運行LLM。現在使用者可以將 PowerInfer 與 Llama 2 和 Faclon 40B 結合使用,對 Mistral-7B 的支援也即將推出。
在一天的時間裡,PowerInfer就成功獲得了2K個星標
在看到這項研究之後,網友們表示非常激動:現在單卡4090 可以跑175B 的大模型,不再只是一個夢想了
PowerInfer 架構
##PowerInfer 設計的關鍵是利用LLM 推理中固有的高度局部性,其特徵是神經元活化中的冪律分佈。這種分佈表明,一小部分神經元(稱為熱神經元)跨輸入一致激活,而大多數冷神經元則根據特定輸入而變化。 PowerInfer 利用這個機制設計了 GPU-CPU 混合推理引擎。
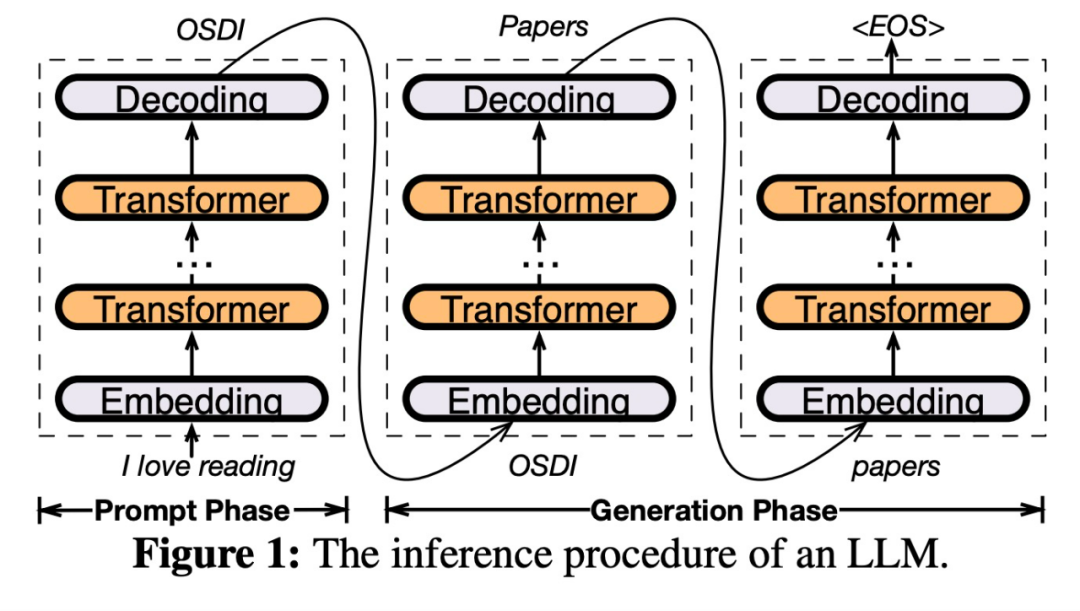
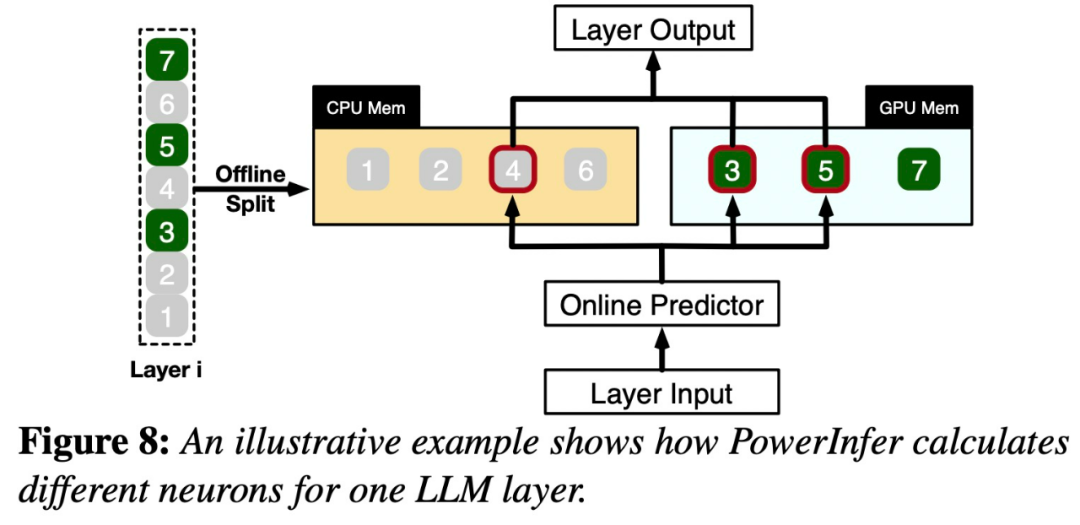
一旦接收到輸入,預測器將會辨識目前層中可能會被啟動的神經元。需要注意的是,透過離線統計分析識別的熱激活神經元可能與實際運行時的活化行為不一致。例如,雖然神經元7被標記為熱激活,但實際上並非如此。然後,CPU和GPU會處理那些已經啟動的神經元,而忽略那些未被啟動的神經元。 GPU負責運算神經元3和5,而CPU處理神經元4。當神經元4的計算完成後,其輸出將被傳送到GPU進行結果整合
#為了重新編寫內容而不改變原意,需要將語言重新編寫成中文。沒有必要出現原始句子
該研究使用不同參數的 OPT 模型進行了為了重新編寫內容而不改變原意,需要將語言重新編寫成中文。沒有必要出現原始句子,參數從 6.7B 到 175B 不等,還包括 Falcon (ReLU)-40B 和 LLaMA (ReGLU)-70B 模型。值得注意的是,175B 參數模型的大小與 GPT-3 模型相當。
本文也對PowerInfer進行了與llama.cpp的比較,llama.cpp是最先進的本地LLM推理框架。為了方便比較,本研究還擴展了llama.cpp以支援OPT模型
考慮到本文的重點是低延遲設置,因此評估指標採用了端到端生成速度,以每秒生成的token 數量(tokens/s)進行量化
這項研究首先比較了PowerInfer和llama.cpp在批次大小為1的情況下的端到端推理性能
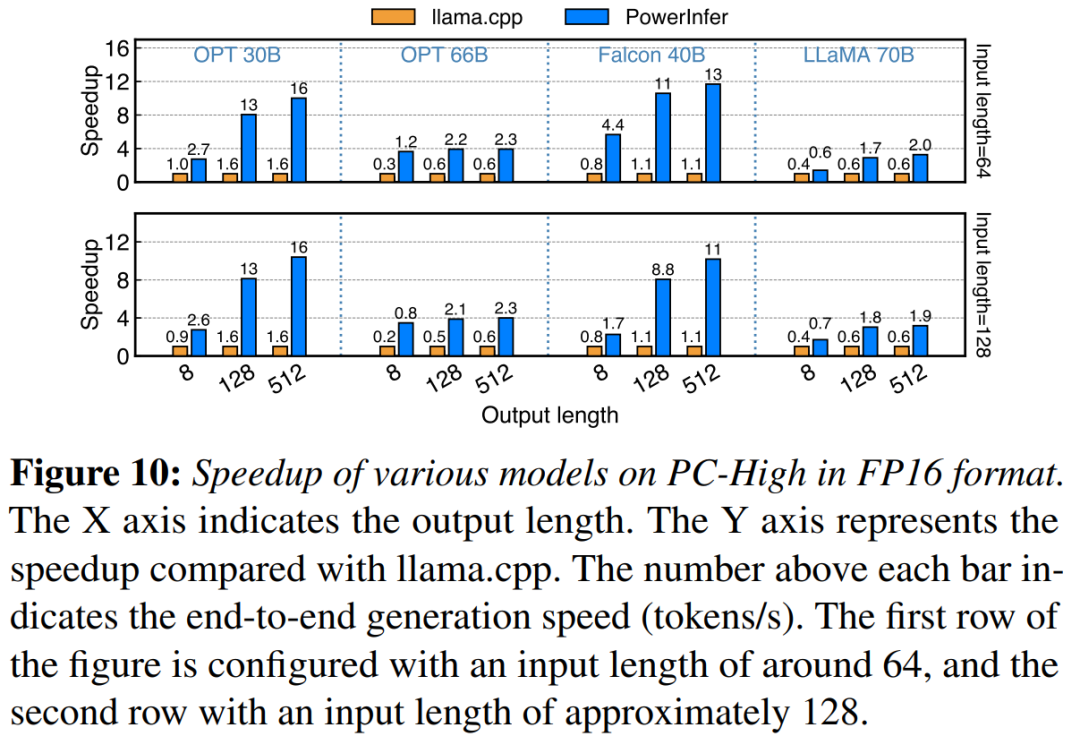
在配備NVIDIA RTX 4090 的PC-High 上,圖10 展示了各種模型和輸入輸出配置的產生速度。平均而言,PowerInfer 實現了8.32 tokens/s 的生成速度,最高可達16.06 tokens/s,明顯優於llama.cpp,比llama.cpp 提高了7.23倍,比Falcon-40B 提高了11.69倍
隨著輸出token 數量的增加,PowerInfer 的效能優勢變得更加明顯,因為生成階段在整體推理時間中扮演更重要的角色。在這個階段,CPU 和 GPU 上都會啟動少量神經元,相較於llama.cpp,減少了不必要的運算。例如,在OPT-30B的情況下,每生成一個token,只有大約20%的神經元被激活,其中大部分在GPU上處理,這是PowerInfer神經元感知推理的好處
#在圖11中顯示,儘管在PC-Low上,PowerInfer仍然獲得了相當大的性能增強,平均加速達到5.01倍,峰值加速達到7.06倍。然而,與PC-High相比,這些改進較小,主要是由於PC-Low的11GB GPU記憶體限制所致。這個限制會影響可以分配給GPU的神經元數量,尤其是對於具有大約30B參數或更多參數的模型,導致更多地依賴CPU來處理大量激活的神經元
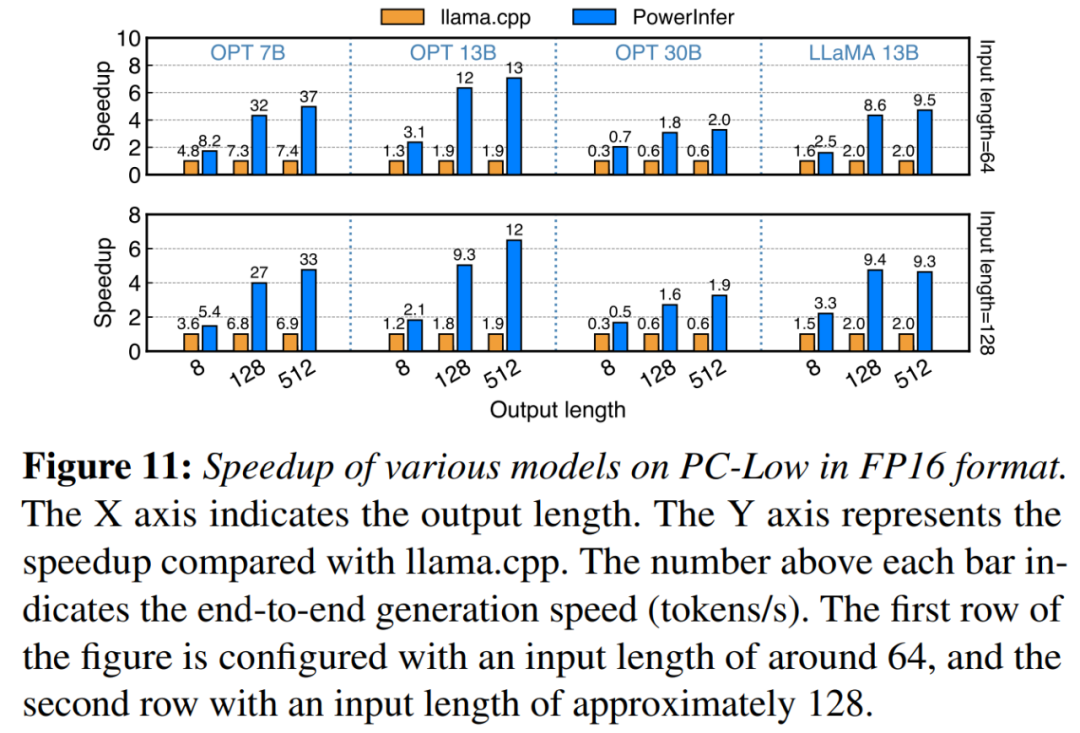
圖12展示了PowerInfer和llama.cpp之間的CPU和GPU之間的神經元負載分佈。值得注意的是,在PC-High上,PowerInfer顯著增加了GPU的神經元負載份額,從平均20%增加到了70%。這顯示GPU處理了70%的活化神經元。然而,在模型的記憶體需求遠超過GPU容量的情況下,例如在11GB 2080Ti GPU上運行60GB模型,GPU的神經元負載會降低至42%。這種下降是由於GPU的記憶體有限,不足以容納所有啟動的神經元,因此需要CPU計算其中的部分神經元

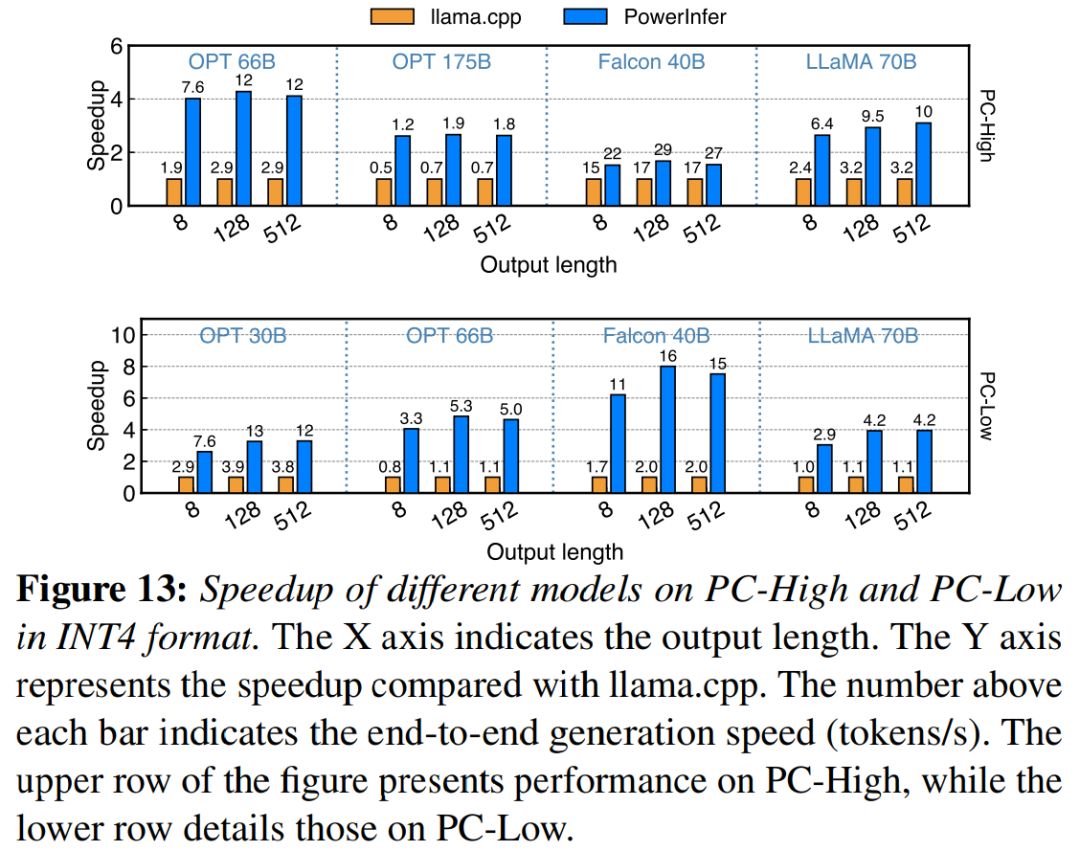
圖13 說明PowerInfer 有效支援使用INT4 量化壓縮的LLM。在 PC-High 上,PowerInfer 的平均反應速度為 13.20 tokens/s,峰值可達 29.08 tokens/s。與 llama.cpp 相比,平均加速 2.89 倍,最大加速 4.28 倍。在 PC-Low 上,平均加速為 5.01 倍,峰值為 8.00 倍。由於量化而減少的記憶體需求使 PowerInfer 能夠更有效地管理更大的模型。例如,在 PC-High 上使用 OPT-175B 模型進行的為了重新編寫內容而不改變原意,需要將語言重新編寫成中文。沒有必要出現原始句子中,PowerInfer 幾乎達到每秒兩個 token,超過 llama.cpp 2.66 倍。
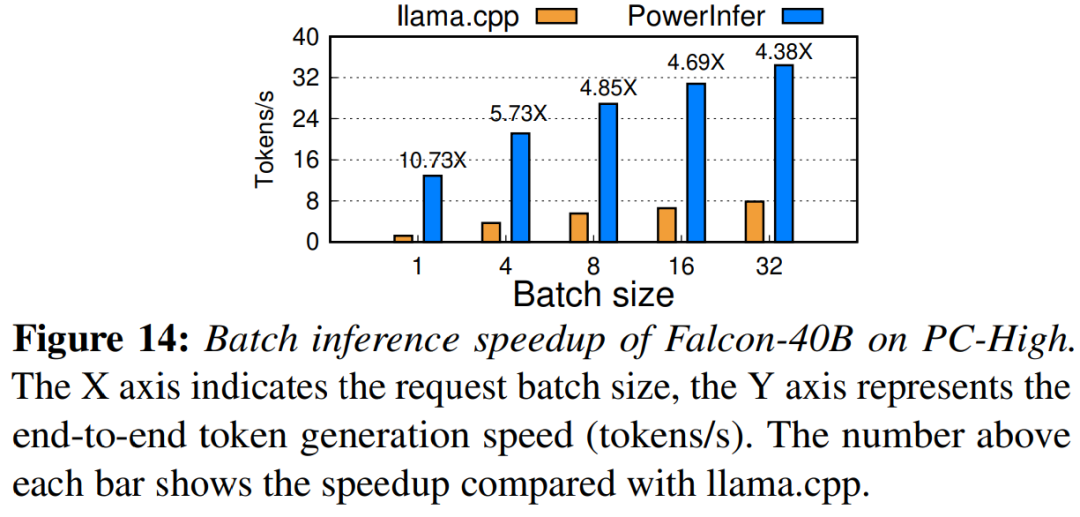
最终,该研究还评估了PowerInfer在不同批大小下的端到端推理性能。如图14所示,当批大小小于32时,PowerInfer表现出显著的优势,与llama相比,性能平均提高了6.08倍。随着批大小的增加,PowerInfer提供的加速比会降低。然而,即使批大小设置为32,PowerInfer仍然保持了相当大的加速
参考链接:https://weibo.com/1727858283/NxZ0Ttdnz
请查看原论文以了解更多内容
以上是4090生成器:與A100平台相比,token生成速度僅低於18%,上交推理引擎贏得熱議的詳細內容。更多資訊請關注PHP中文網其他相關文章!